# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
RESEARCH
xbench,就是红杉自己弄的那个中立评测lab,刚刚又整了个新活:让 AI 做药企的数据分析,跟人类实习生比个高低,然后遥遥领先的赢了
前两天,红杉的朋友跟我说了这事儿,今天一早详细信息也放了出来:Auto Research时代,AI Scientist的第一场药企实习考验
故事大概是这样:
红杉的 AI 评测平台 xbench,联合 Phylo 和 Humanlaya Data Lab,找来斯坦福、哈佛、北大和头部药企的 100 位资深专家,花了 1000 多个小时,搭了 全球首个面向真实生物医药研究场景的过程级评估框架:BiomniBench,让 AI 从头到尾做一遍药企的真实数据分析,结果是:
最强 AI 组合拿到 73.34 分(满分 100),超过了人类实习生 40-50 分的平均线
诶...这里的「最强 AI 组合」是什么?让我卖个关子,稍后揭晓
这里补充一个背景:在药企,科学家的日常工作是啥?
答:对着脏的一塌糊涂数据一通分析,然后得到一个满意的结果
比如:给你一组免疫治疗患者的单细胞测序数据和临床信息,你要判断某个 biomarker(生物标志物)是否值得进入下一轮实验验证。数据清洗、样本筛选、统计方法、多重检验校正、生物学解释...每一步都可能出错
