多轮对话推理速度提升46%,开源方案打破LLM多轮对话的长度限制
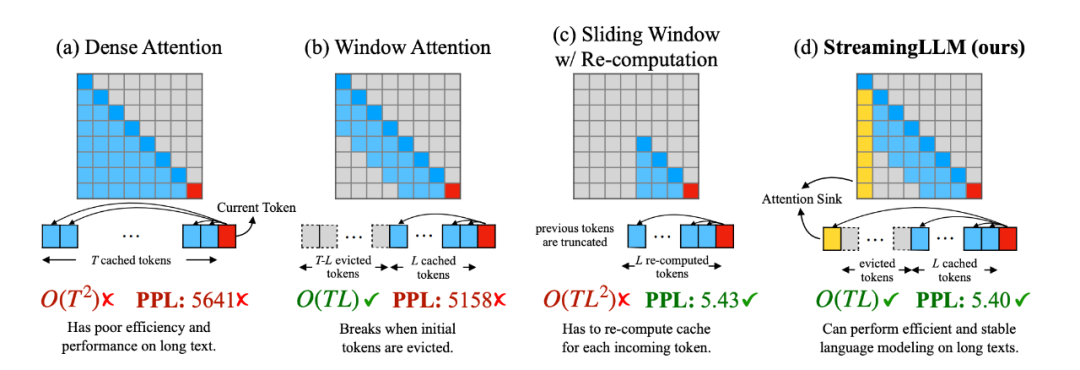
多轮对话推理速度提升46%,开源方案打破LLM多轮对话的长度限制在大型语言模型(LLM)的世界中,处理多轮对话一直是一个挑战。前不久麻省理工 Guangxuan Xiao 等人推出的 StreamingLLM,能够在不牺牲推理速度和生成效果的前提下,可实现多轮对话总共 400 万个 token 的流式输入,22.2 倍的推理速度提升。
来自主题: AI技术研报
7638 点击 2024-01-08 14:02
 搜索
搜索
