# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,谷歌正式发布 Gemma 4,称“这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。
Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。
在端侧,E2B 和 E4B 模型针对移动和物联网设备优化,推理时分别激活约 20 亿和 40 亿参数,以降低内存和电量消耗。据介绍,这两个模型已与谷歌 Pixel 团队、高通和联发科等硬件厂商合作,可在手机、Raspberry Pi、NVIDIA Jetson Nano 等设备上离线运行,延迟接近零。
与此同时,研究人员表示,26B MoE 模型有一个巧妙之处:在推理任务中,它只会激活 38 亿参数,因此既能保持较高运行速度,又不会牺牲大模型所具备的深厚知识储备。
26B 和 31B 模型提供面向 IDE、编程助手和 Agent 工作流的高级推理能力。模型针对消费级 GPU 进行了优化,让学生、研究人员和开发者能够把自己的工作站变成以本地优先为核心的 AI 服务器。
谷歌 DeepMind 研究人员 Clement Farabet 和 Olivier Lacombe 表示,在 Gemma 4 上,他们设法进一步压榨出了更多“单位参数智能”,让这些模型能够显著实现“越级发挥”。例如,31B Dense 版本目前在行业标准榜单的开源模型中排名第三。
Gemma 4 建立在与 Gemini 3 相同的架构基础之上,旨在处理复杂推理任务,并支持在工作站、智能手机等低功耗设备上本地运行的自主 AI Agent。这次关键提升包括:
