
Agent-to-Sim:从日常视频学习并模拟三维代理的交互行为
Agent-to-Sim:从日常视频学习并模拟三维代理的交互行为Agent-to-Sim (ATS) 是一个创新的三维模拟系统,能够从日常视频集合中学习三维代理的交互行为模型,由 Meta Codec Avatar 实验室主导研发。
来自主题: AI技术研报
6649 点击 2024-11-01 12:19
 搜索
搜索
Agent-to-Sim (ATS) 是一个创新的三维模拟系统,能够从日常视频集合中学习三维代理的交互行为模型,由 Meta Codec Avatar 实验室主导研发。

OmniParser 是由微软研究院提出的一个创新性工具,旨在通过解析用户界面截图来增强基于视觉的图形用户界面(GUI)代理的性能。

来自华东师范大学、南洋理工和中科院等高校的联合研究团队提出了一种新颖的人工智能教育框架“场景-对象-评估”(SOE),旨在利用大型语言模型(LLMs)构建能够模拟人类学生行为和个体差异的虚拟学生代理(LVSA)。

一个简单但具有挑战性的基准

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

DeepMind 公布其正在开发一套创新的音频生成技术细节,也就是NotebookLM背后使用的语音技术。使 AI 能够生成更加自然的对话和高质量的音频。这些技术不仅提升了语音助手的交互性,还帮助多种应用在语音合成和对话生成上取得更大进展。

自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。

个性化精品数字人(Personalized Talking Face Generation)强调合成的数字人视频在感官上与真人具有极高的相似性(不管是说话人的外表还是神态)。

大模型固然性能强大,但限制也颇多。如果想在端侧塞进 405B 这种级别的大模型,那真是小庙供不起大菩萨。近段时间,小模型正在逐渐赢得人们更多关注。这一趋势不仅出现在语言模型领域,也出现在了机器人领域。

清华大学推出的SonicSim平台和SonicSet数据集针对动态声源的语音处理研究提供了强有力的工具和数据支持,有效降低了数据采集成本,实验证明这些工具能有效提升模型在真实环境中的性能。
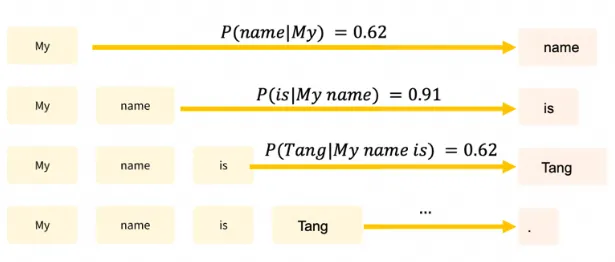
文章详细讨论了如何确保大型语言模型(LLMs)输出结构化的JSON格式,这对于提高数据处理的自动化程度和系统的互操作性至关重要。

在当前大语言模型(LLM)蓬勃发展的环境下,Prompt工程师们面临着一个两难困境:要么使用像LangChain这样功能强大但学习曲线陡峭的框架,要么选择自动化程度更高DSPy但牺牲了对提示词精确控制的工具。IBM研究院和UC Davis大学最近推出的PDL(Prompt Declaration Language,提示词声明语言)或许打破了这个困境,让AI开发者能真正拿回Prompt的控制权。

这两天Github上有一个项目火了。可用于生产环境GraphRAG的开源UI项目kotaemon,更新不到两天后已经有6.6KStar,昨日新增1.3KStar已位居Github Trending榜首。周末抽空部署了一下,还挺简单,推荐给大家。

Max Tegmark团队又出神作了!他们发现,LLM中居然存在人类大脑结构一样的脑叶分区,分为数学/代码、短文本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非人类独有,硅基生命也从属这一法则。

GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。

近期,港中大(深圳)联手趣丸科技联合推出了新一代大规模声音克隆 TTS 模型 ——MaskGCT。该模型在包含 10 万小时多语言数据的 Emilia 数据集上进行训练,展现出超自然的语音克隆、风格迁移以及跨语言生成能力,同时保持了较强的稳定性。MaskGCT 已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统 Amphion 发布。
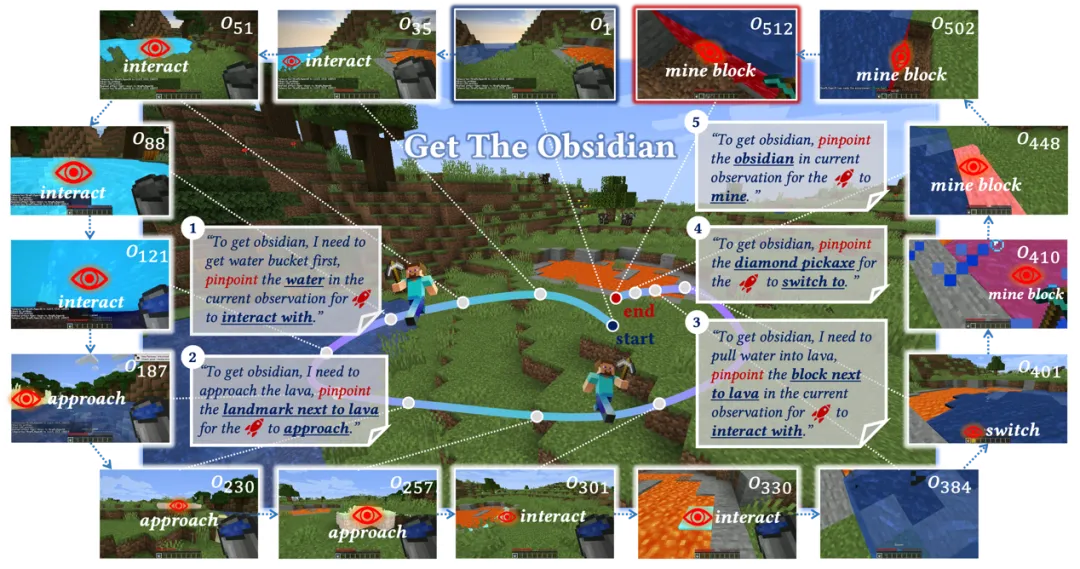
在游戏和机器人研究领域,让智能体在开放世界环境中实现有效的交互,一直是令人兴奋却困难重重的挑战。
Open-Sora-Plan迎来又一次升级。新的Open-Sora-Plan v1.3.0版本引入了五个新特性:性能更强、成本更低的WFVAE;Prompt refiner;高质量数据清洗策略;全新稀疏注意力的DiT,以及动态分辨率、动态时长的支持。

让大模型能快速、准确、高效地吸收新知识!

TimeMixer++是一个创新的时间序列分析模型,通过多尺度和多分辨率的方法在多个任务上超越了现有模型,展示了时间序列分析的新视角,在预测和分类等任务带来了更高的准确性和灵活性。

Janus 是 DeepSeek AI 开发的一个先进的多模态理解和生成框架,它通过创新性地解耦视觉编码路径来应对多模态理解和生成任务之间的需求冲突。

LLM统一了语言生成任务,图像生成可以吗?就在刚刚,智源推出了全新扩散模型架构OmniGen,单个模型就能生成图像,彻底告别繁琐工作流!