在大型语言模型(LLM)的世界中,处理多轮对话一直是一个挑战。前不久麻省理工 Guangxuan Xiao 等人推出的 StreamingLLM,能够在不牺牲推理速度和生成效果的前提下,可实现多轮对话总共 400 万个 token 的流式输入,22.2 倍的推理速度提升。
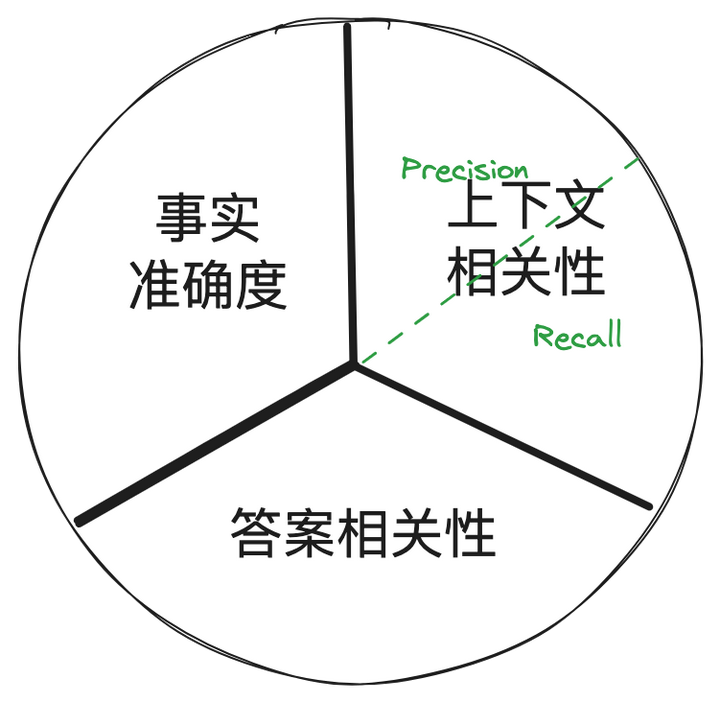
做所有的工作之前,想好如何评估结果、制定好北极星指标至关重要!!! Ragas把 RAG 系统的评估指标拆分为三个维度如下,这可不是 Benz 的标...
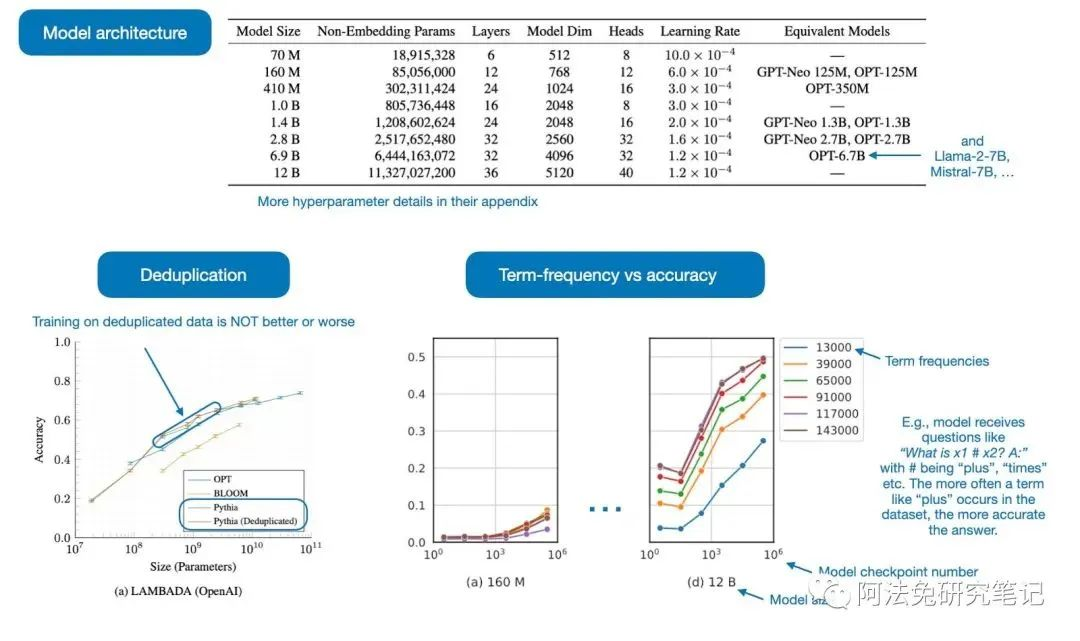
2023 年,是机器学习和人工智能发展最为迅速的一年,这里分享 10 篇最值得关注的论文。

