
OpenAI员工自曝:根本不想去微软,联名辞职逼宫只是最后手段
OpenAI员工自曝:根本不想去微软,联名辞职逼宫只是最后手段OpenAI内斗吃瓜要开第二季了。这一边,被“扫地出门”的前董事会成员海伦·托纳(Helen Toner)放出最新内幕:
来自主题: AI资讯
9614 点击 2023-12-08 15:04
 搜索
搜索
OpenAI内斗吃瓜要开第二季了。这一边,被“扫地出门”的前董事会成员海伦·托纳(Helen Toner)放出最新内幕:
大惊喜朋友们!马斯克突然宣布,Grok大模型向付费用户大批量开放了。
没想到,在ChatGPT爆火后的一年里,竟然出现了一个隐藏“Boss”——量子位获悉,百度、360等互联网大厂均已开始基于昇腾部署AI模型;而知乎、新浪、美图这样全速推进AI业务的公司,背后同样出现了华为云昇腾AI云服务的身影。

北大、北邮、UCLA和BIGAI的研究团队联合发布,智能体新突破——Jarvis-1.智能体研究又取得了新成绩!

过度训练让中度模型出现了结构泛化能力。
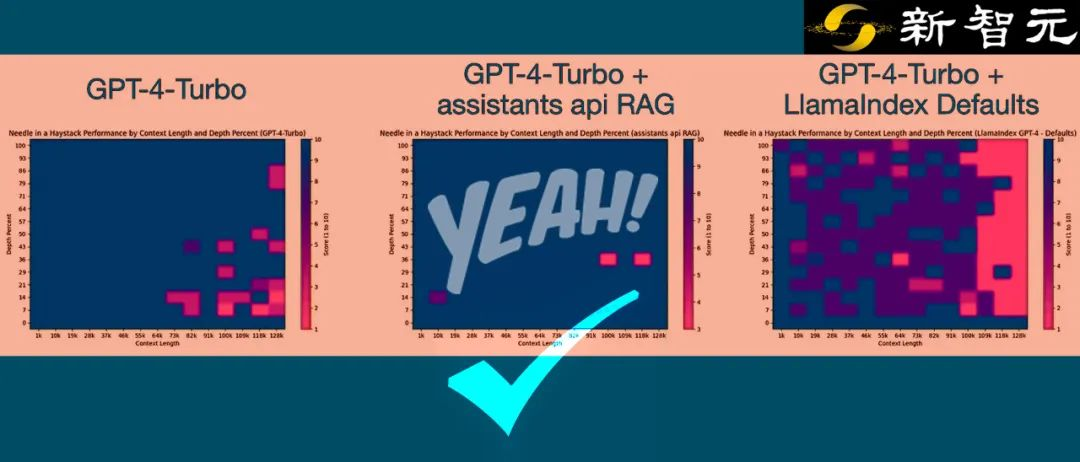
RAG或许就是大模型能力飙升下一个未来。RAG+GPT-4,4%的成本,便可拥有卓越的性能。

继谷歌DeepMind AI工具成功预测出220万种晶体结构后,微软团队最新扩散模型MatterGen,能设计生成新颖、稳定的材料,刷新SOTA。

昨天深夜,Google 突然发布重磅 AI 杀手锏——Gemini。多模态 Gemini 可以理解、操作和结合不同类型的信息,包括文本、代码、音频、图像和视频。

时代变了?迄今为止规模最大,能力最强的谷歌大模型来了。当地时间 12 月 6 日,谷歌 CEO 桑达尔・皮查伊官宣 Gemini 1.0 版正式上线。
很担心AI的精神状态,最近,一则视频的出现,让很多观众打破了对人工智能的滤镜。