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。

随着2024年生成式AI大爆发,推理端成本呈指数级激增,推动了泛智能硬件端持续增长,“端云混合AI部署”模式正走向主流,端侧智能则加速了终端“换机热潮”:AI PC、AI手机、AIoT设备、智能座舱。
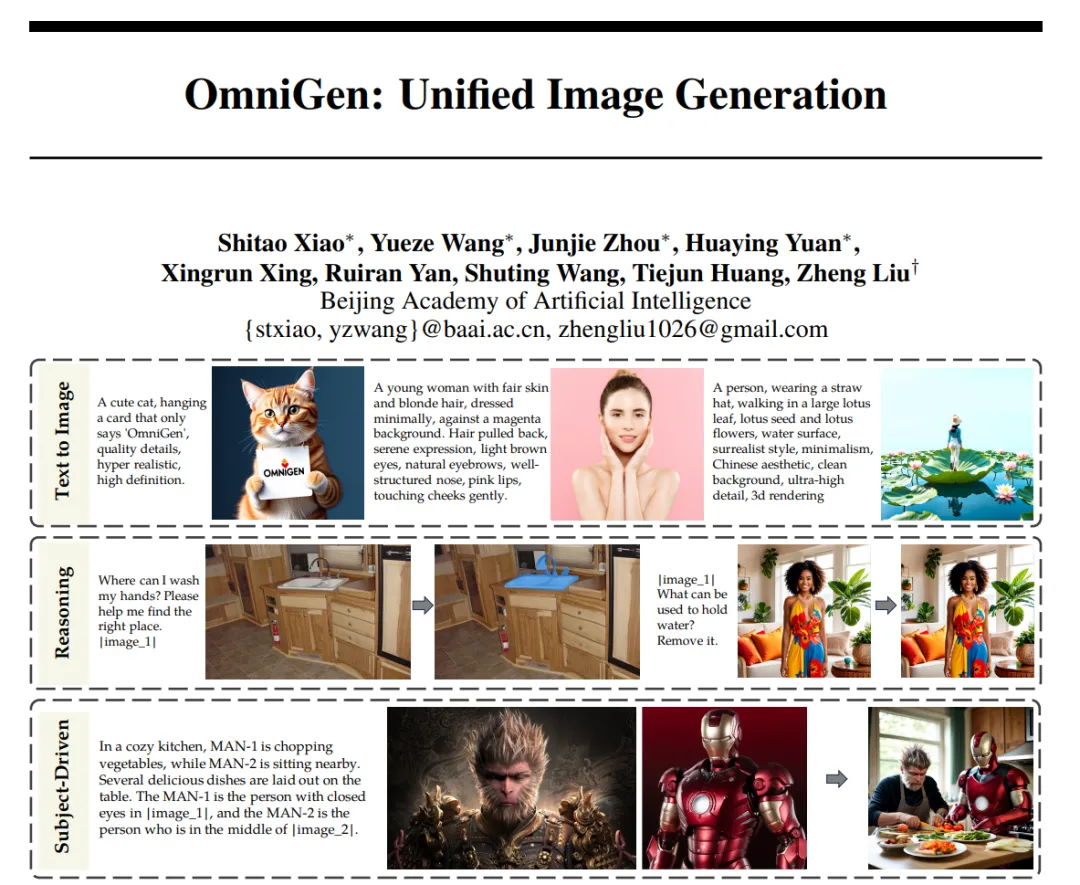
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。

在当前内卷严重的实时目标检测 (Real-time Object Detection) 领域,性能与效率始终是难以平衡的核心问题。绝大多数现有的 SOTA 方法仅依赖于更先进的模块替换或训练策略,导致性能逐渐趋于饱和。

前Neuralink总裁创立的脑机接口公司Science Corporation,正在开发一种名为「Prima」的芯片技术。初步试验结果表明,38名患者中,有81%的患者视力得到了大幅度的改善。几位知名眼科医生都直称:「这是第一个有可能成功恢复AMD患者视力的重大进展!」
吴恩达老师提出了一种反思翻译的大语言模型 (LLM) AI 翻译工作流程

分享一篇近期由华为和阿卜杜拉国王科技大学合作完成的一项生信分析与大语言模型相结合的工作,相关成果发表在《Advanced Science》上。
TS-Reasoner是一个创新的多步推理框架,结合了大型语言模型的上下文学习和推理能力,通过程序化多步推理、模块化设计、自定义模块生成和多领域数据集评估,有效提高了复杂时间序列任务的推理能力和准确性。实验结果表明,TS-Reasoner在金融决策、能源负载预测和因果关系挖掘等多个任务上,相较于现有方法具有显著的性能优势。