谷歌新设计的一种图像生成模型已经能做到这一点了!通过引入指令微调技术,多模态大模型可以根据文本指令描述的目标和多张参考图像准确生成新图像,效果堪比 PS 大神抓着你的手助你 P 图。

琳琅满目的乐高积木,通过一块又一块的叠加,可以创造出各种栩栩如生的人物、景观等,不同的乐高作品相互组合,又能为爱好者带来新的创意。

一句话定位视频片段

这篇论文介绍了一项新的任务 —— 指向性遥感图像分割(RRSIS),以及一种新的方法 —— 旋转多尺度交互网络(RMSIN)。

多模态大模型集成了检测分割模块后,抠图变得更简单了!
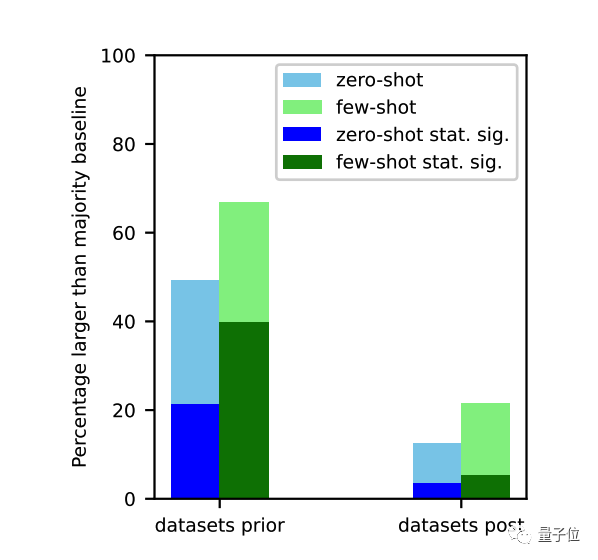
对于ChatGPT变笨原因,学术界又有了一种新解释。加州大学圣克鲁兹分校一项研究指出:在训练数据截止之前的任务上,大模型表现明显更好。
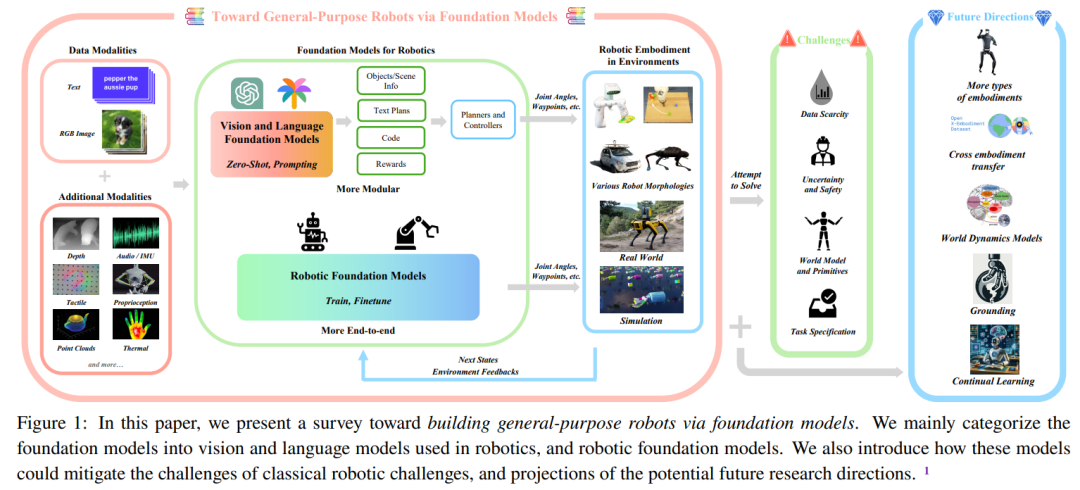
机器人是一种拥有无尽可能性的技术,尤其是当搭配了智能技术时。近段时间创造了许多变革性应用的大模型有望成为机器人的智慧大脑,帮助机器人感知和理解这个世界并制定决策和进行规划。

不会,prompt engineering 仍然是一个基本技能。GPTs 就是一个简化版的 Agent,这段提示词就是你能用来控制这个 Agent 最重要指令。

如果 AI 是一辆豪华跑车,那么 LoRA 微调技术就是让它加速的涡轮增压器。LoRA 强大到什么地步?它可以让模型的处理速度提升 300%。还记得 LCM-LoRA 的惊艳表现吗?其他模型的十步,它只需要一步就能达到相媲美的效果。
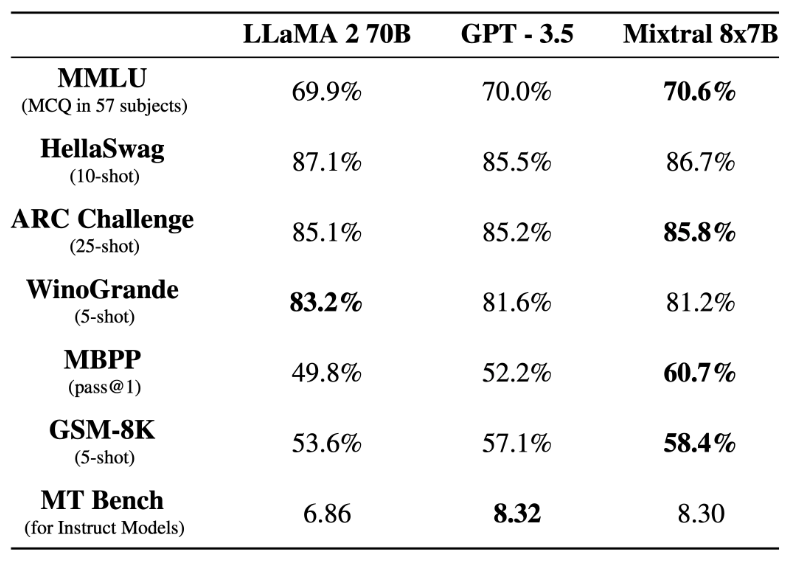
前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。

