
LeCun上月球?南开、字节开源StoryDiffusion让多图漫画和长视频更连贯
LeCun上月球?南开、字节开源StoryDiffusion让多图漫画和长视频更连贯两天前,图灵奖得主 Yann LeCun 转载了「自己登上月球去探索」的长篇漫画,引起了网友的热议。
来自主题: AI技术研报
11039 点击 2024-05-06 17:47
 搜索
搜索
两天前,图灵奖得主 Yann LeCun 转载了「自己登上月球去探索」的长篇漫画,引起了网友的热议。

特斯拉人形机器人又解锁了新技能! 昨日,Tesla Optimus 官方发布了新的 demo 视频,展示了二代 Optimus 人形机器人的最新进展。

亲爱的Prompt读者朋友们,或许你认为掌握了某种Prompt技术已经可以天下无敌,没什么解决不了的问题啦,那是你还没有进入AI应用的深水区!

如果你生活在中国,你可能不认识ChatGPT,但你一定知道Kimi。

OpenAI要做AI搜索挑战谷歌这件事已经传了很久,传说中的SearchGPT似乎真的要来了。据软件开发者Tibor Blaho爆料,OpenAI 的 AI 搜索产品 Sonic - SNC(SearchGPT)已进入评估阶段,新增多项功能:

作为大模型领域的明星创业公司,月之暗面融资后套现的新闻引发广泛关注和非议。

大模型落地有多火,从业者吴炳坤深有体会。

4月下旬,台积电发布了一种新版本4nm制程工艺——N4C,计划在2025年上线量产。这款工艺产品的核心价值是降低了成本。

大模型发展至今早已火成了一个「概念」。

Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。
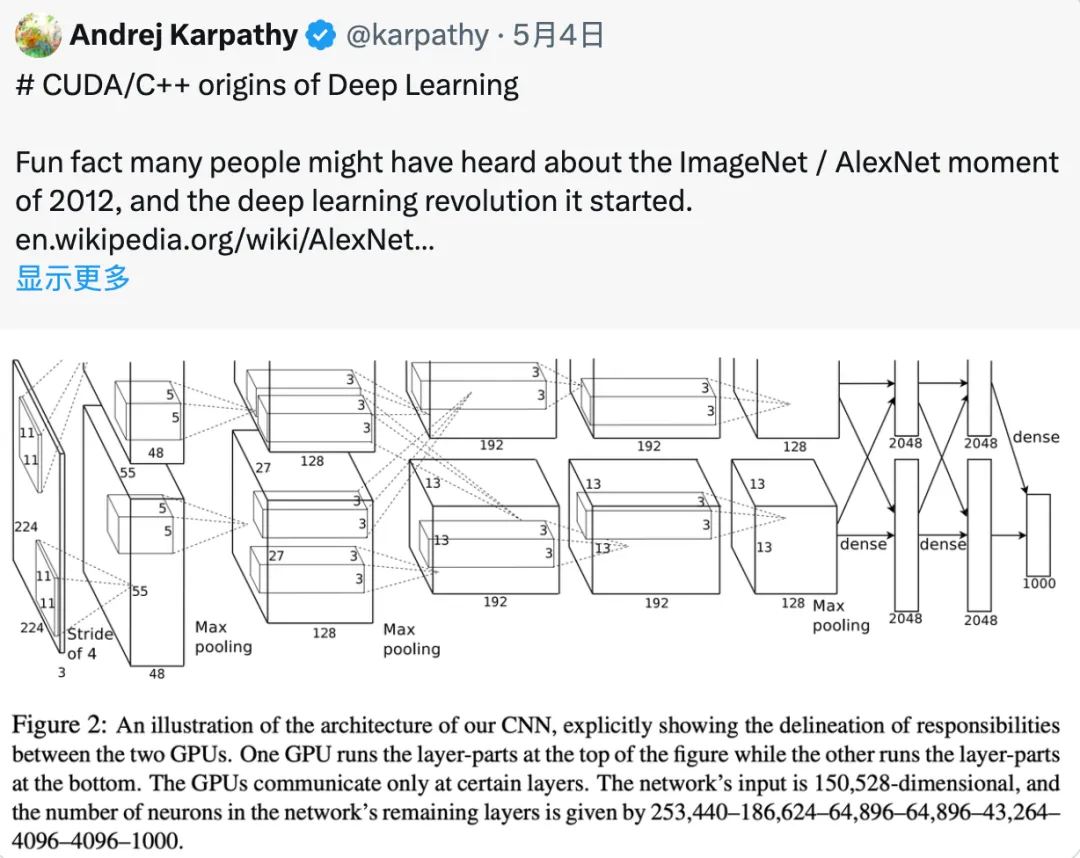
没想到,自 2012 年 AlexNet 开启的深度学习革命已经过去了 12 年。

