
MIT等惊人发现:全世界AI已学会欺骗人类!背刺人类盟友,佯攻击败99.8%玩家
MIT等惊人发现:全世界AI已学会欺骗人类!背刺人类盟友,佯攻击败99.8%玩家AI教父Hinton的担心,不是没有道理。
来自主题: AI技术研报
6755 点击 2024-05-14 10:45
 搜索
搜索
AI教父Hinton的担心,不是没有道理。
这周既没有GPT-5,也没有搜索引擎的发布,不过,OpenAI也是没闲着。

关于大模型分词(tokenization),大神Karpathy刚刚推荐了一篇必读新论文。
OpenAI发布会前一天,员工集体发疯中……上演大型套娃行为艺术。

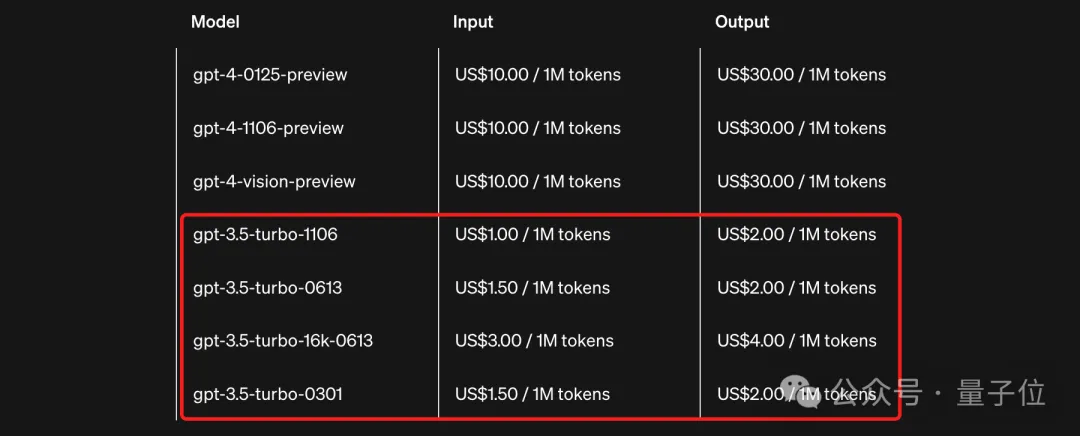
猛然间,大模型圈掀起一股“降价风潮”。

随着深度学习大语言模型的越来越火爆,大语言模型越做越大,使得其推理成本也水涨船高。模型量化,成为一个热门的研究课题。

提高 GPU 利用率,就是这么简单。

5 月 11 日,在上海市浦东新区科技和经济委员会指导下,由中国(上海)自由贸易试验区管理委员会金桥管理局、上海市浦东新区产业发展促进中心、上海市浦东新区投资促进二中心、上海金桥(集团)有限公司主办,上海浦东科技创业中心、机器之心(上海)科技有限公司承办

世界模型,即通过预测未来的范式对数字世界和物理世界进行理解,是通往实现通用人工智能(AGI)的关键路径之一。

在过去的一年多里,无论你是否身处科技行业,都能感受到一种强烈的趋势:人工智能正在重塑每个人的生活。

36氪获悉,AI医学影像企业「深智透医」(简称“深透”,Subtle Medical Inc.)近日完成B+轮近千万美元融资,由老股东Fusion Fund,新股东嘉加资本(ENVISIONX Capital)、蓝驰创投硅谷总部基金Bluerun Ventures、上海文周投资及其它亚太区域战略合作方共同投资。本轮融资将用于加速AI产品的全球商业落地及研发创新。

本文基于数势科技创始人&CEO黎科峰博士,百川智能联合创始人焦可,腾讯研究院副院长刘琼,蓝驰创投投资合伙人、TGO鲲鹏会学员石建平以及实在智能联合创始人、CMO张俊九等五位行业大咖在InfoQ主办的QCon全球软件开发大会的圆桌讨论整理。

AI究竟可以多大程度提升创新药开发成功率,近日波士顿咨询(BCG)在《 Drug Discovery Today 》上一篇论文给出了答案

「如果这可以重现的话,这就是我们所知的世界末日!功能建模的新时代已经开始。」欧洲分子生物学实验室(EMBL)的科学家 Jan Kosinski 发推文表示。他在 AlphaFold 3 发布后,立刻用它做了一系列简单的测试,并把相关结果发在了 X 上。

众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。

基于 Diffusion Transformer(DiT)又迎来一大力作「Flag-DiT」,这次要将图像、视频、音频和 3D「一网打尽」。

大模型回答如何更可靠?MIT研究团队设计出「共识博弈」,将数学家常用的博弈论引入LLM改进中。没想到,LLaMA-7B的表现,击败了LLaMA-65B,甚至与PaLM-540B相媲美。

最少只需1个3D样例,即可生成3D主题乐园。

微软&清华最新研究,打破GPT系列开创的Decoder-Only架构——
最近OpenAI太反常,消息一会一变,直让人摸不着头脑。
昨天刚刚在顶会ICLR作为特邀演讲(Invited Talk)中“国内唯一”的大模型玩家智谱AI,今天又放出了一个好消息

Richard Sutton 在 「The Bitter Lesson」中做过这样的评价:「从70年的人工智能研究中可以得出的最重要教训是,那些利用计算的通用方法最终是最有效的,而且优势巨大。」

刚刚提出了KAN的MIT物理学家Max Tegmark和北大校友刘子鸣,又有一项重磅研究问世了!团队发现,它们用AI发现了物理学中的新方程,从此,AI很可能被引入物理学研究领域,帮助人类物理学家做出全新的发现。
人类大脑皮层,可以以纳米级分辨率建模了!

当地时间5月7日,ICLR 2024颁发了自大会举办以来的首个「时间检验奖」!

DeepMind新发布的AlphaFold 3是科技圈今天的绝对大热门,成为了Hacker News等许多科技媒体的头版头条。

有数据统计,2022年全年,全国数据中心耗电量达到2700亿千瓦时,占全社会用电量约3%。预计2024年全国数据中心的耗电量将在3400亿至3600亿度之间,到2025年可能增长至4000亿至4400亿度。

自计算机诞生以来,指令集架构一直是计算机体系结构中的核心概念之一。目前市场上主流的指令集架构两大巨头是x86和ARM,前者基本垄断了PC、笔记本电脑和服务器领域,后者则在智能手机和移动终端市场占据主导地位。

2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。

传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。