


决战拜年之巅!你能经受住AI七大姑八大姨的灵魂拷问吗?
决战拜年之巅!你能经受住AI七大姑八大姨的灵魂拷问吗?ChatMindAI团队2023年做AI思维导图工具起家。基于大模型的对话式游戏,似乎成了爆款流量密码。
来自主题:
AI资讯
9269 点击 2024-02-03 19:34
 搜索
搜索
ChatMindAI团队2023年做AI思维导图工具起家。基于大模型的对话式游戏,似乎成了爆款流量密码。

作为图领域首个通用框架,OFA实现了训练单一GNN模型即可解决图领域内任意数据集、任意任务类型、任意场景的分类任务。

哈佛大学将AI引入CS课程,学生的个性化「导师」,学习效率拉满!

在软件工程顶会ESEC/FSE上,来自马萨诸塞大学、谷歌和伊利诺伊大学厄巴纳-香槟分校(UIUC)的研究人员发表了新的成果,使用LLM解决自动化定理证明问题。

艾伦人工智能研究所等5机构最近公布了史上最全的开源模型「OLMo」,公开了模型的模型权重、完整训练代码、数据集和训练过程,为以后开源社区的工作设立了新的标杆。

2月2日,巨人网络正式完成了游戏AI大模型Giant GPT的备案。即日起,Giant GPT可以正式开展相关业务。

·美国联邦通信委员会将在未来几周内表决,是否将使用AI生成的语音拨打机器人电话(robocall)定为非法。委员们将在未来几周内对该提案进行表决。

本文讲述了社交媒体上越来越多的美女和型男账号实际上是由AI生成的,让年轻人们陷入了AI侦探的游戏中。文章介绍了网友们辨别AI账号的方法,以及AI账号背后的商业利益和对人类社会关系的影响。

加拿大滑铁卢大学的研究人员在《Nature Computational Science》发表题为《Language models for quantum simulation》 的 Perspective 文章,强调了语言模型在构建量子计算机方面所做出的贡献,并讨论了它们在量子优势竞争中的未来角色。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

一周前,OpenAI 给广大用户发放福利,在下场修复 GPT-4 变懒的问题后,还顺道上新了 5 个新模型,其中就包括更小且高效的 text-embedding-3-small 嵌入模型。

一直以来,让 AI 成为手机操作助手都是一项颇具挑战性的任务。在该场景下,AI 需要根据用户的要求自动操作手机,逐步完成任务。
今天小雷想带大伙体验的,就是这款能够让你无压力对线亲朋好友,充分考验自己「孝心」的聊天小游戏——《决战拜年之巅》。

在大模型技术的带动下,微软成为唯一一家营收增速还有明显上涨的云厂商

微软研究院上线了面向全球研究界的全新线上系列活动 Microsoft Research Forum,旨在共同探讨人工智能时代的最新研究进展、大胆新颖的想法以及全球研究界关注的重要议题。来自微软研究院全球各地的研究人员将分享他们的研究洞见,并与大家进行在线讨论,希望碰撞出更多新的思想火花。