虽然可能出错,但出错了也不一定会报错
比如,如果把外周血细胞也算进了肿瘤组织的分析,代码能跑通,图也画得漂亮,但结论...大概率就错了
一位药企一线科学家说过:「在生物学里,一个看似正确的结论可能建立在完全错误的分析过程之上,而等你发现的时候,药已经做失败了」
在过去的 AI 评测中,很多的东西是测结果的,这样的 bench 也好搭建,但这次 xbench 这次做的 BiomniBench,测的是「模型会不会真的做研究」,从数据清洗、到方法选择、到统计检验、到生物学解释,每一步都测
或者说,这个叫:process-level evaluation,过程级评测
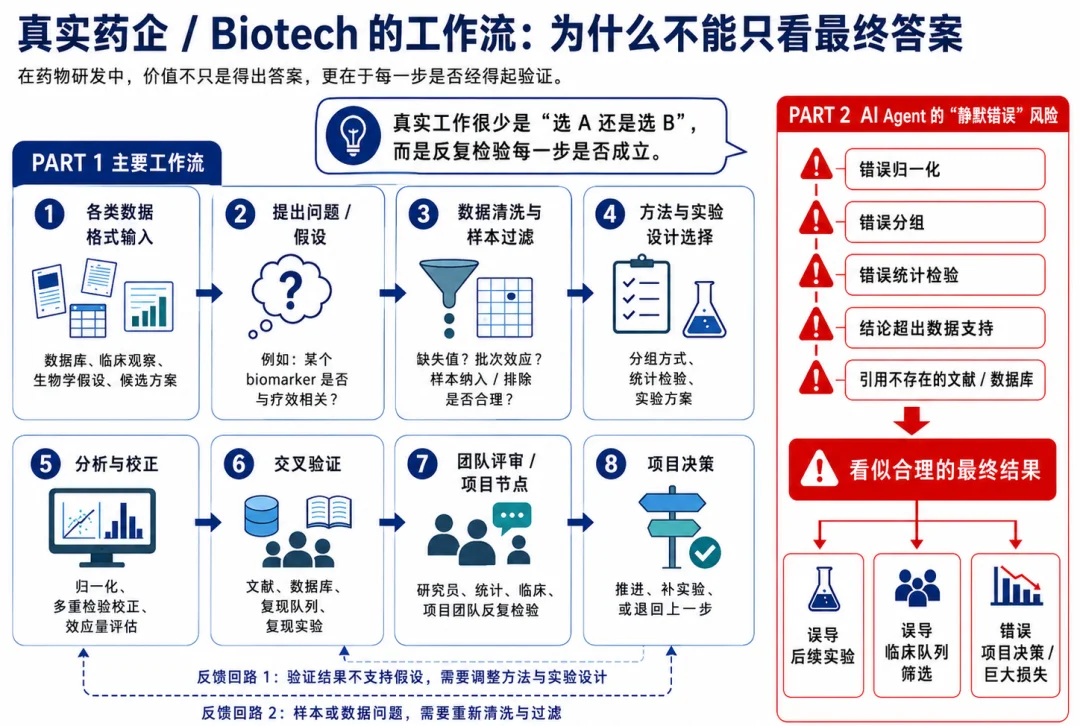
做药的都懂:跑通了不等于对了
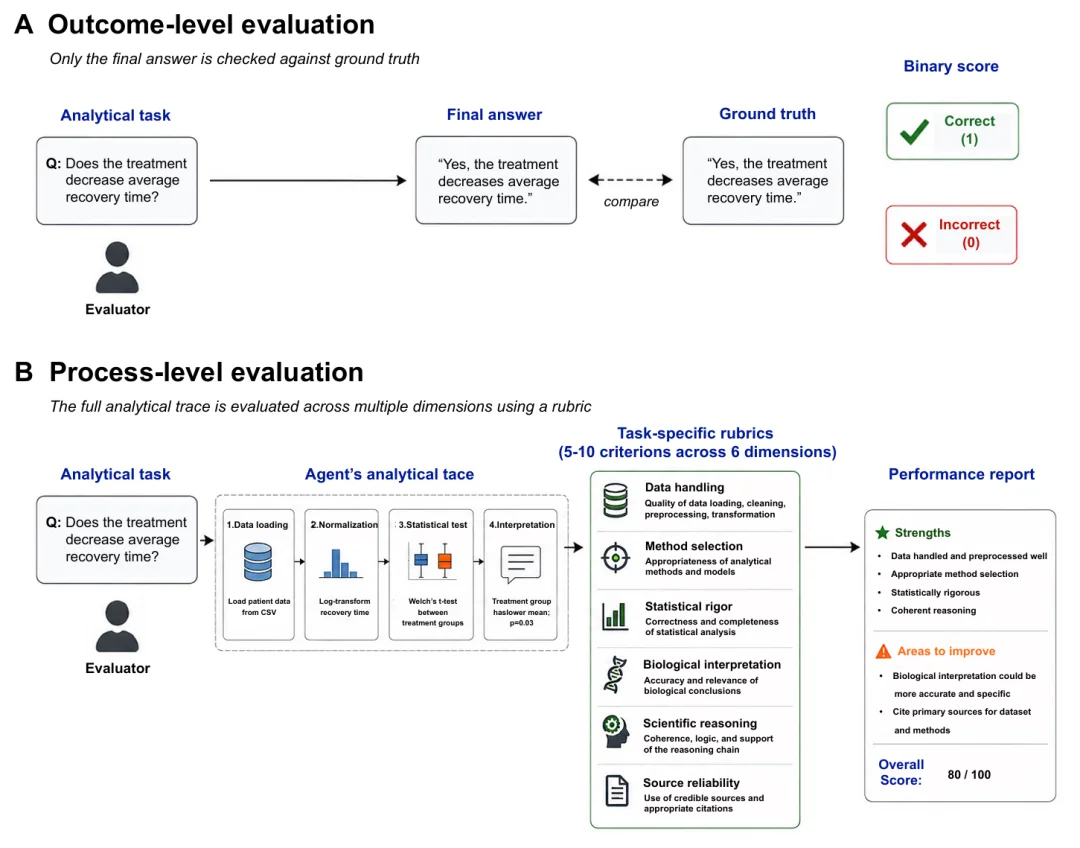
左边只看答案,右边看全过程
BiomniBench 第一个落地的模块叫 BiomniBench-DA,聚焦数据分析
这一模块包括 100 道题,都来自 Nature、Cell、Science 的公开数据,由原论文作者或 5 年以上经验的专家重新设计,覆盖肿瘤、代谢与内分泌、免疫、神经、心血管 5 大疾病领域,17 类分析任务
