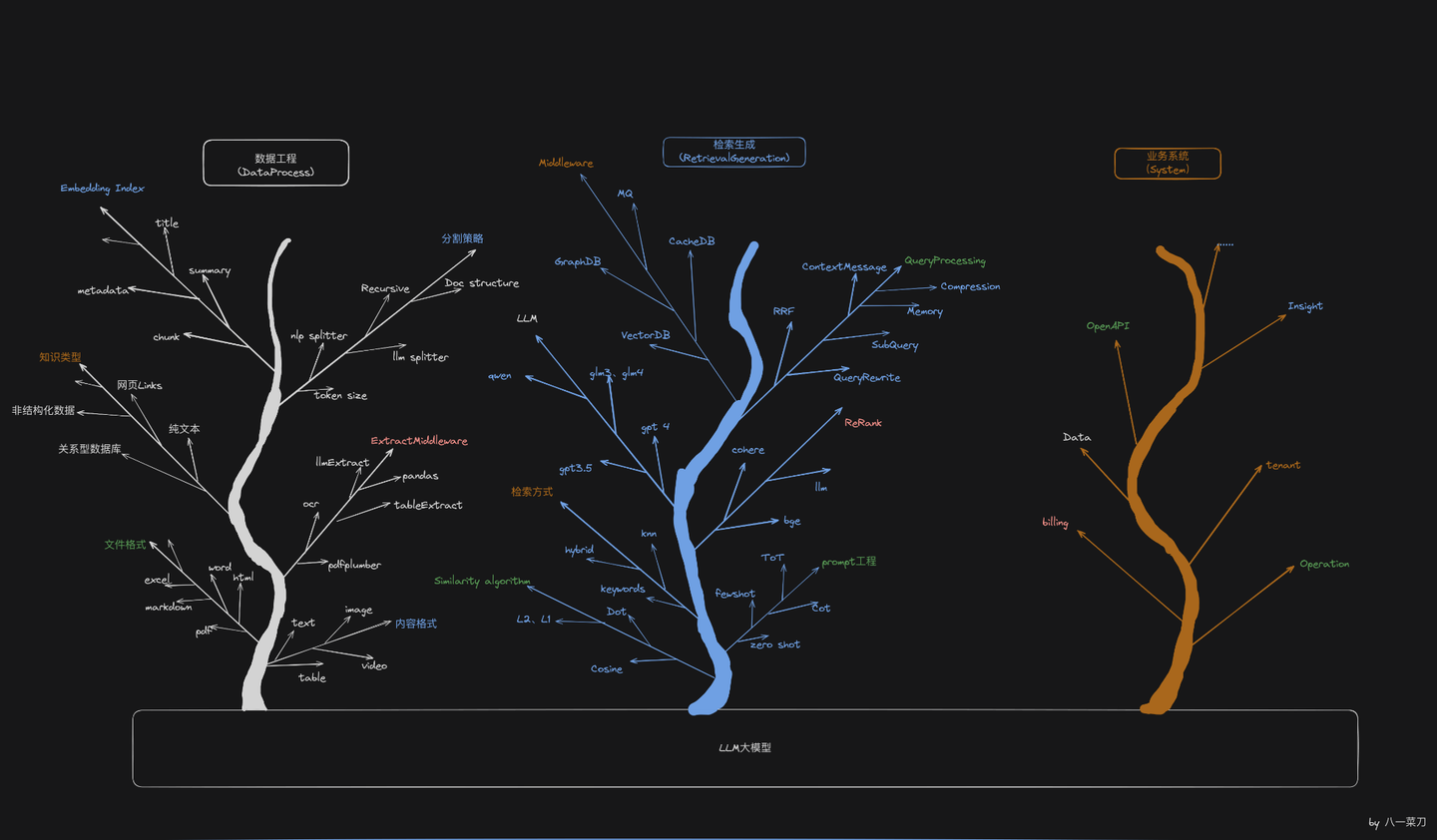
创业:大模型RAG系统三个月的开发心得和思考
创业:大模型RAG系统三个月的开发心得和思考自从和员外上家公司离职后,我们就自己搞公司投入到了RAG大模型的AI产品应用的开发中,这中间有一个春节,前后的总时间大概是三个月左右,在这三个月期间,基本是昼夜兼程啊,到今天3月底结束,产品目前看是有了一个基础的雏形。
来自主题: AI技术研报
9710 点击 2024-05-08 12:26
 搜索
搜索
自从和员外上家公司离职后,我们就自己搞公司投入到了RAG大模型的AI产品应用的开发中,这中间有一个春节,前后的总时间大概是三个月左右,在这三个月期间,基本是昼夜兼程啊,到今天3月底结束,产品目前看是有了一个基础的雏形。

