
一张显卡看遍天下电影!智源联合高校开源Video-XL打破长视频理解极限,95%准确率刷爆纪录
一张显卡看遍天下电影!智源联合高校开源Video-XL打破长视频理解极限,95%准确率刷爆纪录长视频理解迎来新纪元!智源联手国内多所顶尖高校,推出了超长视频理解大模型Video-XL。仅用一张80G显卡处理小时级视频,未来AI看懂电影再也不是难事。
来自主题: AI技术研报
8119 点击 2024-10-28 17:38
 搜索
搜索
长视频理解迎来新纪元!智源联手国内多所顶尖高校,推出了超长视频理解大模型Video-XL。仅用一张80G显卡处理小时级视频,未来AI看懂电影再也不是难事。
Transformer解决了三体问题?Meta研究者发现,132年前的数学难题——发现全局李雅普诺夫函数,可以被Transformer解决了。「我们不认为Transformer是在推理,它可能是出于对数学问题的深刻理解,产生了超级直觉。」AI可以搞基础数学研究了,陶哲轩预言再成真。
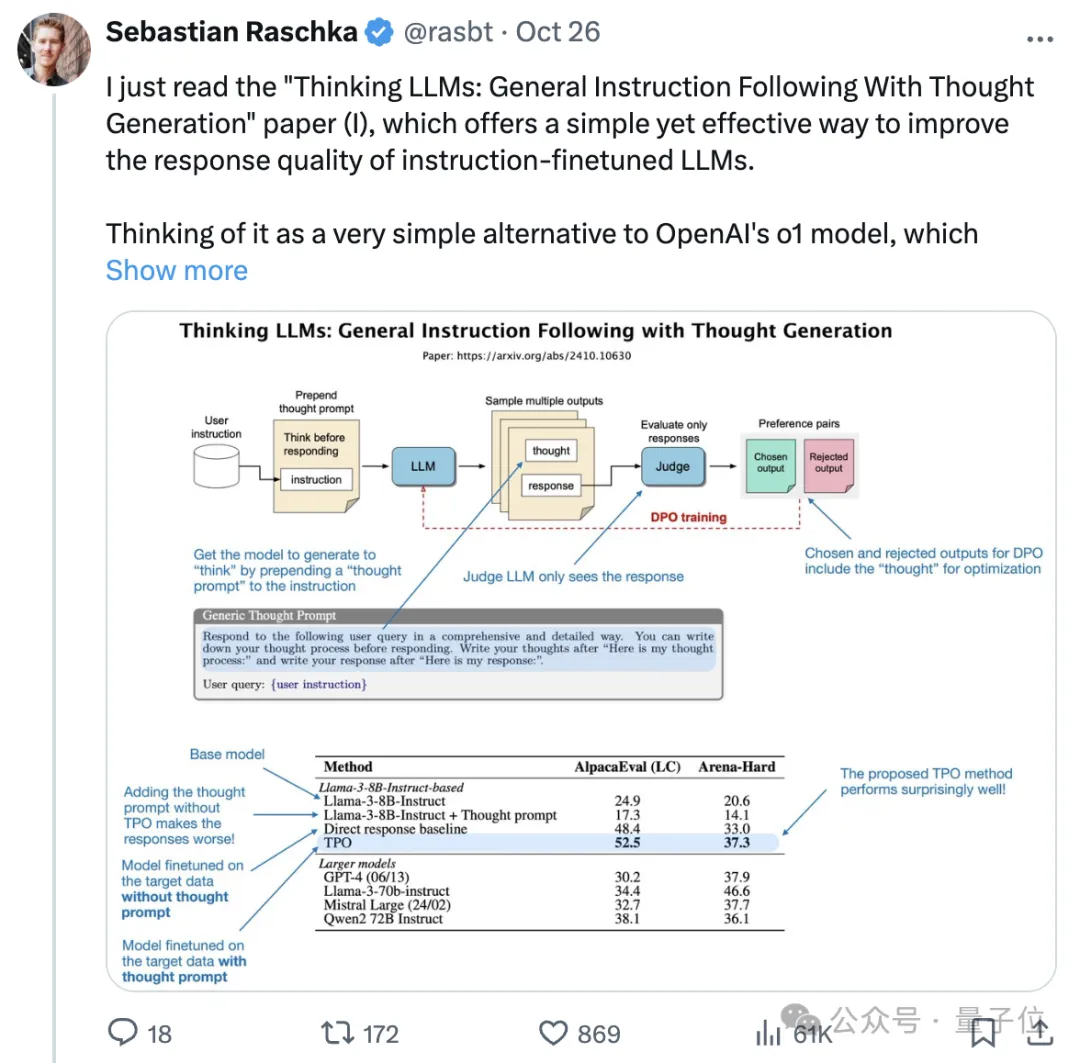
OpenAI-o1替代品来了,大模型能根据任务复杂度进行不同时间的思考。 不限于推理性的逻辑或数学任务,一般问答也能思考的那种。 最近畅销书《Python机器学习》作者Sebastian Raschka推荐了一项新研究,被网友们齐刷刷码住了。

