
Nature重磅:AI击败最先进全球传统天气、气候模型,30秒生成22.8天大气模拟,准确预测40年全球变暖趋势
Nature重磅:AI击败最先进全球传统天气、气候模型,30秒生成22.8天大气模拟,准确预测40年全球变暖趋势传统天气预测、气候模拟,正被 AI 颠覆
来自主题: AI技术研报
11764 点击 2024-07-23 19:33
 搜索
搜索
传统天气预测、气候模拟,正被 AI 颠覆

大模型迈入“小而强”时代。

近年,短视频生态的赛道迅猛崛起,围绕短视频而生的创作编辑工具在不断涌现,美图公司旗下专业手机视频编辑工具 ——Wink,凭借独创的视频画质修复能力独占鳌头,海内外用户量持续攀升。

近日,MIT CSAIL 的一个研究团队(一作为 MIT 在读博士陈博远)成功地将全序列扩散模型与下一 token 模型的强大能力统合到了一起,提出了一种训练和采样范式:Diffusion Forcing(DF)。
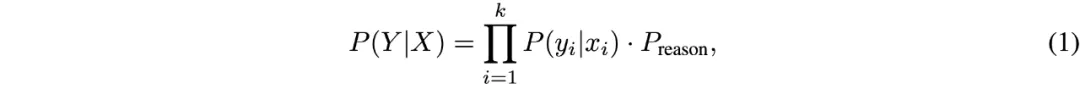
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。

Llama 3.1 终于现身了,不过出处却不是 Meta 官方。
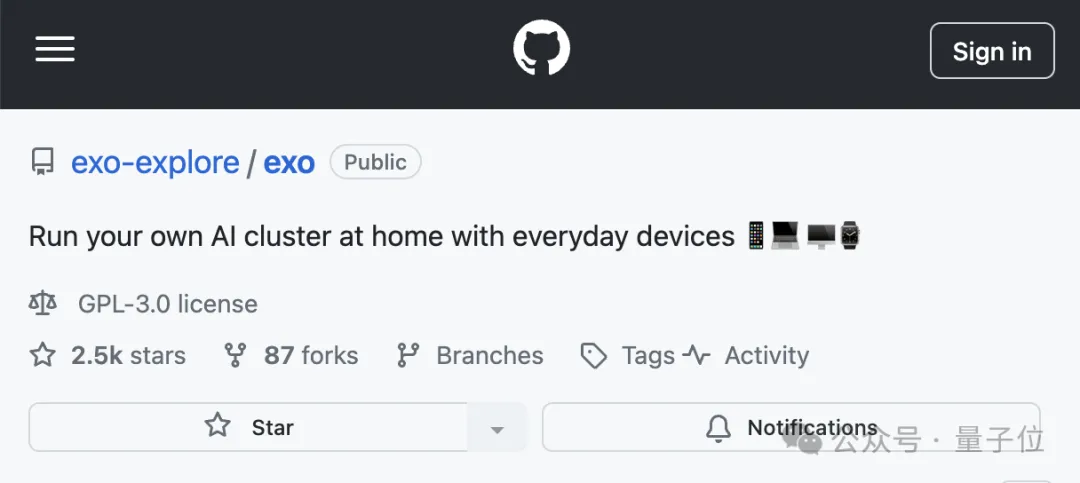
不用H100,三台苹果电脑就能带动400B大模型。 背后的功臣,是GitHub上的一个开源分布式AI推理框架,已经斩获了2.5k星标。

超逼真的机器人小镇来了! 在这里,机器人可以像人一样在超市里购物

Scaling Law还没走到尽头,「小模型」逐渐成为科技巨头们的追赶趋势。Meta最近发布的MobileLLM系列,规模甚至降低到了1B以下,两个版本分别只有125M和350M参数,但却实现了比更大规模模型更优的性能。

多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。

数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。

具身智能狂潮降临的一年多里,物理世界与信息的生产与交互方式发生着革命性变化。

家人们,消除“视频闪烁”(比如画面突然一白)有新招了!

