

陈丹琦有了个公司邮箱,北大翁荔同款
陈丹琦有了个公司邮箱,北大翁荔同款又一个AI学术大佬,有工业界身份了。 清华姚班校友、普林斯顿教授陈丹琦,跟Thinking Machines划上了关联。
来自主题:
AI资讯
9519 点击 2025-08-29 12:52
 搜索
搜索
又一个AI学术大佬,有工业界身份了。 清华姚班校友、普林斯顿教授陈丹琦,跟Thinking Machines划上了关联。

OpenAI的重组悬而未决,核心在控制权与确定性:多云是否松口、微软能否获取训练细节、以及最关键的AGI条款的去留。这三件事,决定了微软最终30%–35%的持股价值,也决定了软银100亿美元的到账节奏与估值锚点。

短短两天,寒武纪两度超越贵州茅台,成为 A 股第一高价「股王」。而推动用户预期不断攀升的,离不开 AI 市场的持续火热。
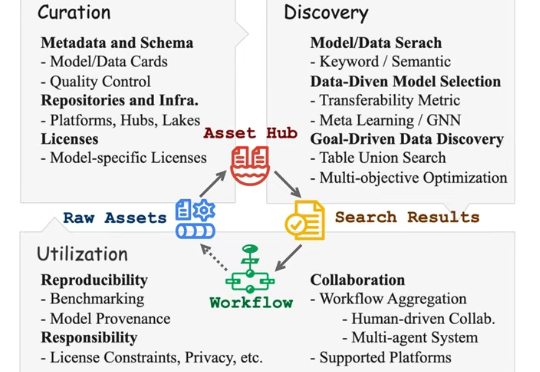
在大模型时代,机器学习资产(如模型、数据和许可证)数量激增,但大多缺乏规范管理,严重阻碍了AI应用效率。研究人员将在VLDB 2025系统介绍如何整理、发现和利用这些资产,使其更易查找、复用且符合规范,从而提升开发效率与协作质量。