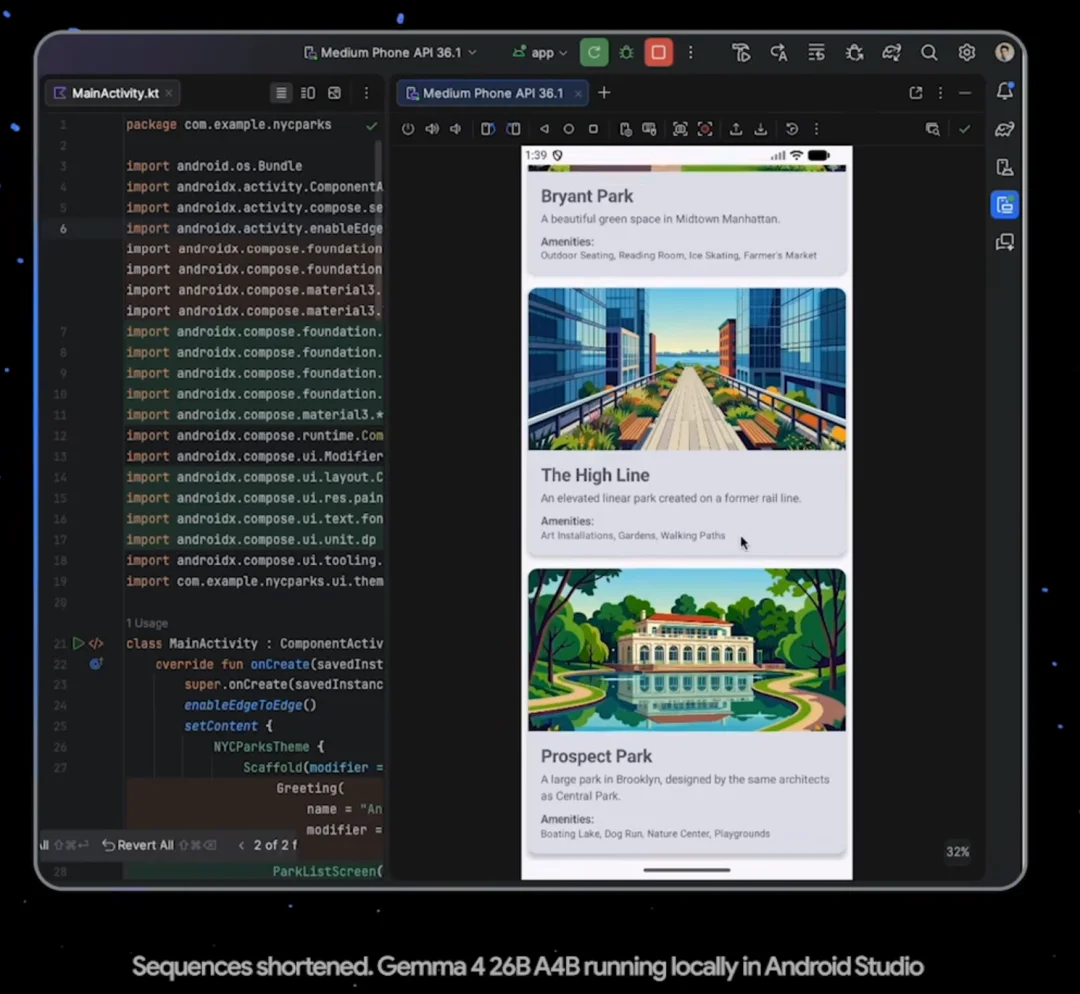
Farabet 和 Lacombe 解释称,每个 Gemma 4 模型都更适合用于运行 AI Agent。此前几代 Gemma 模型往往需要开发者额外调整设计,才能与其他软件工具交互;而 Gemma 4 已原生支持函数调用和结构化 JSON 输出、原生系统指令以及超过 140 种语言。这意味着,开发者可以用它们来驱动自主 Agent,与第三方工具交互,并执行多步骤任务规划。
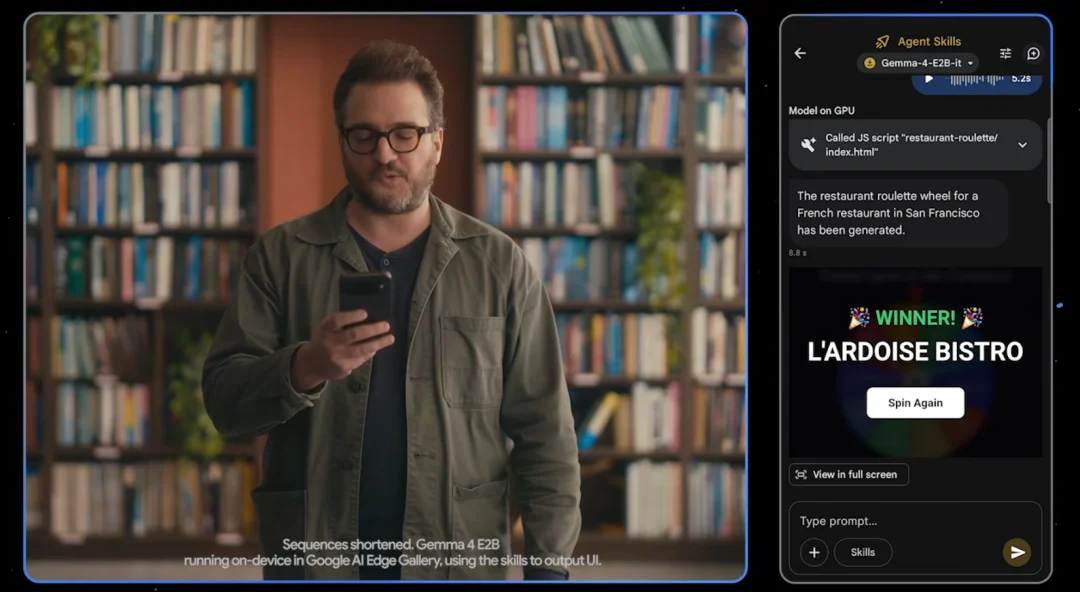
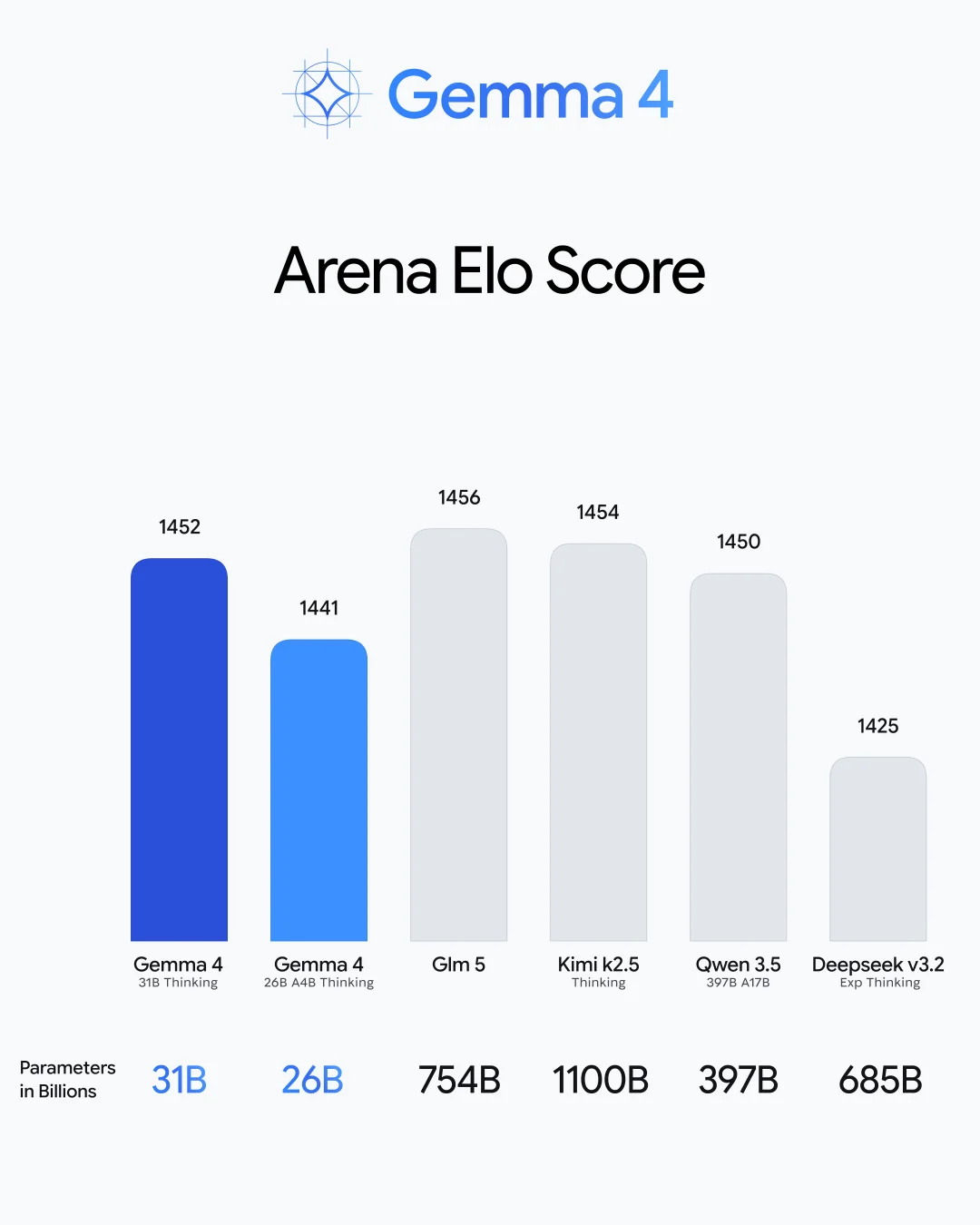
根据 Arena AI 文本排行榜(截至 2026 年 2 月 1 日),31B 模型排名全球开放模型第 3 位,26B MoE 模型排名第 6 位。
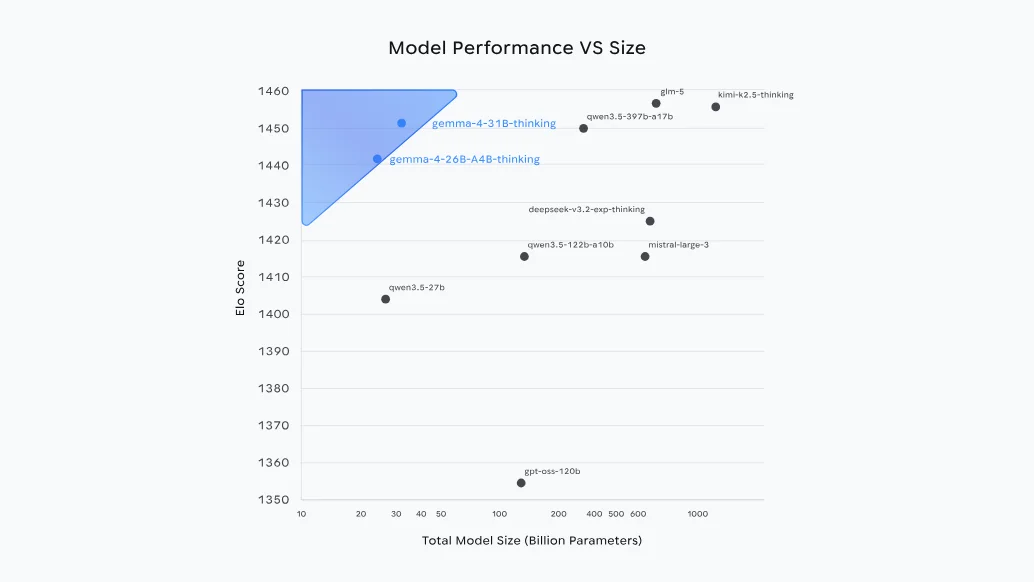
谷歌表示,Gemma 4 在部分基准测试中表现优于参数大 20 倍的模型。
不过,有网友自己测算结果 Qwen3.5-27B 要略优于 Gemma 4 31B。

还有网友评价道,“最让人眼前一亮的部分在于:一共四种尺寸,全部都为 Agent 场景做好了准备,而且全都可以在本地运行。我们一直都在呼吁,需要那种不用每次‘思考’都把数据传回云端的模型。现在他们终于听进去了,而且给出的东西甚至比预期还多。”
开源 + 本地,谷歌扩大优势
此次,Gemma 4 继续采用 Apache 2.0 许可证,允许商业使用、自由修改和部署。谷歌称,这一选择旨在给予开发者对数据、基础设施和模型的完全控制权,支持本地或云端环境的安全部署。这消除了其他一些 AI 模型在商业使用上的诸多限制,或会成为企业应用开发者的理想选择。