针对视觉-语言预训练(Vision-Language Pretraining, VLP)模型的对抗攻击,现有的研究往往仅关注对抗轨迹中对抗样本周围的多样性,但这些对抗样本高度依赖于代理模型生成,存在代理模型过拟合的风险。
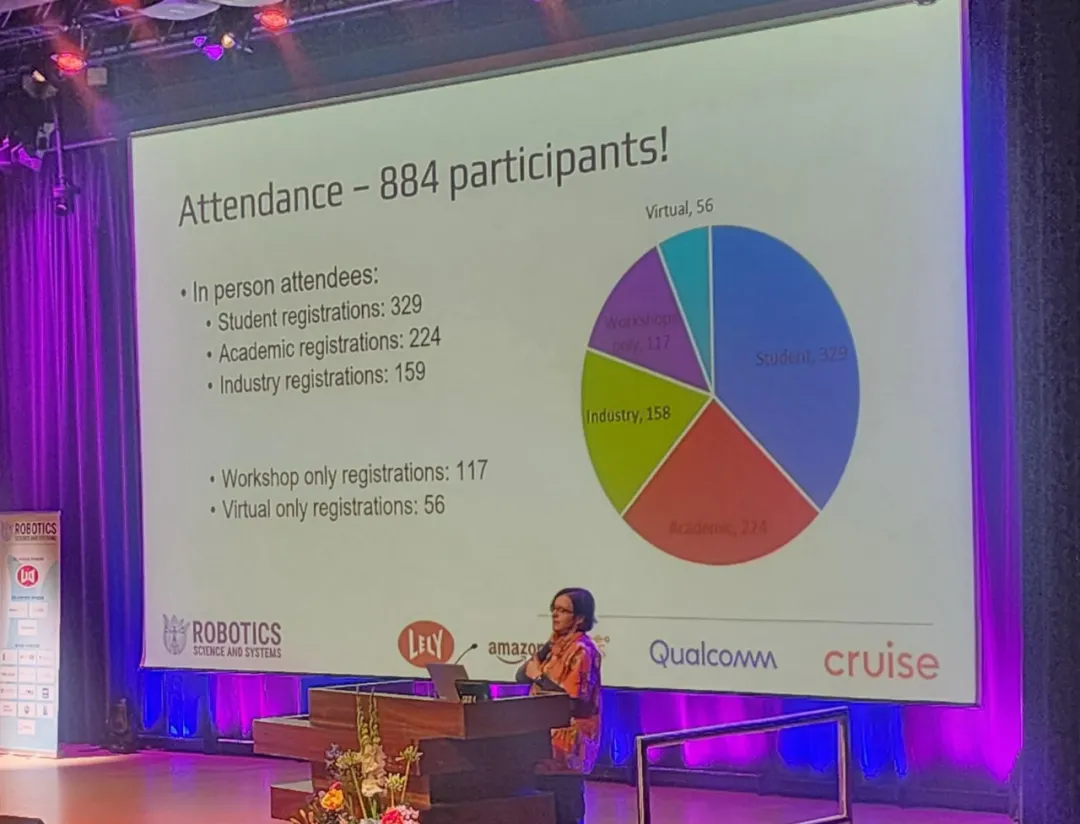
近日,机器人领域著名会议 RSS(Robotics: Science and Systems) 2024 在荷兰代尔夫特理工大学圆满落幕。

「通过系统优化软件的帮助,开发的门槛会被降低,各种不同硬件会得到统一,让技术生态得到发展。

前谷歌科学家Yi Tay重磅推出「LLM时代的模型架构」系列博客,首篇博文的话题关于:基于encoder-only架构的BERT是如何被基于encoder-decoder架构的T5所取代的,分析了BERT灭绝的始末以及不同架构模型的优缺点,以史为鉴,对于未来的创新具有重要意义。

AlphaFold 3的论文太晦涩?没关系,斯坦福大学的两位博士生「图解」AlphaFold 3 ,将模型架构可视化,同时不遗漏任何一个细节。

小模型时代来了?OpenAI带着GPT-4o mini首次入局小模型战场,Mistral AI、HuggingFace本周接连发布了小模型。如今,苹果也发布了70亿参数小模型DCLM,性能碾压Mistral-7B。

在信息爆炸的当今时代,我们如何从浩如烟海的数据中探寻深层次的联系呢?