在上一篇文章「Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存」中,我们介绍了Unsloth,这是一个大模型训练加速和显存高效的训练框架,我们已将其整合到Firefly训练框架中,并且对Llama3-8B的训练进行了测试,Unsloth可大幅提升训练速度和减少显存占用。

多模态融合是多模态智能中的基础任务之一。

今年 3 月,以构建大型开源社区而闻名的 AI 初创公司 Hugging Face,挖角前特斯拉科学家 Remi Cadene 来领导一个新的开源机器人项目 ——LeRobot,引起了轰动。

ICLR 全称为国际学习表征会议(International Conference on Learning Representations),今年举办的是第十二届,于 5 月 7 日至 11 日在奥地利维也纳展览会议中心举办。

AI的发展将终结人类学习外语的需求?

如今,AI进步的速度,已经超出了我们对它用途的理解。

「Siri太笨,根本无法与ChatGPT竞争」,前苹果工程师John Burkey曾对Siri的评价如此不堪。

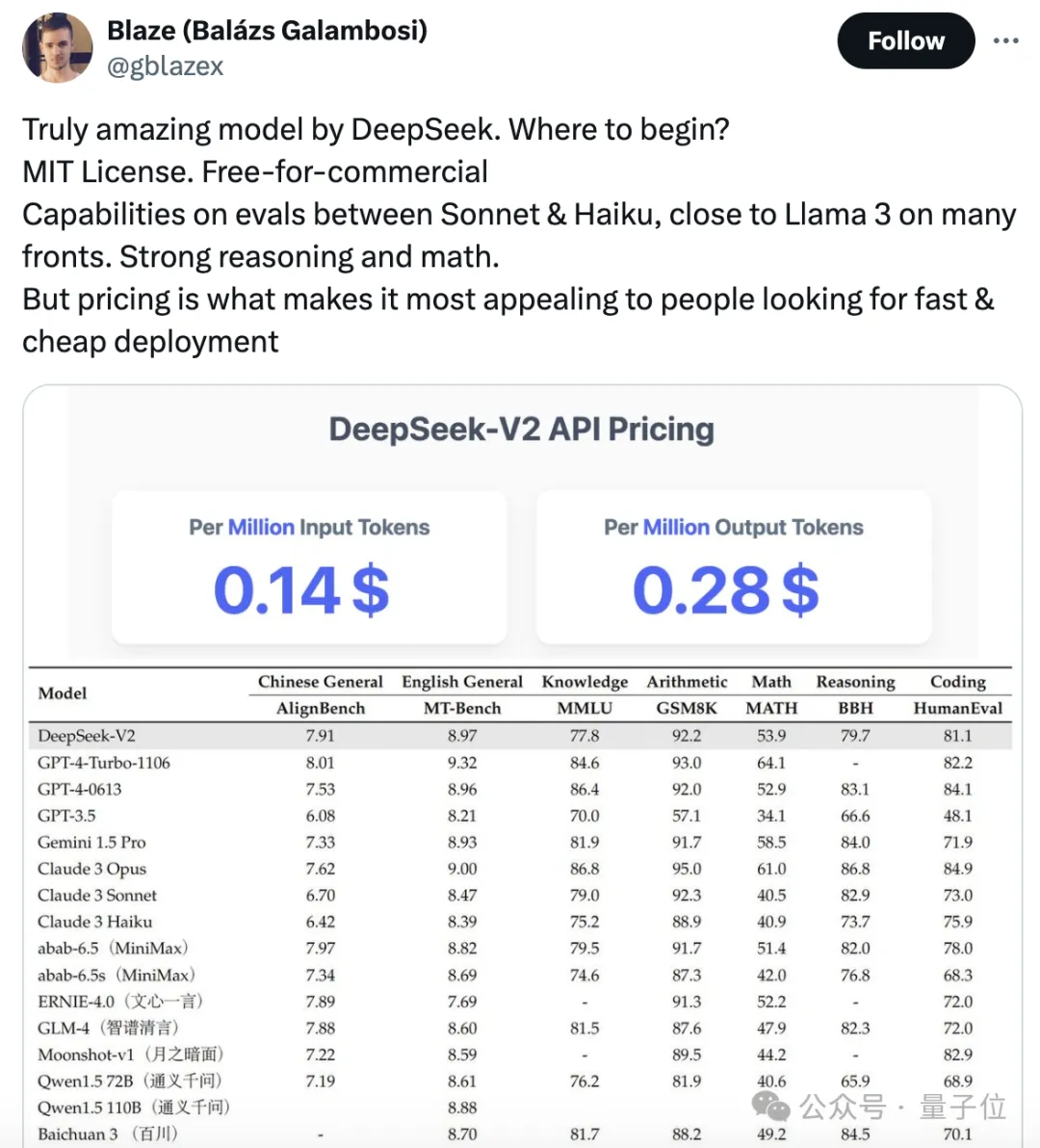
两周前,OpenBMB开源社区联合面壁智能发布领先的开源大模型「Eurux-8x22B 」。相比口碑之作 Llama3-70B,Eurux-8x22B 发布时间更早,综合性能相当,尤其是拥有更强的推理性能——刷新开源大模型推理性能 SOTA,堪称开源大模型中「理科状元」。
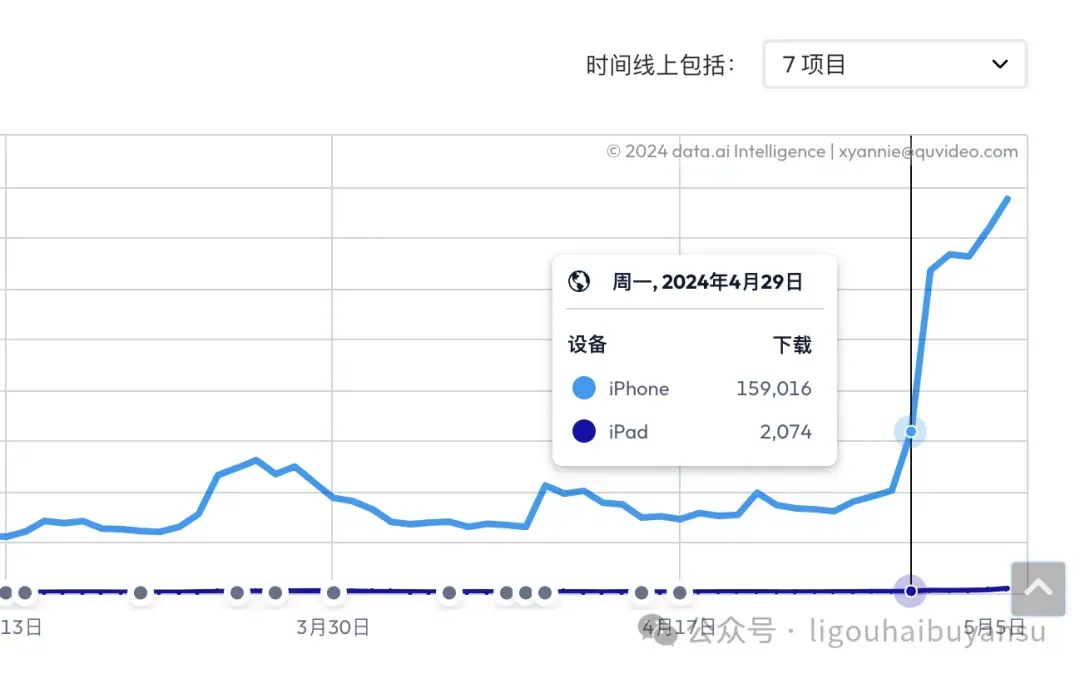
凭借黏土风格的照片生成,Remini 成为五一期间爆火的出圈 AI 应用,日下载量飙升到接近40万次。

大模型又又又被曝出安全问题!