仅需1块80G显卡,大模型理解小时级超长视频。 智源研究院联合上海交通大学、中国人民大学、北京大学和北京邮电大学等多所高校带来最新成果超长视频理解大模型Video-XL。

近日,天桥脑科学研究院和普林斯顿大学等多所研究机构发布了一篇研究论文,详细阐述了长期记忆对 AI 自我进化的重要性,并且他们还提出了自己的实现框架 —— 基于多智能体的 Omne,其在 GAIA 基准上取得了第一名的成绩。

近日,极佳科技联合中国科学院自动化研究所、理想汽车、北京大学、慕尼黑工业大学等单位提出DriveDreamer4D,是首个利用世界模型增强 4D 驾驶场景重建效果的工作。

视频内容的快速增长给视频检索技术,特别是细粒度视频片段检索(VCMR),带来了巨大挑战。VCMR 要求系统根据文本查询从视频库中精准定位视频中的匹配片段,需具备跨模态理解和细粒度视频理解能力。

近日,智谱在公众号陆续放出电脑版本与手机版本的AI Agent实操视频:

在人工智能技术快速发展的今天,大语言模型(LLM)已经展现出惊人的能力。然而,让这些模型生成规范的结构化输出仍然是一个难以攻克的技术难题。不论是在开发自动化工具、构建特定领域的解决方案,还是在进行开发工具集成时,都迫切需要LLM能够产生格式严格、内容可靠的输出。

扩散模型(Diffusion Models, DMs)已经成为文本到图像生成领域的核心技术之一。凭借其卓越的性能,这些模型可以生成高质量的图像,广泛应用于各类创作场景,如艺术设计、广告生成等。
今年 4 月,斯坦福大学推出了一款利用大语言模型(LLM)辅助编写类维基百科文章的神器。它就是开源的 STORM,可以在三分钟左右将你输入的主题转换为长篇文章或者研究论文,并能够以 PDF 格式直接下载。

AI评估AI可靠吗?来自Meta、KAUST团队的最新研究中,提出了Agent-as-a-Judge框架,证实了智能体系统能够以类人的方式评估。它不仅减少97%成本和时间,还提供丰富的中间反馈。

科幻中的贾维斯,已经离我们不远了。Claude 3.5接管人类电脑掀起了人机交互全新范式,爆料称谷歌同类Project Jarvis预计年底亮相。AI操控电脑已成为微软、苹果等巨头,下一个发力的战场。

时隔近70年,那个用来解决最短路径问题的经典算法——Dijkstra,现在有了新突破:被证明具有普遍最优性(Universal Optimality)。

斯坦福吴佳俊团队与MIT携手打造的最新研究成果,让我们离实时生成开放世界游戏又近了一大步。

在这个信息爆炸的时代,如何让AI生成的视频更具创意,又符合特定需求?

现在,大模型能生成RPG角色扮演游戏了。
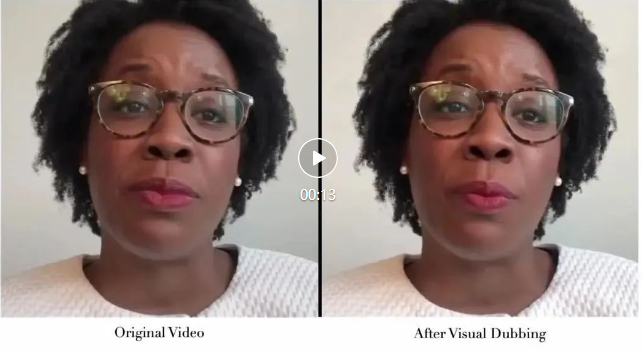
在 AIGC 的热潮下,基于语音驱动的视频口型编辑技术成为了视频内容个性化与智能化的重要手段之一。

最近这几天,让大模型具备控制计算机(包括电脑和手机)的相关研究和应用如雨后春笋般不断涌现。

如果你是一位开放世界或角色扮演游戏的玩家,你一定梦想过一款无限自由的游戏。没有空气墙,没有剧情杀,也没有任何交互限制。

今年的诺奖将物理和化学两个领域的奖项都颁给了AI成果,这究竟代表着怎样的含义,又会产生怎样的影响?Demis Hassabis在本次专访中提出了自己的见解。

OpenAI 最近发布的 o1 模型在数学、代码生成和长程规划等复杂任务上取得了突破性进展,据业内人士分析披露,其关键技术在于基于强化学习的搜索与学习机制。通过迭代式的自举过程,o1 基于现有大语言模型的强大推理能力,生成合理的推理过程,并将这些推理融入到其强化学习训练过程中。
稚晖君表示,这是 1024 的福利。