小模型成趋势?
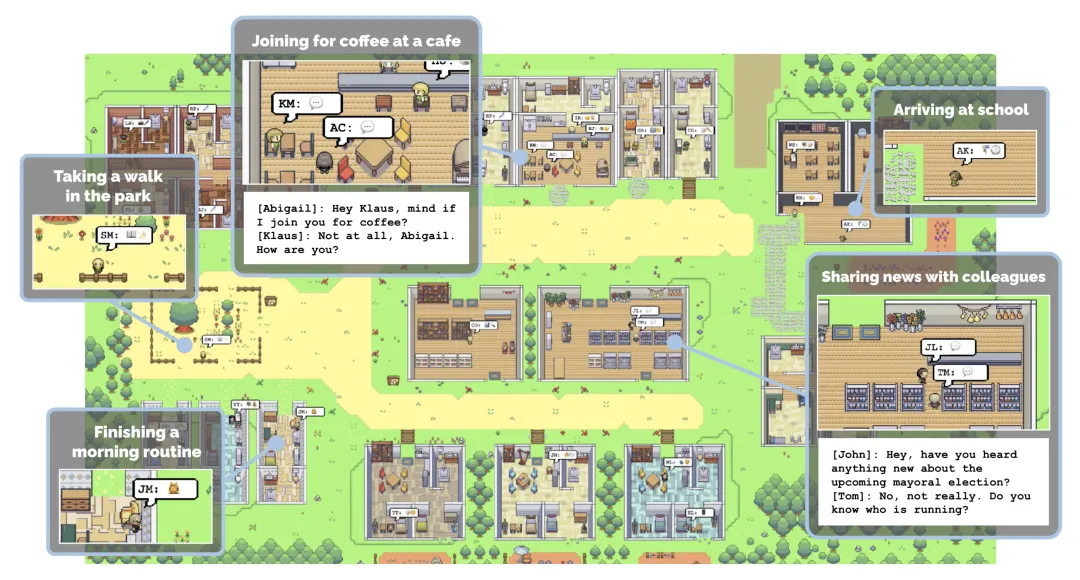
首个专为各种机器人设计的模拟互动 3D 社会。
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。

低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。

GPT-4o mini头把交椅还未坐热,Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。

AI经过多轮“自我提升”,能力不增反降?

著名AI学者、斯坦福大学教授吴恩达提出了AI Agent的四种设计方式后,Agentic Workflow(智能体工作流)立即火爆全球,多个行业都在实践智能体工作流的应用,并推动了新的Agentic AI探索热潮。
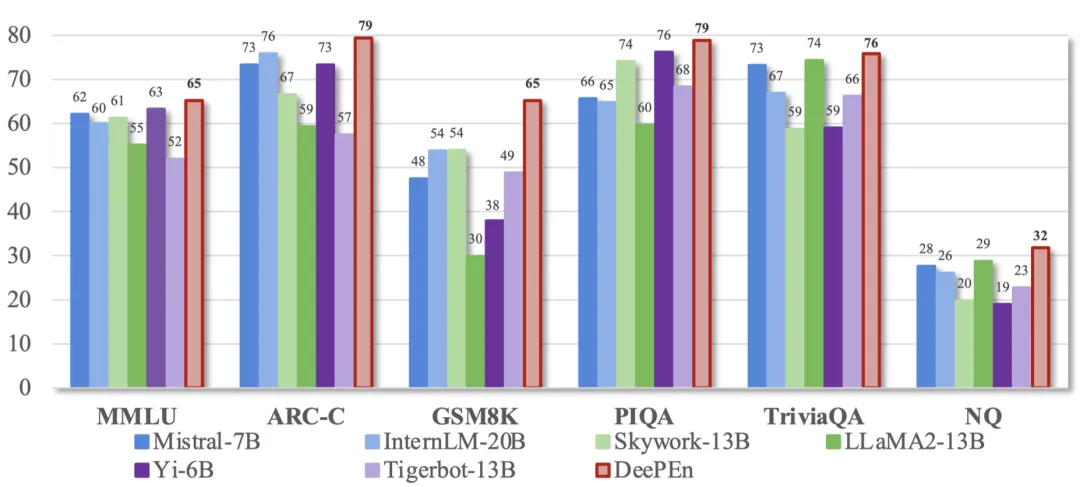
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。

MoE 因其在训推流程中低销高效的特点,近两年在大语言模型领域大放异彩。作为 MoE 的灵魂,专家如何能够发挥出最大的学习潜能,相关的研究与讨论层出不穷。此前,华为 GTS AI 计算 Lab 的研究团队提出了 LocMoE ,包括新颖的路由网络结构、辅助降低通信开销的本地性 loss 等,引发了广泛关注。

大模型开源的热潮下,隐藏着诸多问题,从定义的模糊到实际开放内容的局限性,Lecun再陷Meta大模型是否真开源的质疑风波只是冰山一角。