一个来自MIT博士生的惊人发现:只需对Transformer的特定层进行一种非常简单的修剪,即可在缩小模型规模的同时显著提高模型性能。
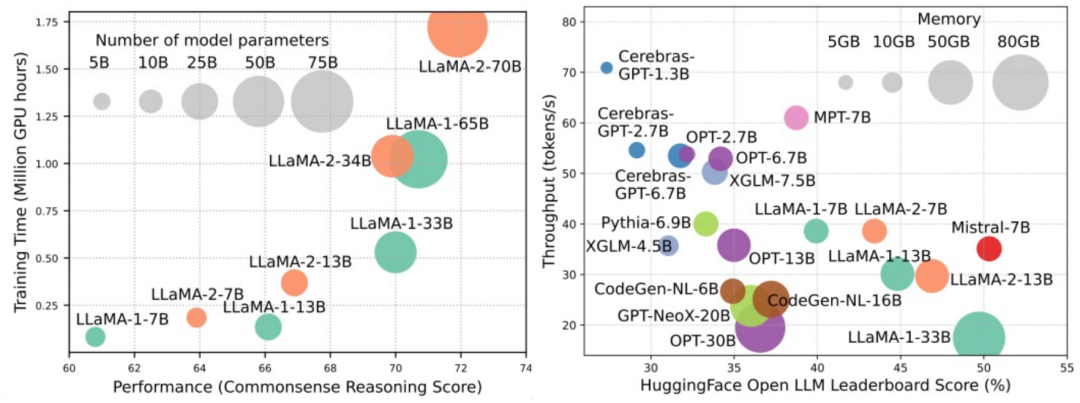
大规模语言模型(LLMs)在很多关键任务中展现出显著的能力,比如自然语言理解、语言生成和复杂推理,并对社会产生深远的影响。然而,这些卓越的能力伴随着对庞大训练资源的需求(如下图左)和较长推理时延(如下图右)。因此,研究者们需要开发出有效的技术手段去解决其效率问题。

首个视觉、语言、音频和动作多模态模型Unified-IO 2来了!它能够完成多种多模态的任务,在超过30个基准测试中展现出了卓越性能。

混合专家模型(MoE)成为最近关注的热点。

ChatGPT 凭一己之力掀起了 AI 领域的热潮,火爆全球,似乎开启了第四次工业革命。
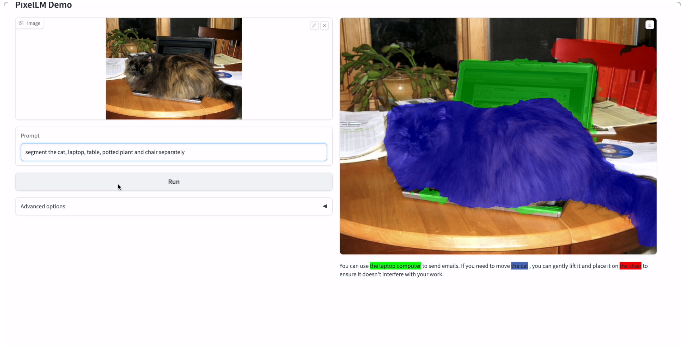
目前大多数模型的能力还是局限于生成对整体图像或特定区域的文本描述,在像素级理解方面的能力(例如物体分割)相对有限。