哥伦比亚大学计算机科学教授Jeff Clune则在Agent身上看到巨大商机:“可能价值数万亿美元。”而进一步,英伟达高级研究员Jim Fan预言,Agent将“推动整个文明的进化”。
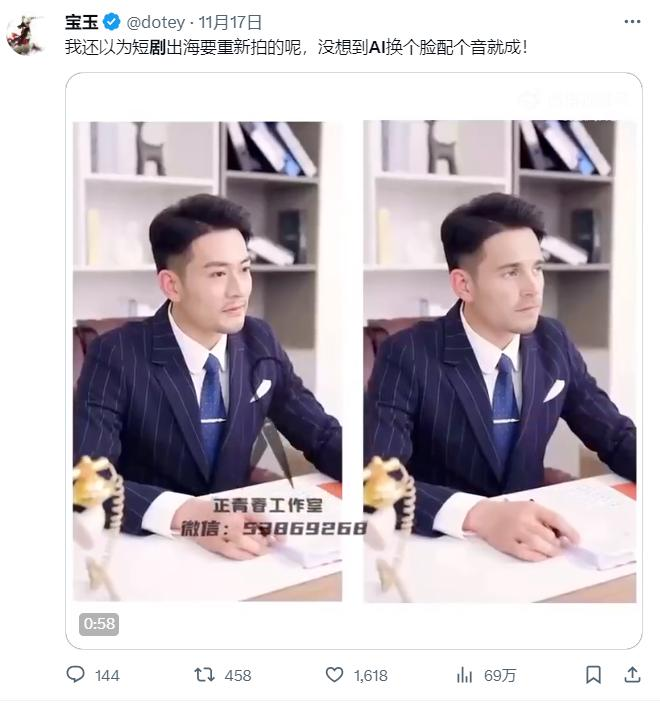
一条新的“出路”。上个月,很多短剧群以及推特上突然开始流传一个使用了 AI 换脸技术的短剧片段。 利用 AI 技术,短剧中中国面孔的演员摇身变成欧美男主,各种小表情、神态还挺到位。