机器如何能像人类和动物一样高效地学习?机器如何学习世界运作方式并获得常识?机器如何学习推理和规划……

随着 Llama 3 发布,未来大模型的参数量已飙升至惊人的 4000 亿。尽管每周几乎都有一个声称性能超强的大模型出来炸场,但 AI 应用还在等待属于它们的「ChatGPT 时刻」。其中,AI 智能体无疑是最被看好的赛道。

对于烟雾等动态三维物理现象的高效高质量采集重建是相关科学研究中的重要问题,在空气动力学设计验证,气象三维观测等领域有着广泛的应用前景。通过采集重建随时间变化的三维密场度序列,可以帮助科学家更好地理解与验证真实世界中的各类复杂物理现象。

生成式 AI 可以对话、写诗、画图、做视频、作曲、写代码......

AI做数学题,真正的思考居然是暗中“心算”的?
身为文案内容创作的打工人,每天都要不停的码字,写文案,写脚本,写日报,写周报等等等。。。脑细胞真的剩的不多了!

2016 年,由人工智能撰写《电脑写小说的那一天》小说成功通过了日本“星新一文学奖”的初选;Sony 开发的 DeepBach AI 在深度学习巴赫后,创作出的仿巴赫音乐,在 1600 位听众里,骗过了超过一半的人,让他们以为这就是巴赫本人的创作。

资本市场即将决出下一阶段人工智能受益者。一年多来,人工智能一直是投资者关注的焦点,为这一新周期构建硬件和软件的公司享受着出色的股票回报。接下来,一些非科技企业将从人工智能中受益,他们通过AI工具提高效率和生产力。

2024年5月3日下午,北大建校126周年校庆之际,在北大博雅酒店的聚光灯下,一场汇聚顶尖AI智慧的盛宴——北京大学人工智能产业峰会暨校友「人工智能+」论坛在北大校庆期间隆重举行。

没想到,在大模型时代,知名「AI 教母」李飞飞也要「创业」了,并完成了种子轮融资。

今年 1 月份,2024 年度 IEEE 冯诺伊曼奖项结果正式公布,斯坦福大学语言学和计算机科学教授、AI 学者克里斯托弗・曼宁(Christopher Manning)获奖。

近年来,大型语言模型(LLM)在数学应用题和数学定理证明等任务中取得了长足的进步。数学推理需要严格的、形式化的多步推理过程,因此是 LLMs 推理能力进步的关键里程碑, 但仍然面临着重要的挑战。