微软默默地推出了安卓版本的Copilot,可以免费使用GPT-4,甚至还能绕过OpenAI的次数限制。
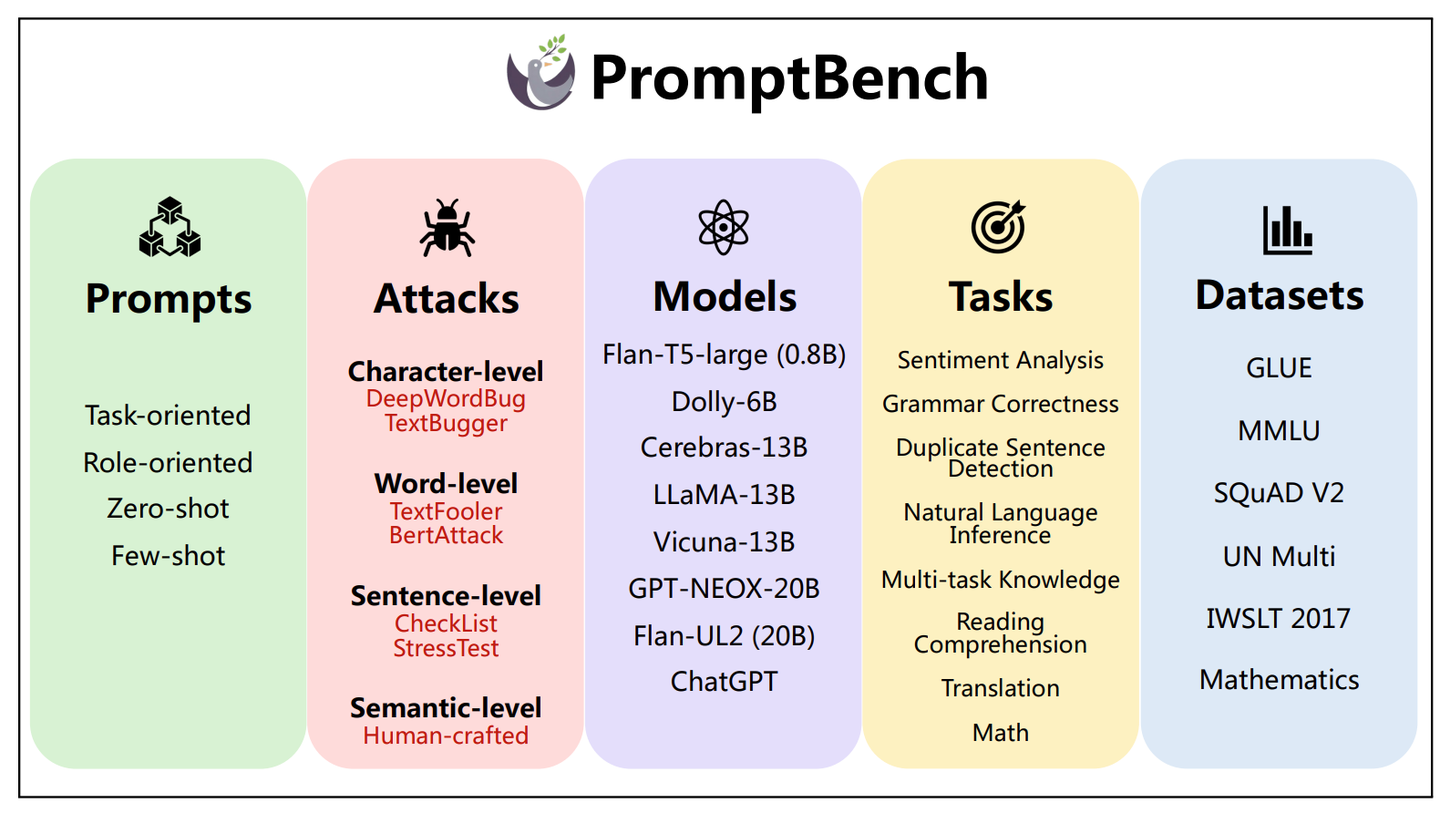
作为连接人类与大模型的桥梁,大模型对 「Prompt (提示词)」 究竟有多敏感?同样的prompt,可能写错个单词、写法不一样,都会出现不一样的结果。
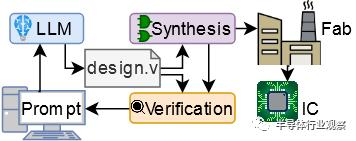
使用LLM来制造芯片, 过去一年多以来,ChatGPT引发的AI浪潮席卷全球。

