# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
因为一个Bug,你的固态硬盘,正在被Codex悄悄写穿。
一年「吃掉」一块1TB的固态硬盘?
OpenAI的旗舰编程工具Codex,正在以一年640TB的写入量,烧穿你的固态硬盘。

前段时间,一位开发者在GitHub上提交了一个issue。这个如今标着「Closed」、编号#28224的GitHub issue,标题写着:
Codex的SQLite反馈日志一年能写640TB,迅速耗尽固态硬盘寿命。
据这位报告者实测,他的主固态硬盘连续开机21天被写掉37TB,照此推算一年约640TB,足够报废一块总写入量(TBW)为600TB的消费级硬盘。
为佐证,他贴出了两张表。
在证据1里,这个日志库始终只有1.2GB,表面像什么都没发生;可它的自增行ID已经冲到55亿,真正留存的行不过50万出头,两者差了整整一万倍。
关键在于,硬盘损耗只算一共写过多少、不管此刻还剩多少:这55亿行全都落过盘,删掉也退不回已经付出的写入。所以你查文件永远只看到那50万行,硬盘却早已扛下55亿行的写入量。
证据2暴露了这55亿行的分布:九成多是连开发者自己都不会回头看的调试噪声,光把每条WebSocket数据包整包抄下来这一项,就占了一半。
罪魁祸首,是一行Level::TRACE默认配置,它把你硬盘的写入寿命,当成了免费的草稿纸。
Hacker News上一条高赞评论,直接为这事定了性:
这是「劣质软件」(slopware)最臭名昭著的例子之一。

这位网友还无奈地甩出一句:
这真是个悲剧。这个世界,需要有人来和Anthropic竞争。
更尴尬的是,这个问题不是没人报。
从今年4月起就有零星反馈,前后拖了两个多月,非要等用户自己测算、写报告、把它顶上Hacker News头条,才算被正经对待。即便如此,这一轮也只砍掉了约85%的日志写入。
还有人想自己动手,却发现无从下手:这些工具的桌面端是闭源的。
评论区还有一句神评论:审查流程怎么没拦住这么明显的错误?哦对了……@codex 审查一下这个。
640TB是什么概念。
主流消费级固态硬盘,标称写入寿命大概150到600 TBW,够普通用户用上十几二十年。
而Codex这个「记录自己干了点什么」的日志功能,一年就能写满。
事情要从这位用户清点硬盘说起。他的机器连续开机21天,主固态硬盘被写掉了37TB。
照这速度,一年约640TB。
更离谱的是写入方式。
Codex在本地维护着一个SQLite数据库logs_2.sqlite,专门记录反馈日志。这位用户抓了15秒——数据库被插入36211行,而保留的总行数,从头到尾都是681774,一个没多。
每插进一行,就有一行被删掉。行数始终不变,磁盘却被来回擦写几万次。
这套机制有个外号,叫insert-and-prune:插入,然后立刻删除。
更荒诞的是它记的东西:一堆文件系统的inotify事件。
ld.so.cache被记了128764次,locale.alias37982次,passwd23843次。
同一个文件,被同一个程序,反反复复记上十几万遍。
日志里的自增ID已经超过55亿,而真正留存的行只有约50万。
两者差了一万倍。
这不是bug,简直就像是一个AI编程工具在对着自己的硬盘反复念经。
一边写一边删,留下的logs_2.sqlite能多大?大约1GB。
这就引出整件事最反常识的一点:固态硬盘的寿命看的是「写入量」,而非「文件大小」。一个1GB的文件被反复擦写640次,对硬盘就等于写了640TB。
SQLite用的是WAL机制,每次改动先写进-wal文件,攒够再checkpoint回主库。Codex每15秒做三万多次插入加删除,每一次都要经过WAL、索引更新、checkpoint,同一块存储区,被擦了又擦。
打个比方:一本1GB的笔记本,你每天擦掉重写1750遍,连写一年。笔记本还是那本,纸已经磨穿了。
这也是这个bug能潜伏这么久的原因:它不占空间,只烧寿命。
查可用磁盘看不出异常,文件大小一直很安静,只有去读硬盘自己的SMART健康计数,才能看到写入量在悄悄累积。
根因
一行被无视的RUST_LOG
为什么会记这么多日志?