小扎挖人如探囊取物,留人却像竹篮打水。 随着这场AI人才争夺战进入白热化,大模型公司员工们的薪酬差距也在不断扩大。

近日,新西兰林肯大学(Lincoln University)的一门课程引发争议:因怀疑部分学生在作业中使用了生成式 AI 工具,任课教师决定让全班 100 多名学生重新接受线下考核。
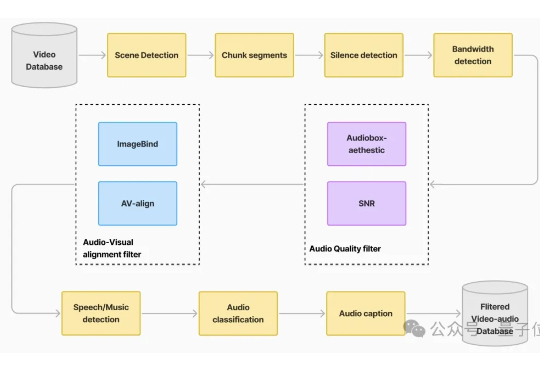
自带声音的视频生成模型,开源版开卷! 最新赶到的是腾讯混元:刚刚正式开源端到端的视频音效生成模型HunyuanVideo-Foley。
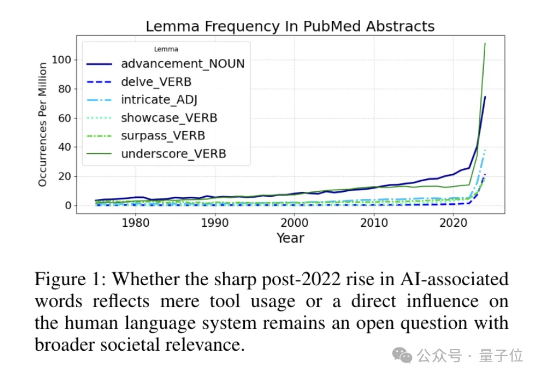
和AI聊了两年多,人类说话ChatGPT味越来越重了? 最新研究结果显示,还真是。
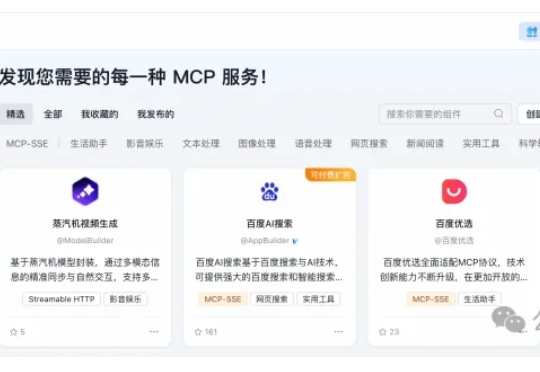
“Agent元年”进程过半,Agent虽已从处理简单任务转向复杂交付,却仍卡在“信息断层”的关键瓶颈—— 受限于训练数据截止日期,难以及时获取实时动态信息,企业级场景落地始终差临门一脚。
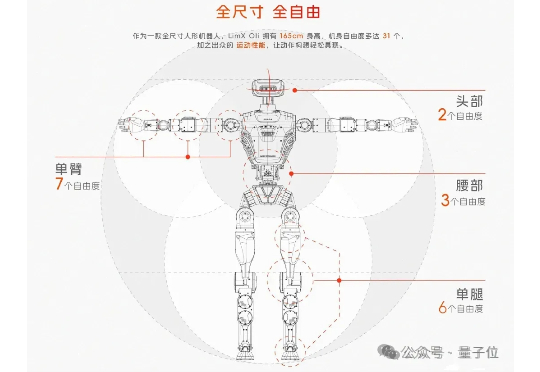
“让天下没有难落地的机器人。” 在这样解释定位和使命后,量子位大概感受到了逐际动力被投资的原因—— 至少是成为阿里第一个具身智能投资项目的原因。
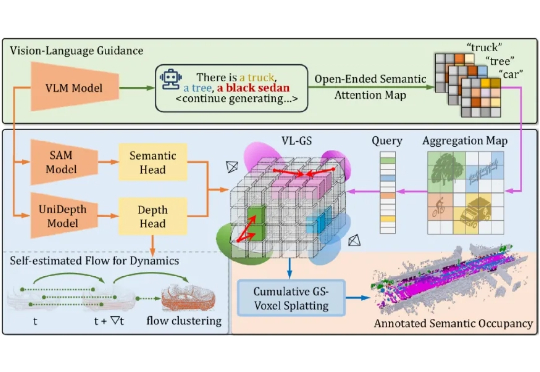
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。

“从来没有想过自己会超出deepseek的最大限度,此刻我仿佛失去了一个很好的朋友。” 今年3月,momo在小红书记录下自己的心情。在花了很长时间与AI对话,终于调试到一个舒服的老友状态后,她与AI的对话框达到了极限。系统提示她开启新一轮的对话,但新窗口的AI已经不是她所熟悉的“电子朋友”。

玩家怀疑PVP游戏公司通过算法操纵匹配机制控制胜率以维持50%胜率,延长玩家留存。王者荣耀诉讼案揭露玩家策略如"鸡爪流"可操控系统匹配,官方引入AI假扮玩家平衡情绪。现象扩展至坦克世界等多款游戏,AI技术进步或使真伪难辨,引发对真实挑战与定制胜利的反思。
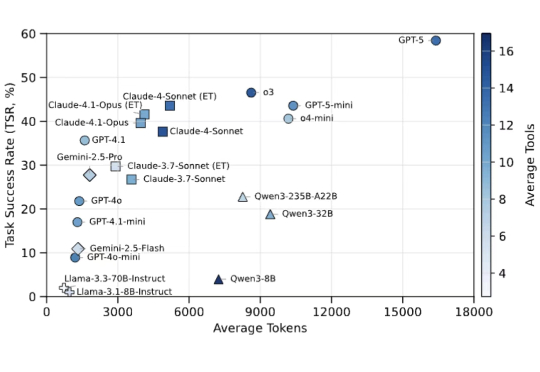
杜克大学与 Zoom 的研究者们推出了 LiveMCP-101,这是首个专门针对真实动态环境设计的 MCP-enabled Agent 评测基准。该基准包含 101 个精心设计的任务,涵盖旅行规划,体育娱乐,软件工程等多种不同场景,要求 Agent 在多步骤、多工具协同的场景下完成任务。

就在刚刚,也许是目前最强的开源蛋白质结合剂AI设计工具,登上Nature。瑞士洛桑联邦理工学院、美国麻省理工学院等研究人员在Nature上发表了题为One-shot design of functional protein binders with BindCraft的论文。

