# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
过去两年,大模型在文本理解、代码生成、推理问答上狂飙突进。但凡是你能在屏幕上敲出来的文字,喂给 Claude、GPT、文心一言,几乎都能拿到漂亮的结果。
但只要遇到纸质文档的电子版——扫描的合同、拍照的发票、PDF格式的科研论文、Word/Excel/PPT——这套魔法就立刻失灵。
表格错位、公式乱码、版面崩坏、印章挡字、繁体竖排、手写体……这些对人类眼睛来说不值一提的小麻烦,足以让一个 GPT-5.5 级别的模型输出一坨"看似正确、实则胡编"的垃圾文本。更糟的是,企业里 80% 的真实数据,恰恰锁在这些非结构化文档里,根本进不了 RAG 系统。
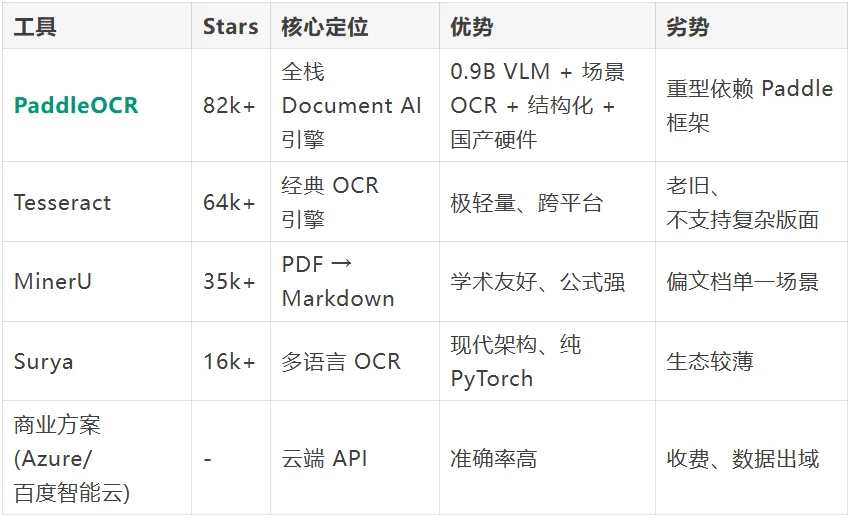
PaddleOCR 就是为打通这一公里而生。它由百度飞桨团队开源,截至 2026 年 6 月已在 GitHub 收获 82,000+ Stars、10,700+ Forks,是国产开源 AI 项目里少有的"长红爆款"——6 年迭代、3 周一次大版本,被 Dify、RAGFlow、Cherry Studio、MinerU、Haystack、网易有道 QAnything、微软 OmniParser 等一众明星项目内置为默认 OCR 引擎,是整个 AI Agent 生态的事实标准之一。

PaddleOCR Banner
项目地址:https://github.com/PaddlePaddle/PaddleOCR
License:Apache 2.0(商业可用)|主语言:Python|支持系统:Linux / Windows / macOS|硬件:CPU / GPU / 昆仑芯 XPU / 国产 NPU 通吃
PaddleOCR 当前版本(3.7.0,2026-06-11 发布)已经远不止"识别文字"这么简单,它把自己重新定位成 "Document AI Engine"——文档智能引擎。整体能力可以拆成四块:
这是 PaddleOCR 最近一年最重磅的升级。团队把一个 NaViT 风格的动态分辨率视觉编码器和百度自研的 ERNIE-4.5-0.3B 语言模型缝合在一起,做出了只有 0.9B 参数的视觉语言模型 PaddleOCR-VL-1.6。
体积虽小,战绩惊人:
PaddleOCR-VL Demo
一句话概括:它不是把 OCR 做得更准,而是把"读文档"这件事直接做到了 LLM-ready。
PaddleOCR-VL 解决"看懂",PP-StructureV3 解决"还原结构"。它能把复杂的 PDF / 图片精确转成 Markdown 或 JSON,并且保留所有坐标信息:表格的每一个 cell、文字的每一行位置,都能精确定位。
这个能力对企业太关键了:
对于做 RAG 的团队来说,这意味着什么?你的合同库、论文库、内部资料库,可以批量转成结构化文本,质量高到 LLM 可以直接基于它做问答。
如果说 PaddleOCR-VL 是为"文档解析"打造,PP-OCRv6 就是为现实世界打造——街头招牌、身份证、车牌、工业零部件、数码显示屏、点阵字、轮胎印刷字……这些"野生文字"它都能精准识别。
最新版 PP-OCRv6 的硬指标:

