


机器人世界模型,TeleAI用少量数据完成训练 | NeurIPS 2024
机器人世界模型,TeleAI用少量数据完成训练 | NeurIPS 2024TeleAI 李学龙团队提出具身世界模型,挖掘大量人类操作视频和少量机器人数据的共同决策模式。
来自主题:
AI技术研报
5409 点击 2024-10-16 14:31
 搜索
搜索
TeleAI 李学龙团队提出具身世界模型,挖掘大量人类操作视频和少量机器人数据的共同决策模式。

AI对待每个人类都一视同仁吗? 现在OpenAI用53页的新论文揭示:ChatGPT真的会看人下菜碟。 根据用户的名字就自动推断出性别、种族等身份特征,并重复训练数据中的社会偏见。

国产大模型首次在公开榜单上超过GPT-4o! 就在刚刚,“大模型六小强”之一的零一万物正式对外发布新旗舰模型——Yi-Lightning(闪电)。

李飞飞表示,我们都需要了解空间智能来完成虚拟和现实世界中的许多关键任务,而基础技术是空间智能。人工智能的发展需要以人为本的技术框架来确保人工智能造福人类。

在本期专访中,我们特别邀请了郭振宇博士,一位在AI与自动化领域中兼具学术深度与创业敏锐度的佼佼者。

按照传统,FDA会每年秋季都会更新一次人工智能数据库,目前,FDA数据库中共有950个设备。 截至2024年10月,还没有任何使用生成式人工智能或由大型语言模型驱动的设备获批。

都说AI视频王座轮流坐,我怎么发现,坐着坐着,只剩我们的产品了。 我这两天,打开X上,那些关注的那些博主,话里话外,哪哪都是那个单词: Hailuo。
2020 年初,新冠病毒的阴影迅速笼罩全球。在这场与时间的赛跑中,我们见证了无数英勇的个体和团队挺身而出,社会体系经历了一次次严峻考验,也为全球的公共卫生领域敲响了警钟。

男性用户也有属于自己的3D版“赛博女友”了? 2024年《恋与深空》的问世带领国产乙游进入3D时代,女性用户的“男友”从2D纸片人进化成了3D建模,这一创新致使《恋与深空》开服10个月依然稳坐乙游赛道TOP1,流水一度超过《王者荣耀》登顶iOS畅销榜,真实感更强的3D建模无疑成为了恋爱陪伴赛道的“当红炸子鸡”。

杭州君同未来科技有限责任公司(以下简称「君同未来」)于近日完成数千万元天使轮融资。本轮融资由德联资本、领汇创投等联合投资,航行资本担任独家财务顾问。

材料正成为AI4S下一个要攻占的阵地。2024年诺贝尔化学奖的颁布,让一群国内的AI创业者和从业者兴奋不已。

这届网友在“中东卷饼”店赛博兼职 当国产超休闲小游戏从短视频病毒传播到出海战术屡试不爽之际,“中东肉夹馍”已然通过小游戏实现了“文化入侵”。

AI人才大震荡!17位高管“解雇”CEO,一场轰动科技圈的换将门

AIoT正驱动数字革命进入新的境界!多元化的AIoT连接技术正在加速渗透;生成式AI和边缘智能成为关注焦点;物联网安全的重要性得到重视。

AI大模型风头虽盛,在资本推波助澜下,使得融资一轮高过一轮,这种投机行为也助推AI大模型独角兽存在巨大泡沫成份。

Agent或许是打开短剧的“钥匙” 两个百度高优先级的项目,短剧与Agent终于在十月碰撞出了火花。

虚幻引擎5加持。具身智能被视为当前人工智能(AI)领域最具潜力的方向之一,重点关注智能体感知、学习和与环境动态交互的能力。

未来,社交巨头地位能否被撼动,谁又在抢筑护城河? 近日,LoveyDovey、 SocialAI等多款海外AI社交应用走红,让不少网友跟风效仿与虚拟角色互动。
具有强大泛化能力