22岁大学生Edward Tian开发了一个名为GPTZero的AI应用,用于检测文本是否由AI生成。该应用引发了全球学生的关注和争议,以及教师们对作弊工具的担忧。然而,Tian也因此创办了公司GPTZero并获得了350万美元的风投基金。文章探讨了学生和教师对AI在学术中应用的不同态度,并介绍了GPTZero的工作原理以及对抗AI检测的努力。
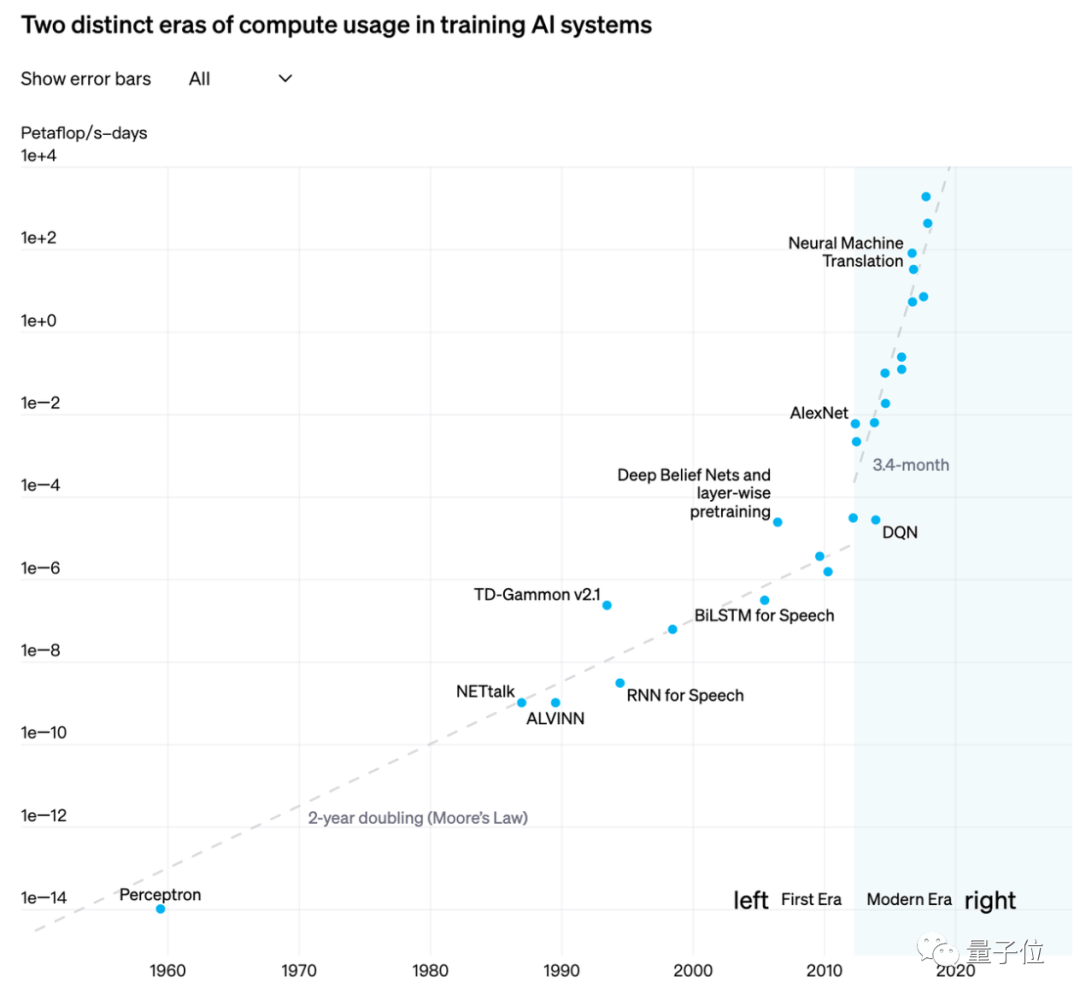
大模型究竟从下一个词预测任务中学到了什么呢?还记得 Jason Wei 吗?这位思维链的提出者还曾共同领导了指令调优的早期工作,并和 Yi Tay、Jeff Dean 等人合著了关于大模型涌现能力的论文。
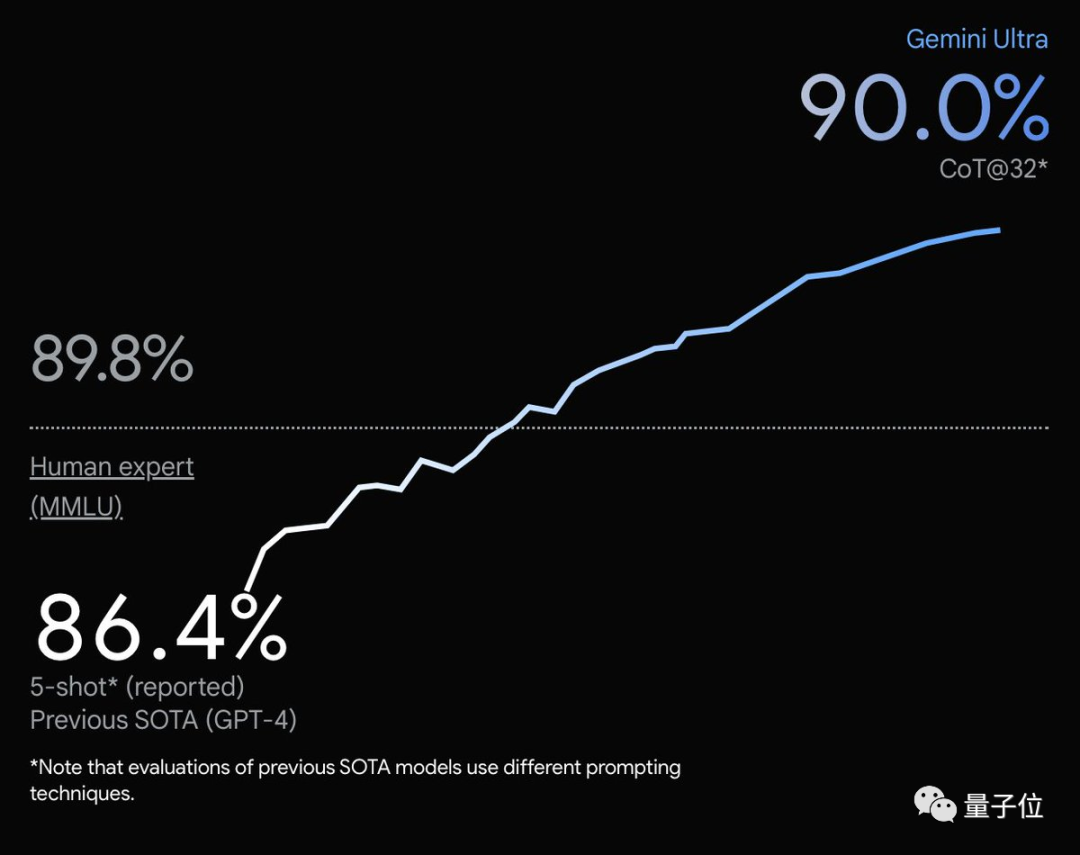
谷歌憋了许久的大招,双子座Gemini大模型终于发布!其中一图一视频最引人注目:一图,MMLU多任务语言理解数据集测试,Gemini Ultra不光超越GPT-4,甚至超越了人类专家。