最离谱的是——34.5M 参数的 medium 模型,精度超过 Qwen3-VL-235B 和 GPT-5.5。这意味着你可以在一台普通的边缘设备上跑出比云端大模型更准的 OCR。
PaddleOCR 的工程化程度,是它能在企业里大规模铺开的关键:

PaddleOCR Architecture
光说技术不过瘾,看看 PaddleOCR 真正在产业里干什么活:
📋 场景一:财务票据自动化
发票、收据、银行回单、报销单批量识别——金额、税号、日期、商品明细直接结构化输出,对接 ERP 系统,每月节省上千人工小时。
⚖️ 场景二:合同/法律文书解析
几百页的合同 PDF 喂进去,章节、条款、签署方、关键日期自动抽取,律所用它做"智能合规审查",律师从"读合同"变成"审 AI 总结"。
🏥 场景三:医疗 + 科研论文处理
PubMed 下载的 PDF 论文,公式、表格、引用一气呵成转 Markdown,医生和科研人员用它在内部知识库做循证医学问答。
🤖 场景四:RAG 系统的数据预处理
这是 PaddleOCR 在 AI Agent 时代最大的红利——Dify、RAGFlow、Cherry Studio 都内置它作为默认文档解析引擎。没有它,企业内部 80% 的私有数据进不了 RAG。
🏭 场景五:工业制造质检
印刷电路板上的字符、轮胎侧面的批号、流水线零件上的点阵字——PP-OCRv6 在工业场景的专用优化,让它直接嵌入产线做实时质检。
PaddleOCR 的不可替代性:同时具备「开源 Apache 2.0 + 国产可控 + 0.9B 小模型精度反超 GPT-5.5 + Dify/RAGFlow 原生集成 + 100+ 语言」组合的,目前市面上只有它一个。
最简单的玩法是直接跑 PP-OCRv6 的 Python 三行代码:
# 安装(Python 3.8~3.12)
pip install paddlepaddle paddleocr
from paddleocr import PaddleOCR
ocr = PaddleOCR(lang="ch") # 中文模型
result = ocr.ocr("invoice.png")
for line in result[0]:
print(line[1][0]) # 输出识别文字
如果想体验 PaddleOCR-VL-1.6 的文档解析能力:
from paddleocr import PaddleOCRVL
vl = PaddleOCRVL()
result = vl.predict("contract.pdf")
result.save_to_json("contract.json")
result.save_to_markdown("contract.md")
不想装环境?官网 www.paddleocr.com 提供 Experience Center,上传文件即可在线试用,零门槛。
PaddleOCR 最值得尊敬的地方,不是它今天有多少 Stars,而是它整整迭代了 6 年。
从 2020 年的 PP-OCR 初代,到 2024 年的 PP-OCRv4,再到 2025 年押注 VLM 路线推出 PaddleOCR-VL,到 2026 年 6 月用 0.9B 小模型把 GPT-5.5 拍在沙滩上——这是国产开源 AI 项目里少有的、坚持长期主义最终撞线的样板。
它证明了:在大模型时代,专注做深一个垂直方向 + 持续打磨工程化 + 真正拥抱开源生态,依然能跑出世界级的产品。
对于正在做 RAG、Agent、知识库、文档数字化的开发者来说,PaddleOCR 几乎是绕不开的基础设施。早点接入,少走弯路。
项目地址:https://github.com/PaddlePaddle/PaddleOCR
官网体验:https://www.paddleocr.com
License:Apache 2.0(完全商业可用)
文章来自于"微卷熊",作者 "微卷熊"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