微软 10 年「老兵」选择离开。

AI 手机的形态,再次进化了。

在自然语言处理、语音识别和时间序列分析等众多领域中,序列建模是一项至关重要的任务。然而,现有的模型在捕捉长程依赖关系和高效建模序列方面仍面临诸多挑战。
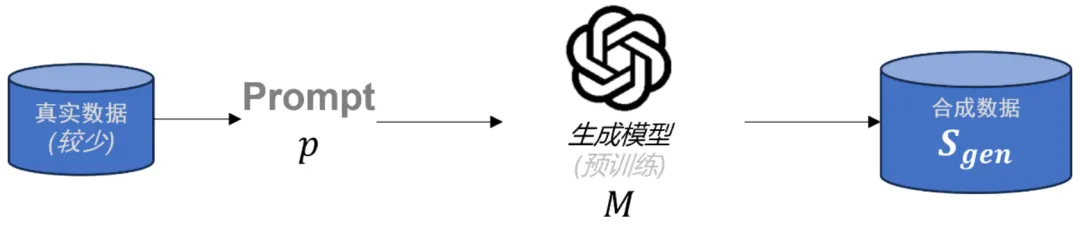
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

2023年的这时候,很多人都在讲,所有的产品都值得用AI再做一遍。
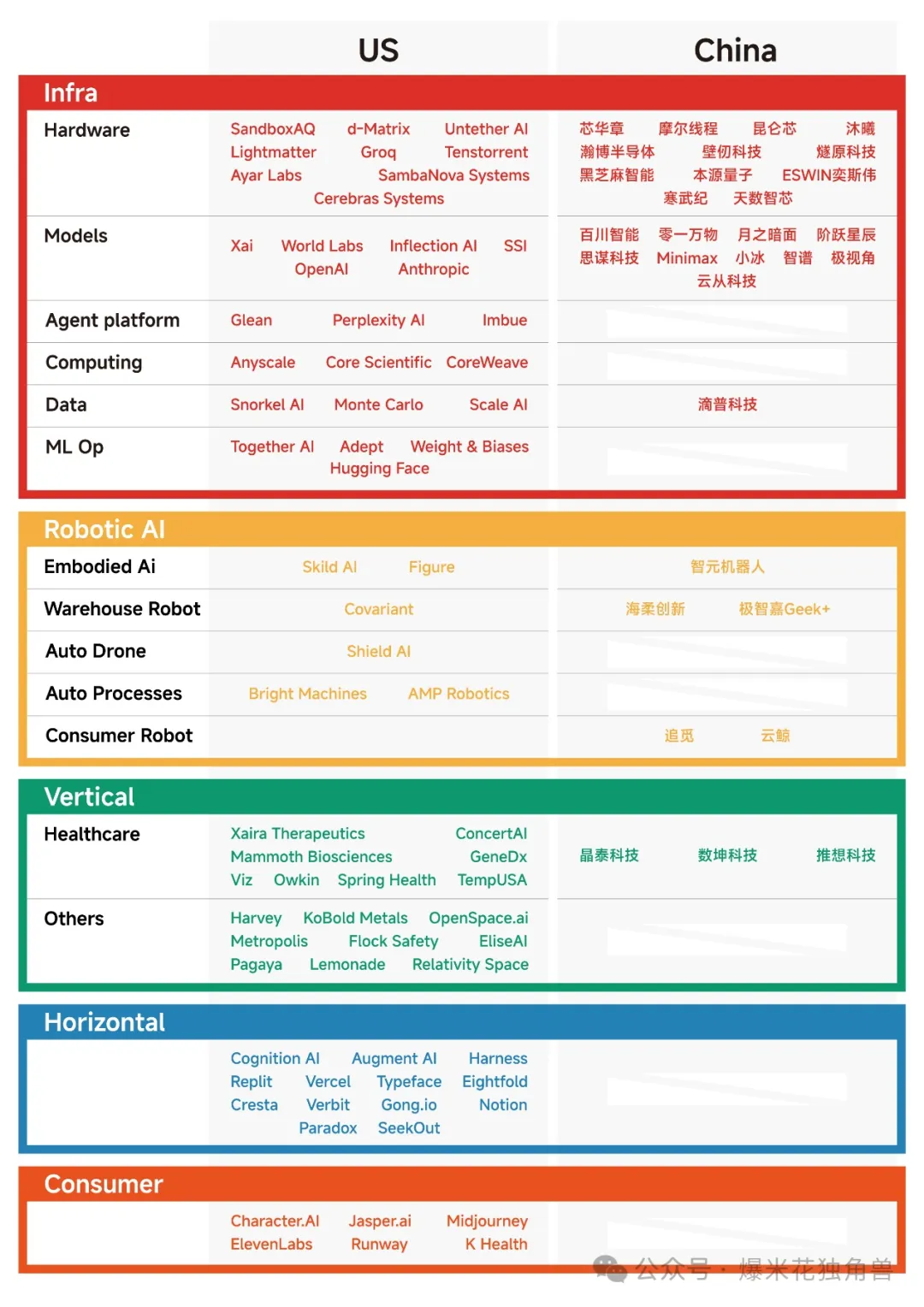
中国独角兽公司的平均估值约为 27.83 亿美元,而美国独角兽公司的平均估值约为 52.16 亿美元。美国是中国的接近2倍。