答案在Codex源码的一行配置里:SQLite反馈日志的sink,初始化时用的是Targets::new().with_default(Level::TRACE)。
一句话,日志默认开到TRACE级别,最高、最啰嗦、什么都记的那一档。
Codex的日志框架是Rust生态的tracing,标准做法是读RUST_LOG环境变量。用户当然试过,把RUST_LOG调成info、warn,甚至直接关掉。
没用。
with_default(Level::TRACE)把全局默认硬钉死在TRACE,RUST_LOG在这条路径上根本不生效。你以为自己关掉了日志,它照写不误。
这种bug最坑人的地方在于,并非「你忘了配置」,而是「你配置了,它假装没听见」。
更刺眼的是一个比例。
把保留的日志按类别拆开,TRACE占了70.7%,约732.5 MB。再加上codex_otel那两路镜像遥测日志(log_only和trace_safe),又占了25.3%。
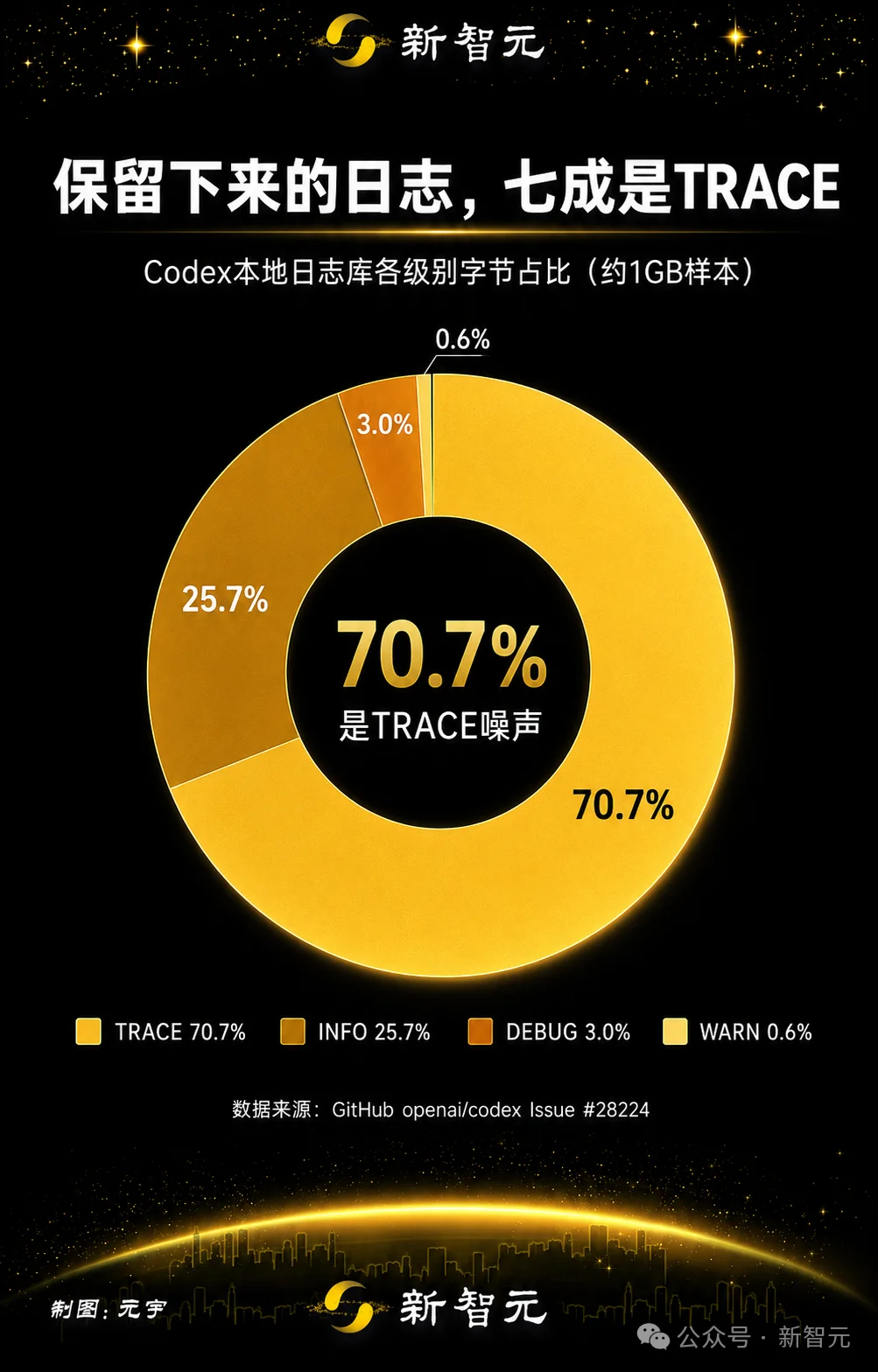
七成写入是TRACE噪声,加上镜像遥测,96%全是没人会看的废话。
只有4%,才是真正有意义的内容。
报告者翻了Codex仓库,发现这类「日志无界增长」的Issue,至少有9个。
#17320,流式响应期间WAL狂写,根因和这次一模一样,都是TRACE无视RUST_LOG。
#24275,桌面版logs_2.sqlite疯涨。
#22444,WAL无限增长还占着空间不释放。
#26374,一天写0.75GB,没轮转。
#27911,一个4KB的goals_1.sqlite,被写成11MB/s。
#20563,进程闲着也狂写盘。
#27020,Windows上磁盘活跃100%。
最早的源头能追到#12969,正是这个PR把SQLite反馈日志的sink按TRACE级别接了进来。
一个4KB的数据库被写成每秒11MB,单独拎出来都够写一篇。而它和640TB那个,是同一个产品、同一套遥测体系的症状。
这说明Codex的日志和遥测系统,从一开始就没有「资源预算」这个概念。
整个赛道都在卷token预算、卷上下文长度、卷模型能力。
但几乎没人问:一个常驻用户机器、7×24小时跑的Agent,它的磁盘、内存、CPU预算,谁来管?