脑机接口(BCI)在科研和应用领域的进展在近期屡屡获得广泛的关注,大家通常都对脑机接口的应用前景有着广泛的畅享。

不需要OpenAI,微软或许也会成为AI领头羊!

快节奏的生活已经成为当今时代的常态,职场中的我们不仅要应对工作中的各种挑战,还要在有限的时间内处理日常生活中的琐事。

在机器学习和计算机视觉中,让机器准确地识别和理解手和物体之间的交互动作,那是相当费劲。

开源大模型领域,又迎来一位强有力的竞争者。
多层感知器(MLP),也被称为全连接前馈神经网络,是当今深度学习模型的基础构建块。MLP 的重要性无论怎样强调都不为过,因为它们是机器学习中用于逼近非线性函数的默认方法。
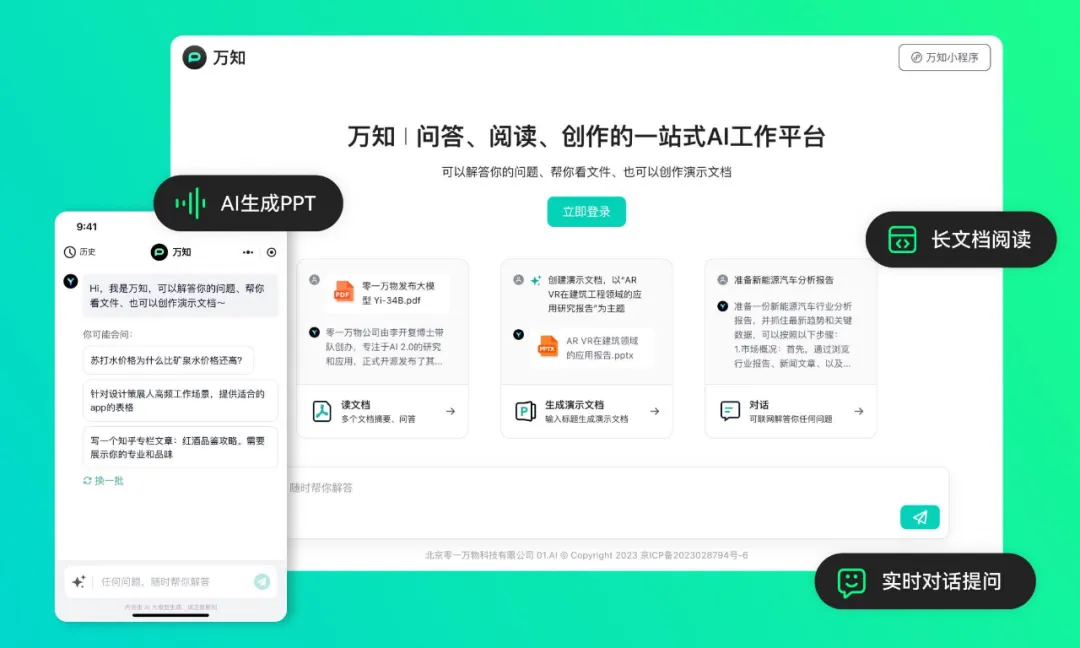
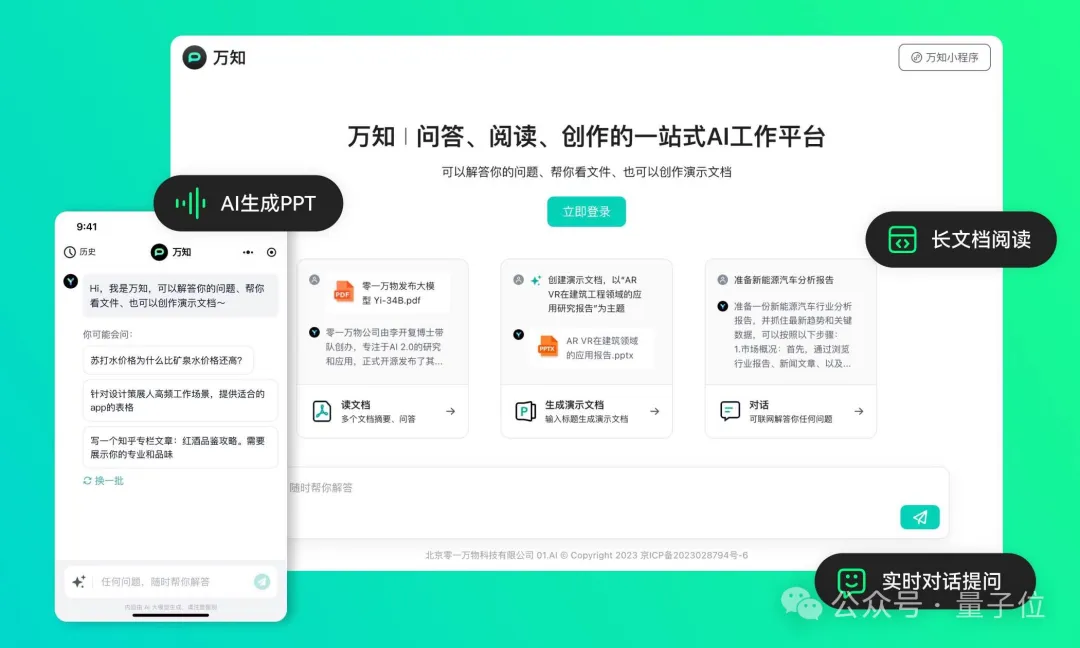
5 月 7 日,零一万物官宣了第一款为中国人量身一站式 AI 工作平台 —— 万知。它可以做会议纪要、周报、写作助手,还可以解读财报、论文等各类文件,帮你做 PPT。这一切,都可以登录一键解决,中英双语,完全免费。