在测试的过程中,要求 AI 答题时给出完整分析轨迹,包括:读了什么数据,做了哪些清洗,为什么选某个方法,统计结果怎么样,怎么解释。然后 LLM 裁判按专家写好的评分标准,从六个维度打分:数据处理、方法选择、统计严谨性、生物学解释、科学推理、来源可靠性
当然,评分标准允许多条合理路径的。在很多生物学问题,t 检验和 Wilcoxon 都行,关键是你得说清楚为什么选这条,就是...「言之有理即可」
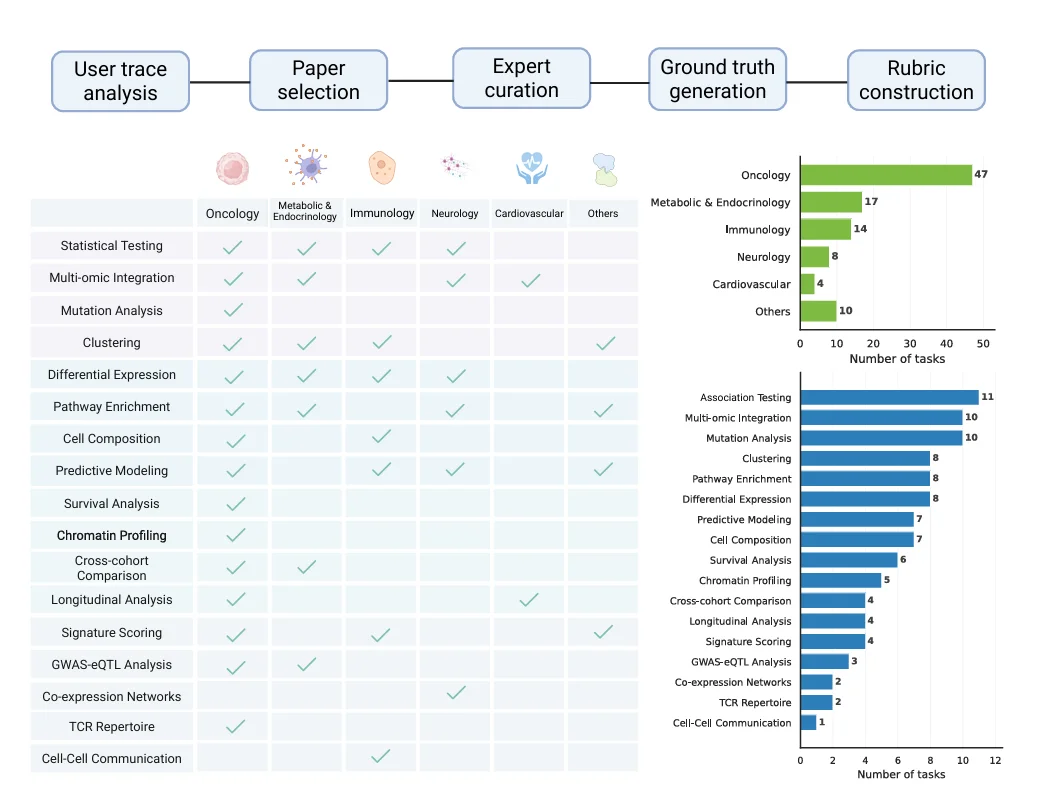
5 大疾病领域 × 17 类任务
好,回到刚才卖的那个关子
最强配置是 Claude Code + Opus 4.7,73.34 分。排在后面的是 Claude Code + Opus 4.6,69.83 分。第三名 Codex CLI + GPT-5.4,68.69 分。前三名里两个是 Claude Code 的配置
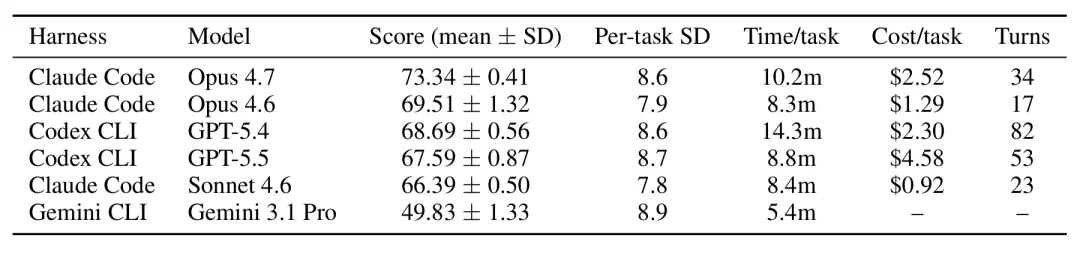
人类呢?人类实习生 平均 40-50 分,比 AI 低到不知道哪里去了
速度和成本...应该就不用说了吧:
AI 完成一个任务平均 4.9 到 25 分钟,花 0.92 到 4.58 美元;
人类做同样的事通常要数小时到数十小时,耗费 3 个馒头
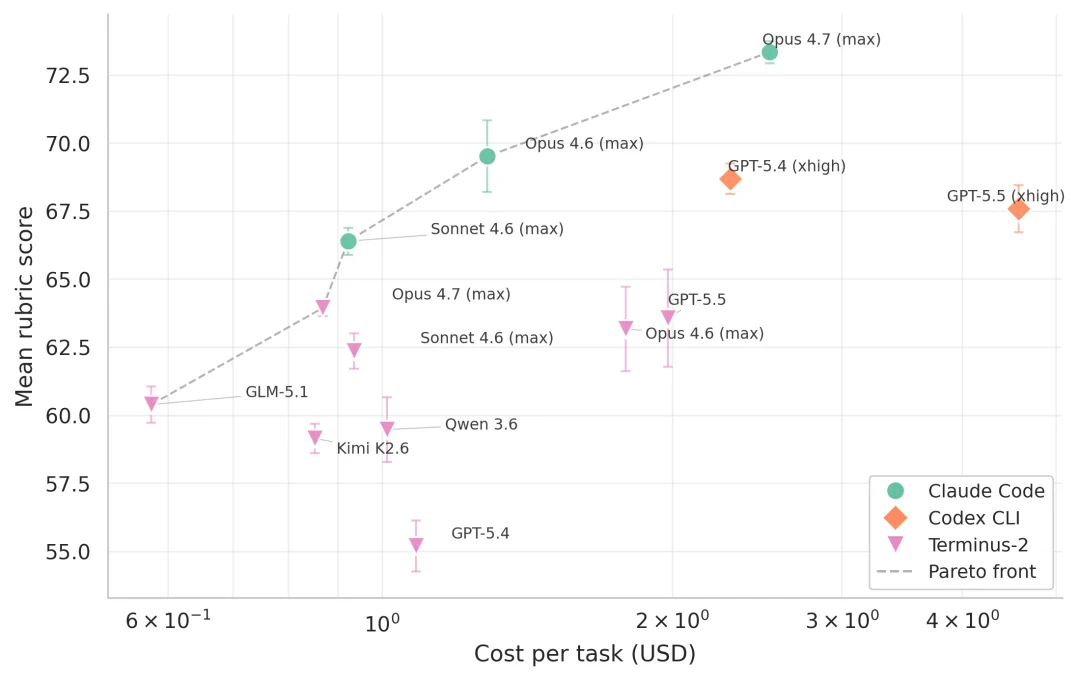
贵的不一定好,但好的确实贵