6月14日报上GitHub,6月23日,报告者更新了一条:三个PR已合并,据他自己的Codex反馈能减少约85%日志,于是宣布关闭。
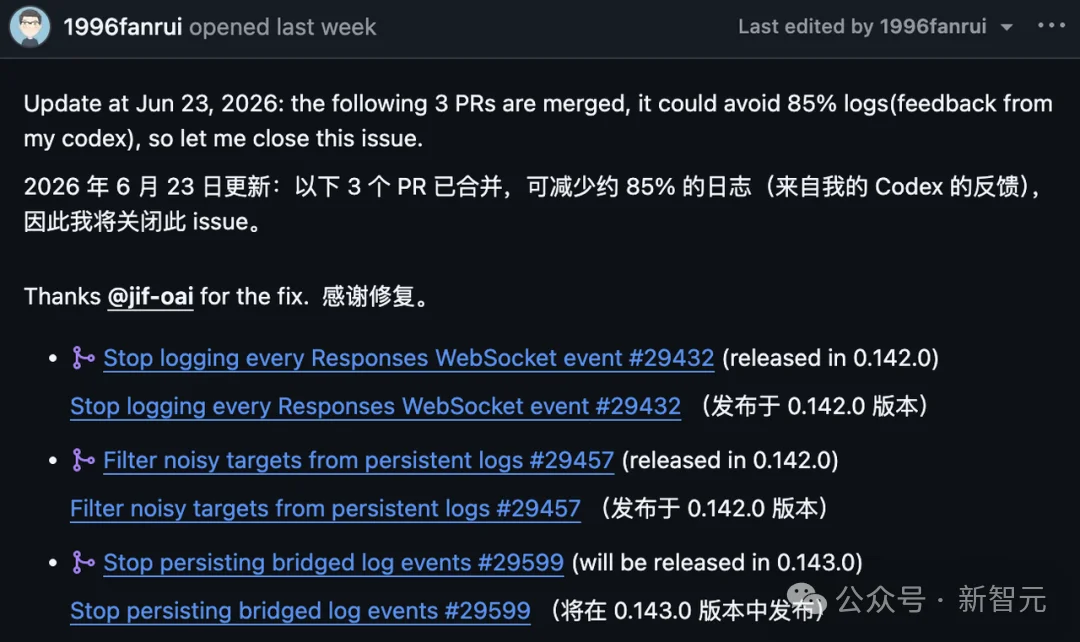
先说这个85%——不是100%,而且还没全落地。
三个修复里,#29432、#29457已随0.142.0发布,砍掉逐条WebSocket日志和噪声目标;第三个#29599停掉另一类被桥接进来的冗余日志,要等0.143.0才上线。
即便三个全到位,剩下约15%、一年仍要写约96TB,不过是从「一年烧穿硬盘」降到「六年烧穿硬盘」。
也有人替它辩护:trace日志是按设计存下来调试的,不算bug,对OpenAI也确实方便追查边缘case。
但问题恰恰在这儿:拿付费用户的SSD寿命,给厂商的debug做免费存储,这事,用户同意过吗?
有意思的是,被点名的并不只有Codex。
评论区马上有人补刀:Claude Code也往本地猛写调试日志,有人只好把日志目录软链到内存盘(tmpfs),给SSD续命。
两家旗舰,犯的是同一类毛病。
社区里的评论,很快从一个bug,放大到整个AI编程工具的质量问题。
有人吐槽这些智能体GPU常年跑满、内存动辄70GB,有人干脆给这代软件起了名字:劣质软件。
那位开发者的建议本来极简:给应用设条线,别超过3GB。就这一条线,Codex拖了9个Issue、好几个月才肯画下来。
问题是一个时刻把「AGI」挂在嘴边的公司,为什么会栽在实习工程师都能看出来的问题上?
为什么这毛病能藏这么久,有条评论也说到了点子上。
放十年前,日志开到TRACE,程序当场卡死,当天就被修掉;如今CPU够快、内存够大、磁盘够猛,这点毛病被硬件性能悄悄消化,程序照跑、界面照常、用户无感,直到某天SSD提前报废。
这两年,软件被AI生成的代码塞满,功能越堆越多、抽象层越叠越厚、资源消耗一路狂飙,全靠硬件厂商每年用更快的芯片硬兜。
于是有了一个荒诞循环:软件越写越烂,硬件越造越猛。用户揣着「好像没变慢」的错觉掏钱换新机,其实只是新机器勉强撑住了更烂的软件。
一个小bug当然无法压垮OpenAI。但Codex和Claude Code的竞争已经从模型能力,蔓延到了开发者工作流的入口。
在这条战线上,快速作出改变,响应开发者需求从来不是加分项,只是入场券。
参考资料:
https://github.com/openai/codex/issues/28224
https://news.ycombinator.com/item?id=48626930
文章来自于"新智元",作者 "元宇"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