我们知道,球状星团是一种受引力束缚,成员由几万颗到数百万颗恒星组成的古老星团,在外观上大多呈球形,但也有可能受其他天体系统的引力影响使得形状偏离球形。球状星团的动力学演化过程,星族合成路径等是当今天文学界的研究热点。

全球首个超小型多模态AI Agent模型Octopus V3,来自斯坦福大学的NEXA AI团队,让Agent更加智能、快速、能耗及成本降低。
最新国产开源MoE大模型,刚刚亮相就火了。
快节奏的生活已经成为当今时代的常态!
刚被OpenAI开除的泄密者,光速投奔马斯克。

根据路透社5月4日消息,著名华人计算机科学家李飞飞正在建立一家初创公司。这家公司会利用类似人类对视觉数据的处理,使 AI 能够进行高级推理。这种AI算法使用的概念被称为“空间智能”。至于新公司的名字,还没有向外界披露。

过去几年,借助Scaling Laws的魔力,预训练的数据集不断增大,使得大模型的参数量也可以越做越大,从五年前的数十亿参数已经成长到今天的万亿级,在各个自然语言处理任务上的性能也越来越好。

Sora刚发布后没多久,火眼金睛的网友们就发现了不少bug,比如模型对物理世界知之甚少,小狗在走路的时候,两条前腿就出现了交错问题,让人非常出戏。 对于生成视频的真实感来说,物体的交互非常重要,但目前来说,合成真实3D物体在交互中的动态行为仍然非常困难。
近日,来自英国最大的创作者工会SoA公布了一项生成式AI对创意类职业的影响的调查报告。
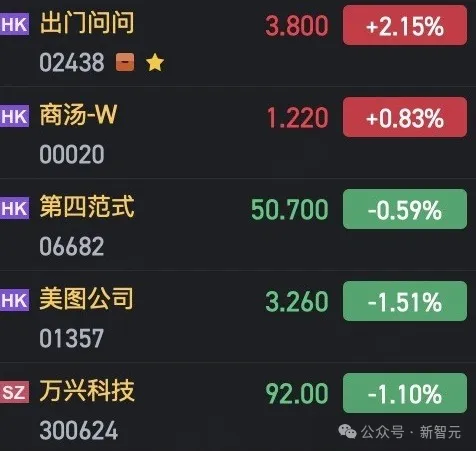
国产大模型荣登AI优质稀缺股,给港股来打样了!

如今的生成式AI在人工智能领域迅猛发展,在计算机视觉中,图像和视频生成技术已日渐成熟,如Midjourney、Stable Video Diffusion [1]等模型广泛应用。然而,三维视觉领域的生成模型仍面临挑战。

我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。