游戏行业真在加速拥抱大语言模型等AI技术,不论是大厂还是独立游戏制作人,都开始依靠LLM的技术创立全新的AI NPC体验。

NeurIPS收录的一项新研究,让大模型也学会“读心术”了!通过学习脑电波数据,模型成功地把受试者的脑电图信号翻译成了文本。

美图影像研究院(MT Lab)与中国科学院大学突破性地提出了基于文生图模型的视频生成新方法 EI2,用于提高视频编辑过程中的语义和内容两方面的一致性。
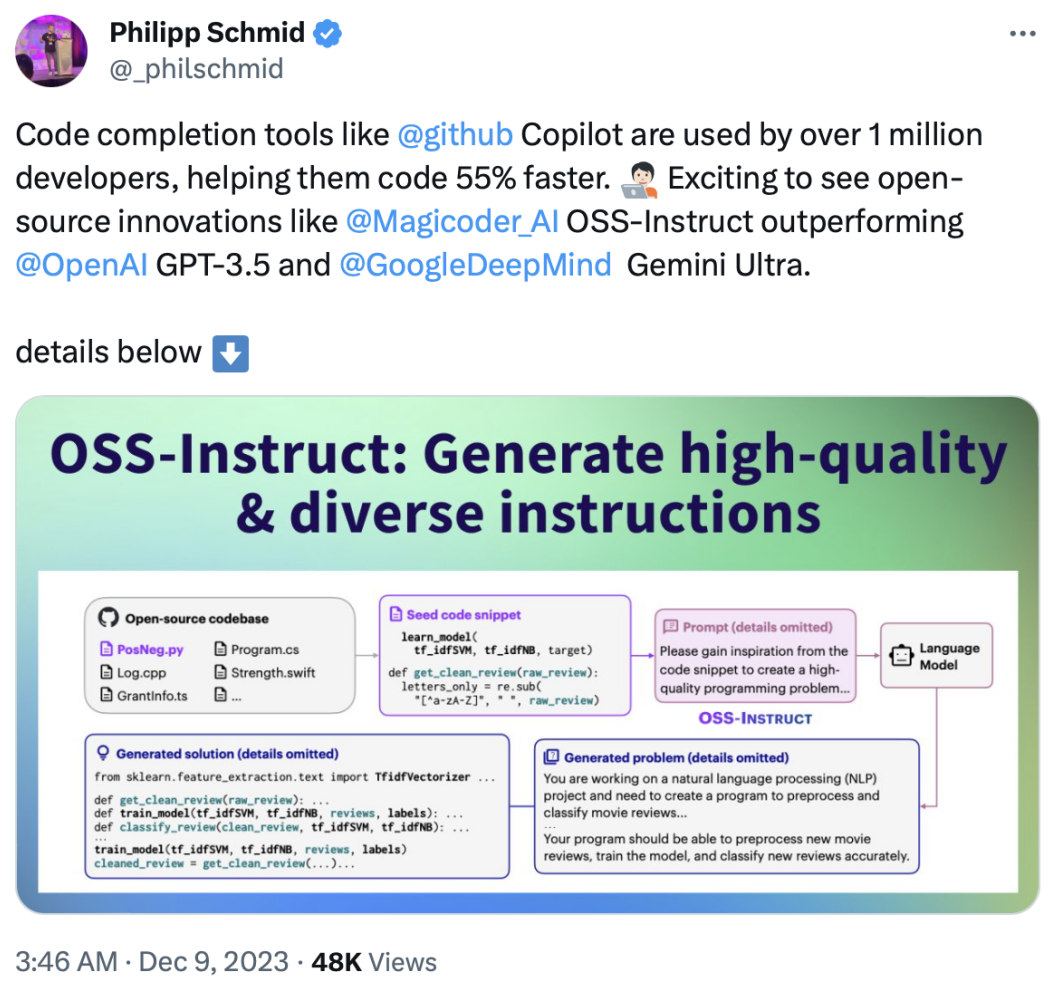
软件开发人员对代码生成 AI 已经不陌生,它们已经成为提高生产力的利器。本文中,伊利诺伊大学香槟分校(UIUC)张令明老师团队带来了代码生成 AI 领域的又一力作 ——Magicoder,在短短一周之内狂揽 1200 多颗 GitHub Star,登上 GitHub Trending 日榜,并获推特大佬 AK(@_akhaliq)发推力荐。