由香港科技大学(港科大)领导的一支国际研究团队,以人工智能技术(AI)研发出一个机器学习模型,能有效促进全球农田的氨减排。

号称要革新浏览器的AI浏览器Arc昨日发布新功能:Instant Links,可以在用户搜索内容的时候,Arc 自动分析用户搜索的内容并直接打开它认为最合适的网页。此外还有Instant Lins(归档)、Live Folders、ARC Explorer等新功能。
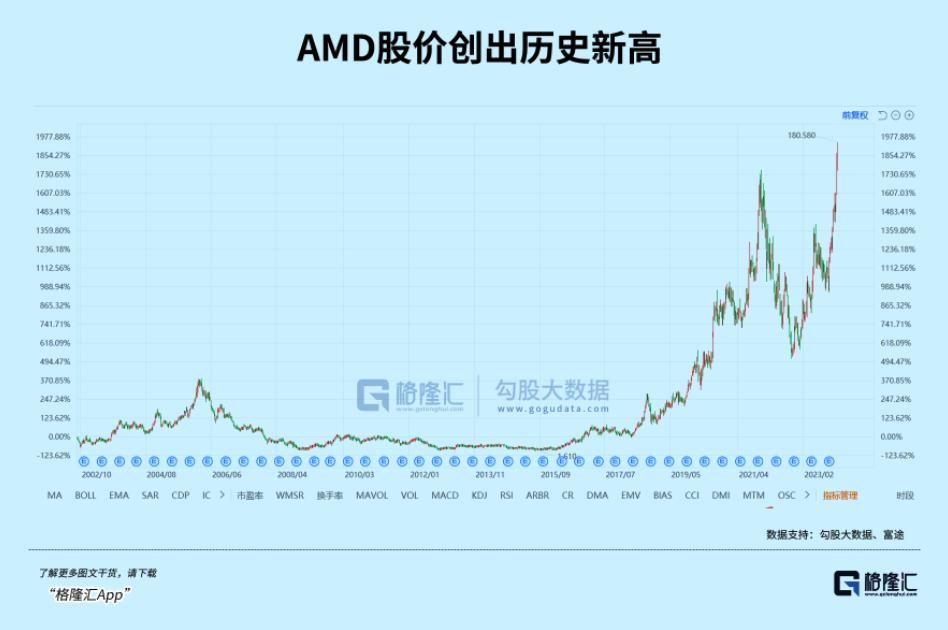
刚刚公布业绩的meta,业绩和指引均超预期,还破天荒地发股息,把回购金额上调到500亿美元,盘后股价上涨15%。财报会上,公司高管表示,Meta的总体预期是,未来几年需要投资更多来支持人工智能业务,今年的情况就会有所反映。

今天的中国发展通用人工智能,是势在必行的事,“宜将剩勇追穷寇,不可沽名学霸王”。那么,大模型真的到了打扫战场的时候吗?这个掀起了全球新一轮风险投资热潮的产品创新,到底是茶叶蛋,还是原子弹?

将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。

就在刚刚,全新升级4.0的日日新大模型发布!不仅如此,商汤还抢先OpenAI首发了支持不同模态工具调用的Assistants API!现在,超千万的中文开发者可以轻松玩转「文生图」和「图生文」了。