越大的行业,创新的机会就越多的,能够解决的问题也越多。
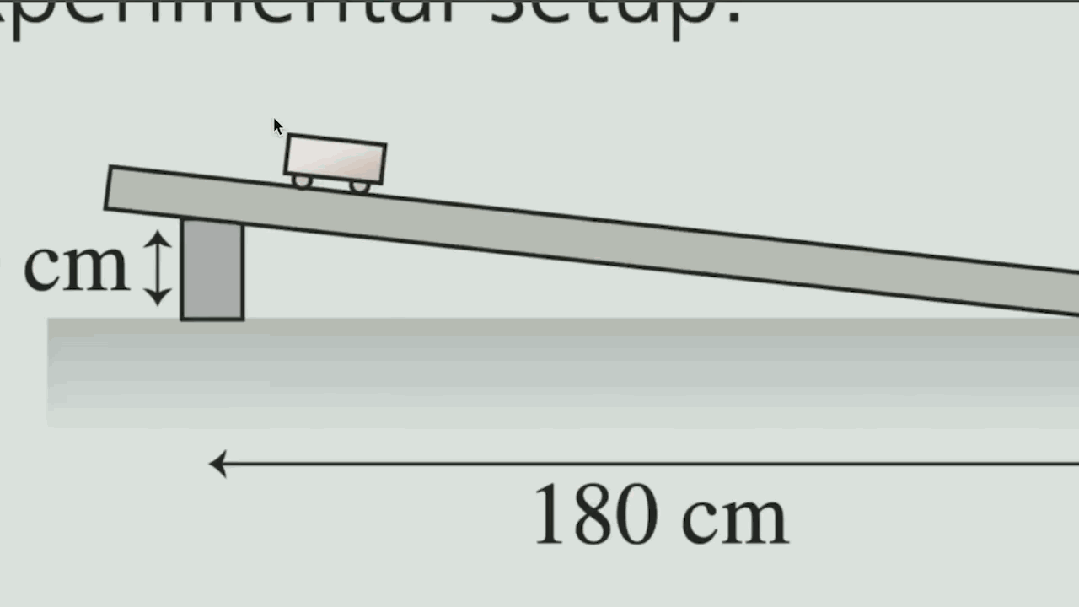
原来物理还能这么学。
国庆节过后,人工智能领域似乎多了几分冷色调。不知道是因为大语言模型(Large Language Model,LLM)的幻觉,还是因为寒露时节的到来。

2024年6月,Matt Garman接任AWS的首席执行官,成为该公司第三任掌门人。Matt将带领AWS继续在全球云计算和人工智能领域的竞争中保持领先地位。亚马逊总裁兼首席执行官Andy Jassy对Matt的出色履历给予高度评价,称其具备非凡的领导能力和丰富的经验,能够引领AWS迈向新的高度。

Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。