这两天,Claude 3.5 Sonnet升级版刷爆了朋友圈,满屏都是:它能像人一样操作电脑。 大语言模型(Large Language Model,LLM)能够像人一样操作电脑这件事,看起来蛮炸裂的,但在AI Agent圈子里早已经见多不怪了。
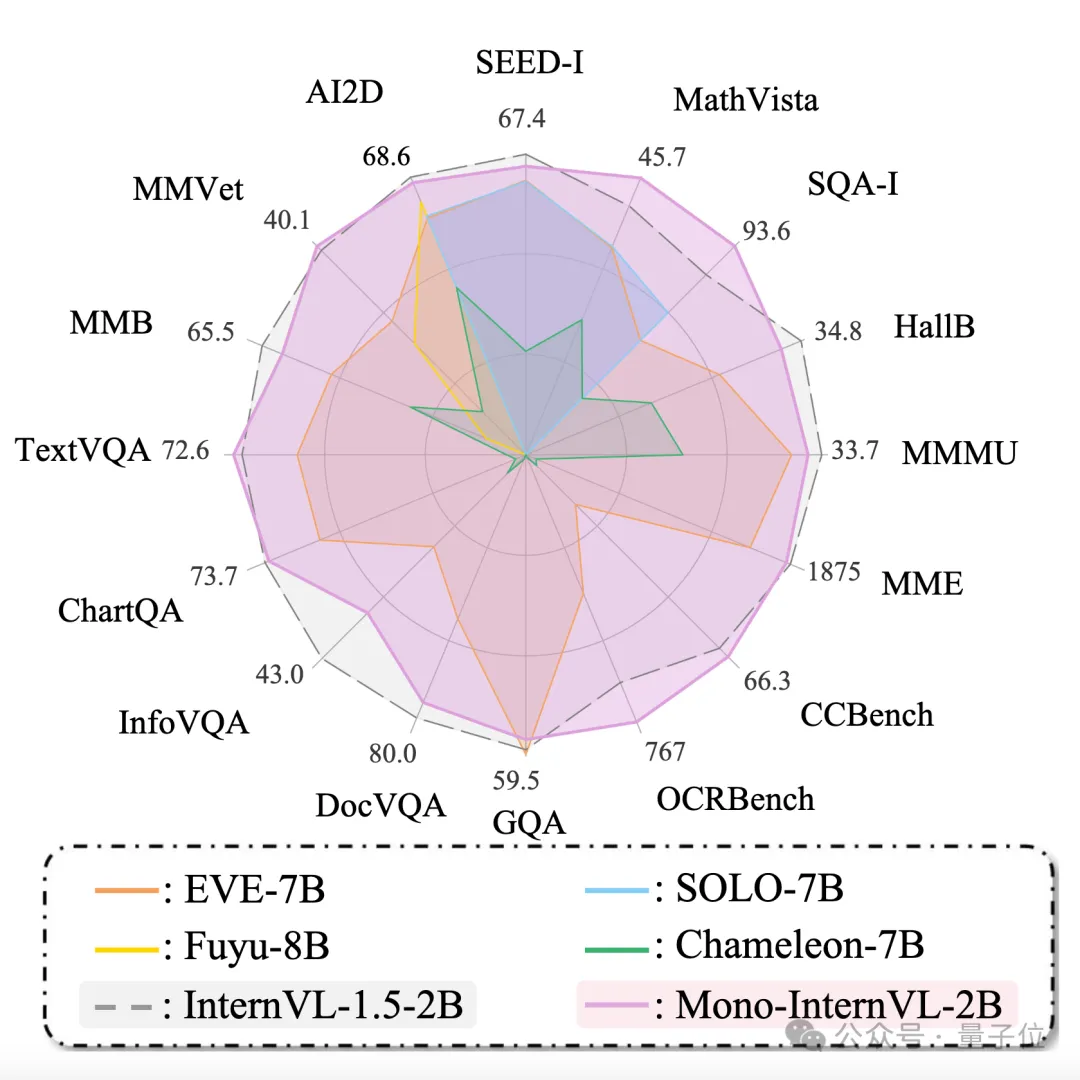
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。

近日,深度学习三巨头之一的Yoshua Bengio,带领团队推出了全新的RNN架构,以大道至简的思想与Transformer一较高下。
「这才是开放研究该有的样子。」 经常刷 arXiv 的同学,你有没有发现页面上多了个新功能?这个新功能(图中的「Hugging Face」按钮)隐藏在「Code, Data, Media」选项卡下,选中之后就可以直达相关的 Hugging Face 论文、模型和数据集。
Zamba2-7B是一款小型语言模型,在保持输出质量的同时,通过创新架构实现了比同类模型更快的推理速度和更低的内存占用,在图像描述等任务上表现出色,能在各种边缘设备和消费级GPU上高效运行。

北京大学的研究人员开发了一种新型多模态框架FakeShield,能够检测图像伪造、定位篡改区域,并提供基于像素和图像语义错误的合理解释,可以提高图像伪造检测的可解释性和泛化能力。

西安电子科大、上海AI Lab等提出多模态融合检测算法E2E-MFD,将图像融合和目标检测整合到一个单阶段、端到端框架中,简化训练的同时,提升目标解析性能。 相关论文已入选顶会NeurlPS 2024 Oral,代码、模型均已开源。