使用测序 (scATAC-seq) 技术对转座酶可及的染色质进行单细胞测定,可在单细胞分辨率下深入了解基因调控和表观遗传异质性,但由于数据的高维性和极度稀疏性,scATAC-seq 的细胞注释仍然具有挑战性。现有的细胞注释方法大多集中在细胞峰矩阵上,而没有充分利用底层的基因组序列。
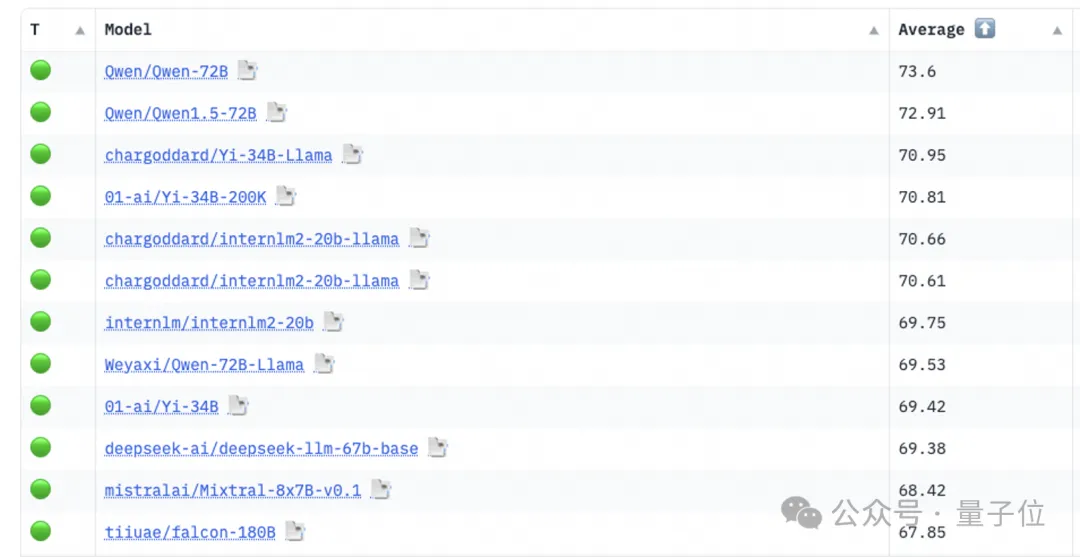
在过去一年中,通义千问系列模型持续开源。
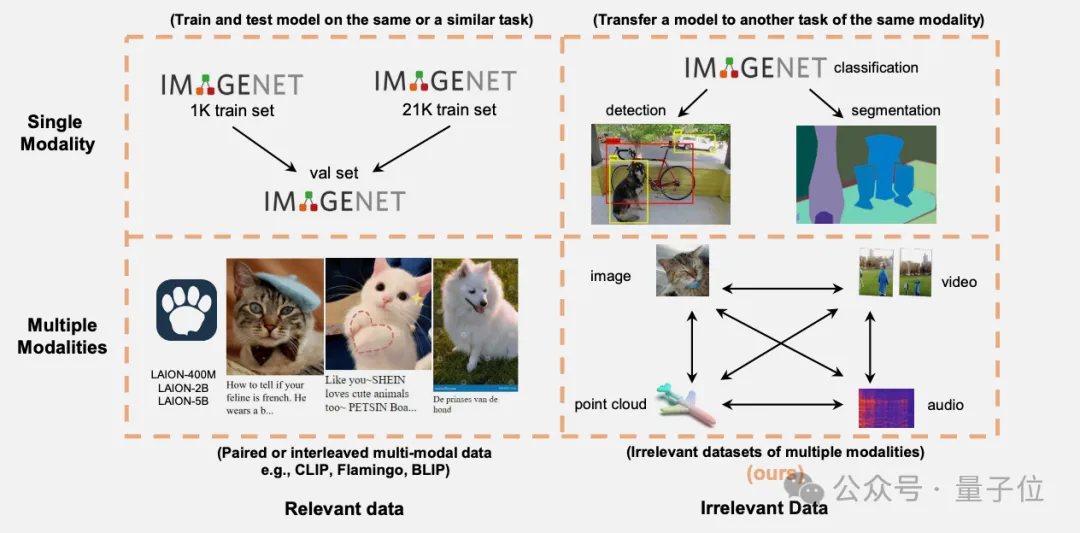
万万没想到,与任务无直接关联的多模态数据也能提升Transformer模型性能。

我有一个朋友,中年被裁、股市爆仓、子女厌学……但是他毫不气馁,不怨天地,每天除了钓鱼、打游戏,剩下的时间都用来积极思考新的创业良机。

“预测下一个token”被认为是大模型的基本范式,一次预测多个tokens又会怎样?

全球AIGC应用浪潮下,怎样将大模型产品以一种更贴近消费者的形式融入生产力工具?

尽管蛋白质结构预测取得了重大进展。但对于 80% 以上的蛋白质,迄今为止尚未发现小分子配体。识别大多数蛋白质的小分子配体仍具有挑战性。