此外,谷歌还详细列出了使用各种大小的 Gemma 4 模型版本运行推理所需的大致 GPU 或 TPU 内存。
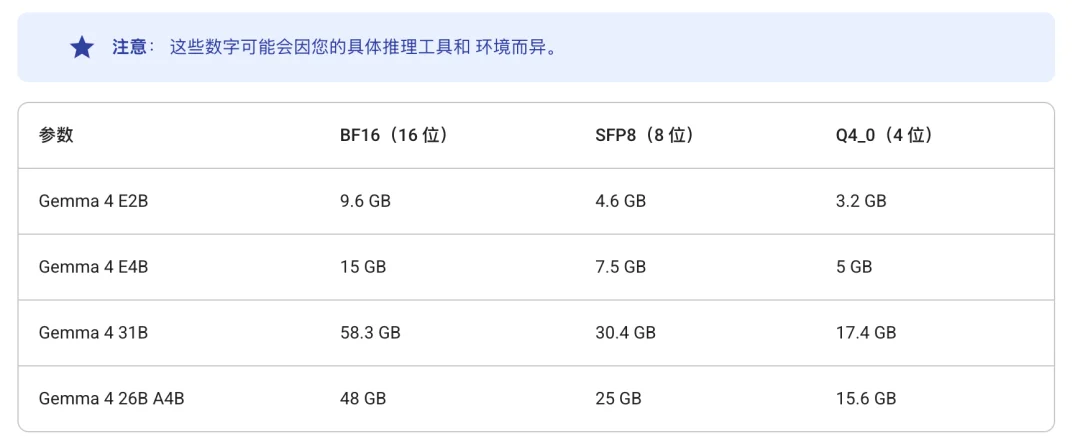
Gemma 4 在架构设计上进一步兼顾了效率与部署现实。E2B 和 E4B 中的 “E” 指的是“有效参数”,这两款小模型采用了 PLE(每层嵌入)技术,以提升端侧部署时的参数利用效率。需要注意的是,PLE 虽然不会增加模型层数,但会为每层解码器中的每个 token 配置独立的小型嵌入,因此模型实际加载到内存中的静态权重,往往会高于“有效参数规模”表面上对应的占用。
26B 版本采用了混合专家(MoE)架构,虽然生成时每个 token 实际只会激活约 40 亿参数,但为了保证路由和推理速度,全部 260 亿参数仍需提前载入内存,所以它的实际显存需求更接近稠密 26B 模型,而不是 4B 模型。
此外,官方给出的内存估算通常只覆盖静态模型权重本身,并不包含运行框架、上下文窗口和 KV Cache 带来的额外显存开销;如果进一步进行微调,显存需求还会明显高于推理阶段,具体占用则取决于开发框架、批量大小,以及采用全参数微调还是 LoRA 等参数高效微调方案。
这次发布再次凸显了谷歌想要主导“本地 AI”产业的雄心。Constellation Research 分析师 Holger Mueller 表示,即便是较大规模的 Gemma 4,也小到足以在单张图形处理器上运行,因此它们非常适合边缘场景以及那些对低延迟和数字主权有较高要求的应用。