药企来说,这个进步还是很有价值的:大量探索性分析可以前置、并行化,然后丢给 AI,早期试错成本大幅降低
对了,这次的研究还带来个小收获,Agent 框架,对结果的影响极大:同一个 GPT-5.4,放在 Codex CLI 里 68.69 分,放在 Terminus-2 里只有 55.19 分
在药企数据分析这个场景下,Agent 框架的影响,跟模型本身差不多
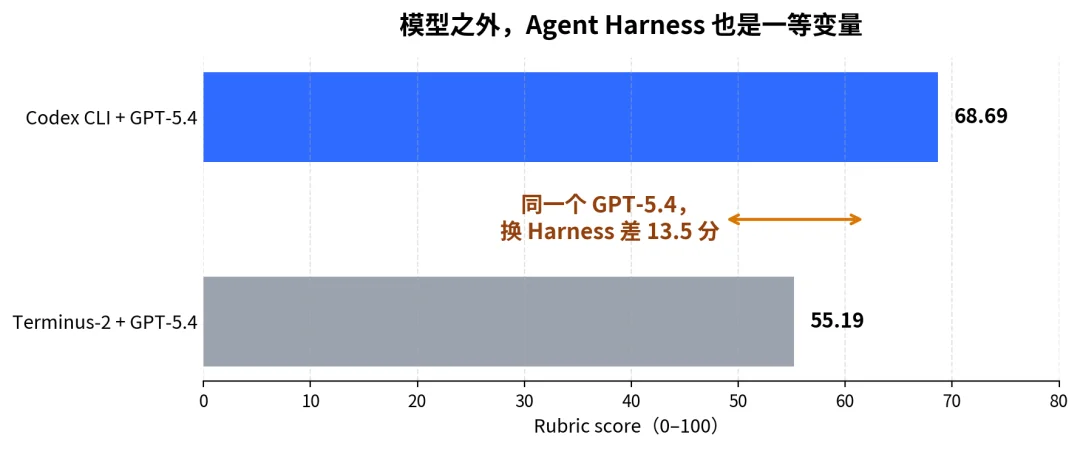
同一个脑子,换组工具
另外一个有趣的是:AI 也偏科
细胞组成分析拿到 91 分,突变分析 88 分,边界清晰的任务是 AI 的专长。GWAS-eQTL 分析只有 45 分,通路富集 64 分,需要判断统计方法和理解生物学上下文的任务,AI 就稍显乏力了
然后,从评估维度看,所有模型在「生物学解释」上都有明显凹陷。AI 能算,但不太能解释。短期内「AI 算 + 人类解释」可能是最安全的协作模式
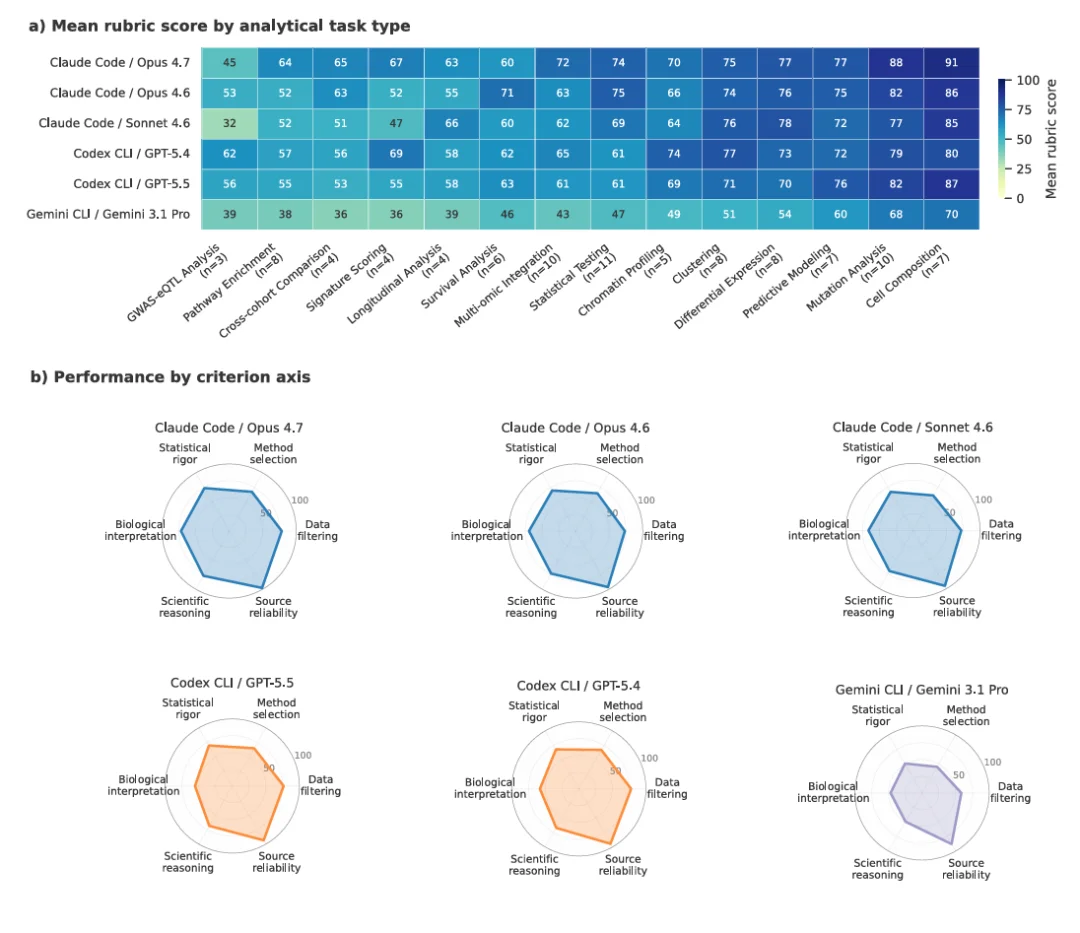
偏科这事,人和 AI 都一样
先说结论:对于数据的初步分析,可以用了
但如果分析错了需要进去,那还不行
以及,xbench 后续会开源部分题目供内部测试使用,也会继续推出覆盖更多行业场景的 benchmark
Paper(bioRxiv)
https://www.biorxiv.org/content/10.64898/2026.05.12.724604v1
HuggingFace Dataset
https://huggingface.co/datasets/phylobio/BiomniBench-DA
xbench 是红杉中国推出的 AI 基准测试工具,采用双轨评估体系,同时追踪模型的理论能力上限与 Agent 的实际落地价值,并通过持续维护和动态更新测试内容确保时效性
网址:xbench.org
联系:team@xbench.org
Phylo 源自开源项目 Biomni,由斯坦福科学家团队于 2025 年创立,专注于生物医学智能体的应用研究。2026 年 2 月推出 Biomni Lab,致力于让每一位生物医学科学家都能借助 AI Agent 加速科学发现
网址:biomni.phylo.bio
联系:contact@phylo.bio
Humanlaya AI 成立于 2025 年,通过定义真实、高经济价值的可验证任务,推动大模型能力边界的拓展与经济价值的落地
网址:humanlaya.com
联系:inquiries@humanlaya.com
文章来自于"赛博禅心",作者 "金色传说大聪明"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