最近,有人在社交媒体上发布了一张有关 GPT4.5 更新的截图。图中内容显示,和 GPT 系列之前推出的模型相比,GPT4.5 最大的惊喜可能就是处理 3D 和视频的能力。至于 3D 能力到底是指看得懂 3D 图像,还是能输入 3D 模型,目前只能靠猜。
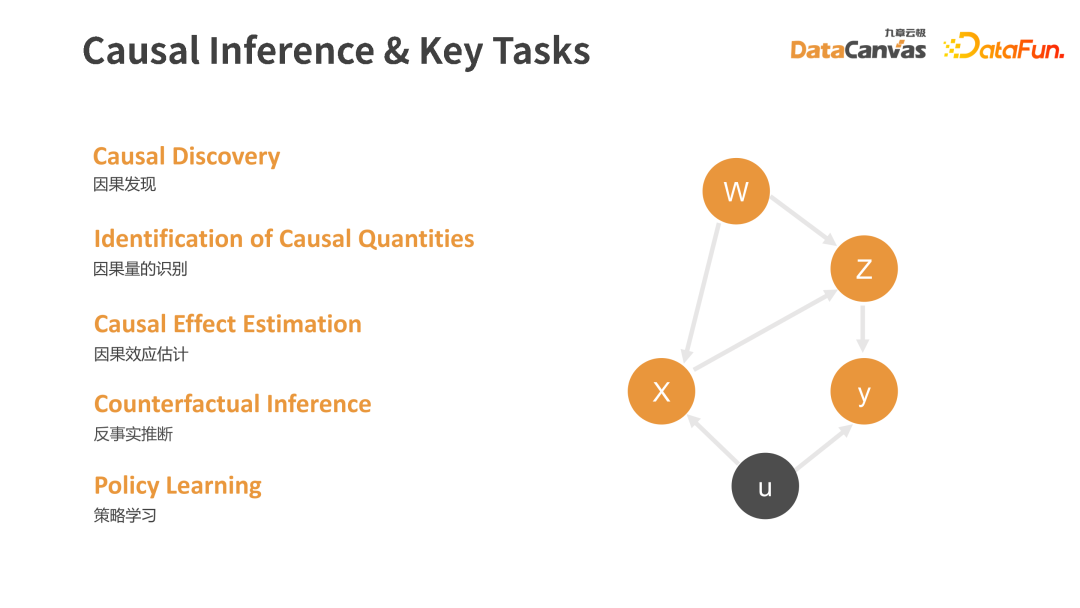
在数字化建设不断推进的今天,随着技术的不断发展,从统计学、机器学习、深度学习,再到因果学习以及最新的热门大模型方向,九章云极 DataCanvas 始终紧贴最前沿的、最能助力企业和落地实践的方向,不断进行着面向决策和面向智能的探索。本文将分享大模型时代下的因果推断。

小模型的风潮,最近愈来愈盛,Mistral和微软分别有所动作。而网友实测发现,Mistral-medium的代码能力竟然完胜了GPT-4,而所花成本还不到三分之一。
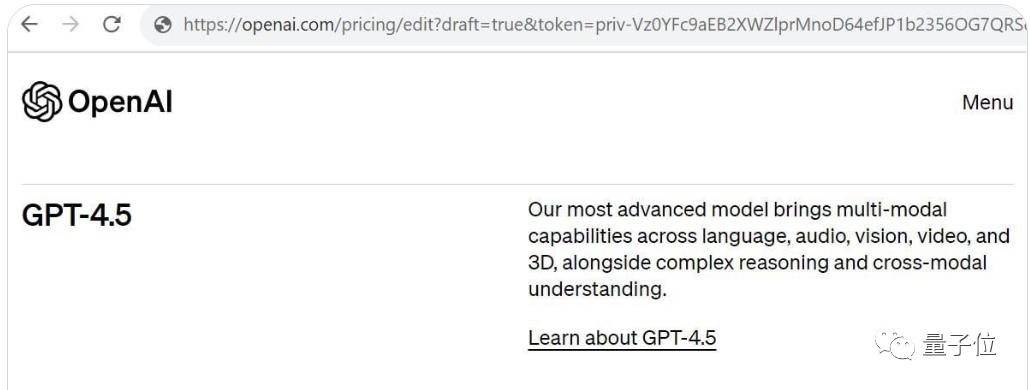
GPT 4.5疑似大泄漏: 一个是新模型将具备全新多模态能力,文本语音图片以及视频和3D信息全都能一并处理,并且还可以跨模态理解。