他认为,“谷歌正在扩大自己在 AI 领域的领先优势,不只是依靠 Gemini,也包括通过 Gemma 4 家族这样的开放模型。这些模型对于构建 AI 开发者生态非常重要,也将帮助公司切入不同设备形态下的功能型和垂直行业应用场景。谷歌在此前发布 Gemma 3 时已经树立了很高的门槛,因此这次发布也承载了很多期待。”
现在,开发者可以通过谷歌云直接访问这些模型,也可以在 Hugging Face、Kaggle 和 Ollama 上获取模型及其开放权重。Android 开发者可在 AICore Developer Preview 中试用智能体工作流原型。
此外,谷歌提供了多种推理和微调路径,包括:Hugging Face、LiteRT-LM、vLLM、llama.cpp、MLX、Ollama、NVIDIA NIM 和 NeMo、LM Studio、Unsloth、SGLang、Cactus、Docker、MaxText、Tunix、Keras。云上部署支持 Vertex AI、Cloud Run、GKE、Sovereign Cloud 及 TPU 加速服务。
Gemma 4 开箱支持 NVIDIA(从 Jetson Nano 到 Blackwell GPU)、AMD GPU(通过开源 ROCm™ 栈)以及 Google Cloud TPU。谷歌方面称,新模型采用与谷歌专有模型相同等级的基础设施安全协议,适用于企业和主权机构的高标准安全与可靠性要求。
参考链接:
https://deepmind.google/models/gemma/gemma-4/#e2b-and-e4b
文章来自于微信公众号 "InfoQ",作者 "InfoQ"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