今天,AI 行业发展更进一步,将“光”引入 AIGC 领域,完全基于系统硬件物理定律,首次实现了具备特定特征的全新(未见过的)图像生成。来自加州大学洛杉矶分校的研究团队成功实现了手写数字、时尚产品、蝴蝶、人脸及艺术品(如梵高风格)的单色与多色图像光学生成,且整体性能媲美基于数字神经网络的生成式模型。

美国当地时间周二,由三位斯坦福经济学家联合发布、尚未经过同行评议的最新研究显示:自2022年11月ChatGPT上线以来,生成式AI已在“可高度自动化”的岗位上显著压低年轻美国人的就业率。

刚刚,马斯克xAI加入Coding战局:推出智能编程模型Grok Code Fast 1。Fast写进名字里,新模型主打的就是快速、经济,且支持256K上下文,可在GitHub Copilot、Cursor、Cline、Kilo Code、Roo Code、opencode和Windsurf上使用,还限时7天免费!

OpenAI和Anthropic罕见合作!因为AI安全「分手」后,这次双方却因为安全合作:测试双方模型在幻觉等四大安全方面的具体表现。这场合作,不仅是技术碰撞,更是AI安全的里程碑,百万用户每天的互动,正推动安全边界不断扩展。

做销售的朋友大概都有过这样的经历:跟进客户时要在邮箱、微信、Excel 间反复切换,好不容易把信息汇总到 CRM 系统,却发现格式不对要重新调整。这种 "人围着系统转" 的困境,正在被一家叫 Attio 的初创公司改写。

智东西8月26日报道,近日,谷歌母公司Alphabet风投部门CapitalG、英伟达正在洽谈投资以色列AI基础设施提供商VAST Data,融资金额或达到数十亿美元,或将成为以色列科技公司史上最大规模融资。融资完成,这家创企的估值将跃升至300亿美元(折合人民币约2148亿元)。

如果对我有印象的老粉丝,可能还会记得我之前写过一篇关于医生借助AI筛查胰腺癌,在半年里,救了6条活生生的人命的故事。

a16z最新发布「全球Top100消费级GenAI应用榜单」,AI竞争格局逐渐稳定,中国力量全面崛起,DeepSeek、豆包、夸克等多款产品跻身前十。ChatGPT依旧领跑,谷歌Gemini紧随其后,Grok高速逆袭。整体来看,全球AI正进入多极化竞争的新阶段。
陈丹琦加入 Thinking Machines Lab 了?这一猜测不是毫无根据,当我们打开她的 GitHub 主页,邮箱已经变为 thinkingmachines.ai。
大模型爆发以来,围绕AI陪伴、AI教育、AI玩具等领域的创业一茬接一茬。但对于什么是合适的硬件形态、交互模态,市场还未有一个PMF的成功样板。

近日,Physical AI 公司极佳视界宣布完成Pre-A&Pre-A+连续两轮数亿元融资。Pre-A 轮融资由国中资本领投,紫峰资本、老股东 PKSHA Algorithm Fund跟投;Pre-A+ 轮融资由中金资本、广州产投、一村淞灵、华强资本投资。

智东西8月27日消息,据外媒The Information报道,苹果高管曾在内部讨论收购生成式AI搜索独角兽Perplexity、欧洲大模型独角兽Mistral的可能性,但目前尚无定论。
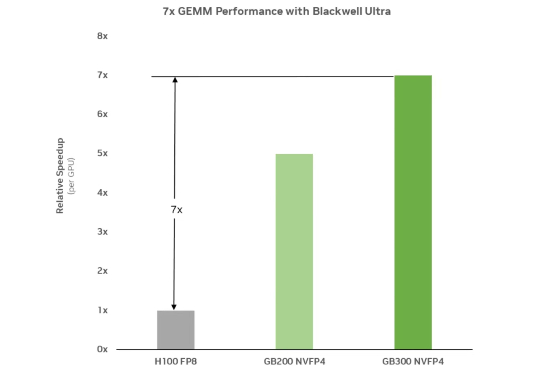
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。

一切皆可用上 AI,包括浏览器本身。 今天,AI 大模型公司 Anthropic 发布了一则最新公告——《Chrome 版 Claude 试运行》。简而言之,他们给 Chrome 浏览器开发了一款插件,让 Claude 这个大模型可以帮人自动操作网页。

传统 video dubbing 技术长期受限于其固有的 “口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。