Bard又双叒升级了!谷歌正式解禁Bard生图能力,文生图Imagen 2模型加持,效果对标DALL·E。

Meta的第二代自研芯片正式投产!小扎计划今年部署Artemis AI芯片为AI提供算力,以减少对英伟达GPU的依赖。

华中科技大学联合华南理工大学、北京科技大学等机构的研究人员对14个主流多模态大模型进行了全面测评,涵盖5个任务,27个数据集。

来自UCLA的华人团队提出一种全新的LLM自我对弈系统,能够让LLM自我合成数据,自我微调提升性能,甚至超过了用GPT-4作为专家模型指导的效果。

一个体量仅为2B的大模型,能有什么用?答案可能超出你的想象。
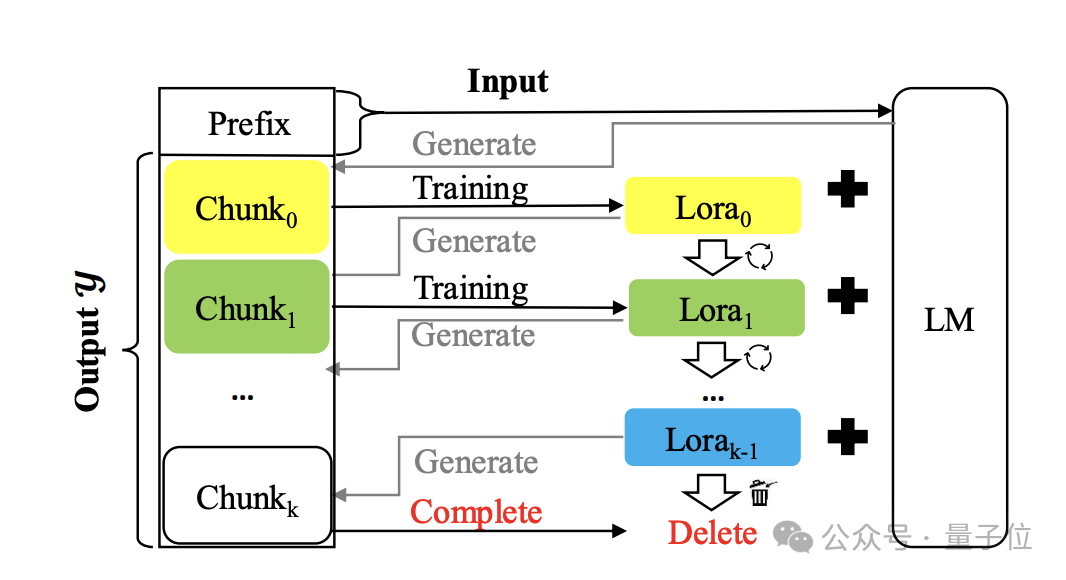
来看一个奇妙新解:和长度外推等方法使用KV缓存的本质不同,它用模型的参数来存储大量上下文信息。
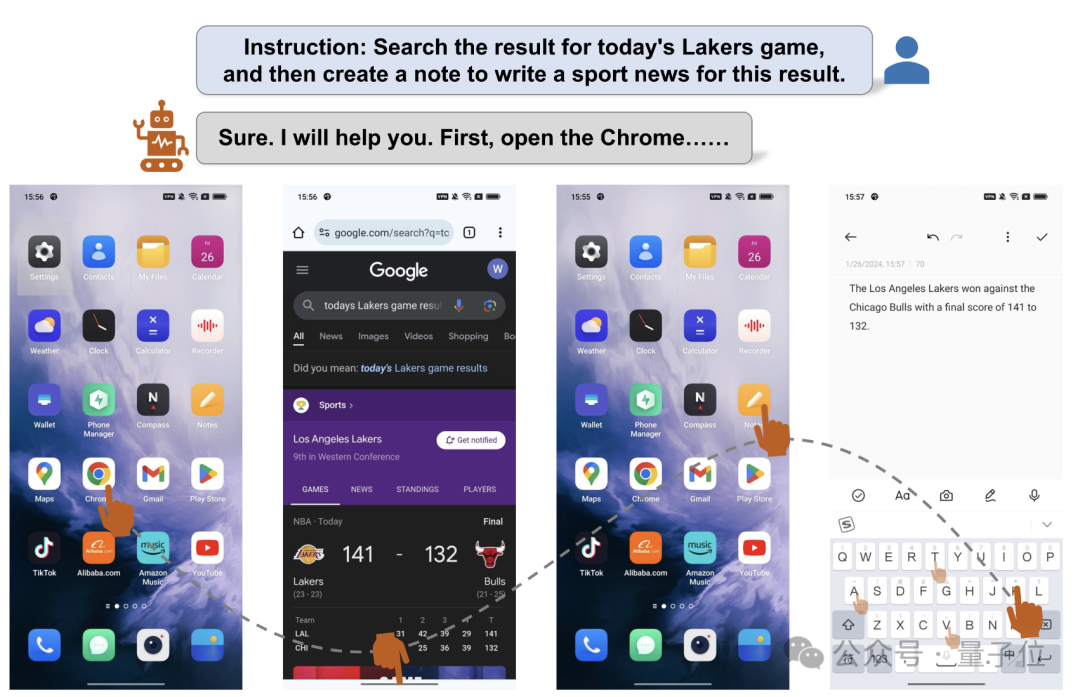
新的Agent打破了APP的界限,能够跨应用完成任务,成为了真·超级手机助手。
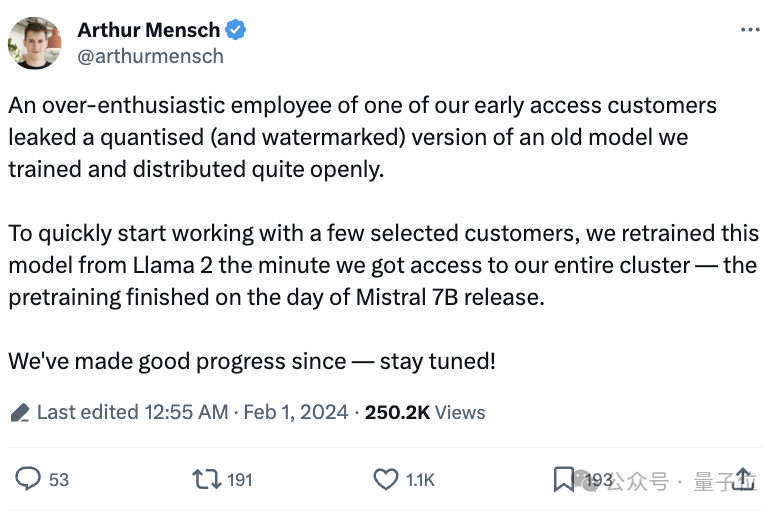
Mistral-Medium竟然意外泄露?此前仅能通过API获得,性能直逼GPT-4。

只需一张照片,整个过程无需训练 LoRA 模型,多风格 AI 写真即刻呈现!