作为一个入行多年的自媒体编辑,写稿速度是越来越快了,找选题却越来越头疼了。每天坐在电脑前第一件事就是绞尽脑汁想选题,尤其是处在新闻大爆炸的时代,在满屏的资讯里认真筛选几个重要的选题就过去一上午了。

后期狂喜了家人们~现在,只需一张图片就能替换视频主角,效果还是如此的丝滑!且看这个叫做“VideoSwap”的新视频编辑模型——
苹果M系列芯片专属的机器学习框架,开源即爆火!现在,用上这个框架,你就能直接在苹果GPU上跑70亿参数大模型、训练Transformer模型或是搞LoRA微调。

马斯克和拉里·佩奇的一场争吵引发了AI大潮,OpenAI和DeepMind等公司在AI领域展开竞争,引发全球争议和关注。马斯克和佩奇之间的争吵预示了AI发展的重要性和影响。

传说中的Gemini,终于在今天深夜上线了!「原生多模态」架构,是谷歌的史诗级创举,Gemini也如愿在多个领域超越了GPT-4。这场仗,谷歌必不能输。

AI社交会颠覆传统社交吗?AI社交(AI伴聊)成了社交创新的热门赛道。

量身定制一个新世界。如果不创业,池光耀现在应该上大三,正准备上半学期的期中考试。2023年8月末的一个陌生来电,改变了他的人生轨迹。

传统机器视觉玩家正补全算法和智能化能力,而AI质检新势力们则继续向标准化软硬件方向拓展。工业质检的市场格局正在发生变化。
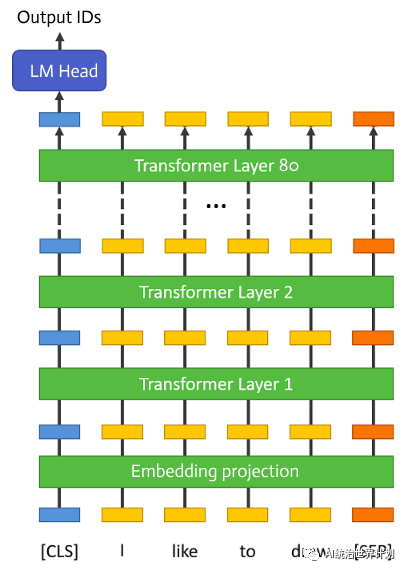
大语言模型需要消耗巨量的GPU内存。有可能一个单卡GPU跑推理吗?可以的话,最低多少显存?70B大语言模型仅参数量就有130GB,仅仅把模型加载到GPU显卡里边就需要2台顶配100GB内存的A100。

百模大战后,一众精疲力竭的创业者们逐渐反应过来:中国真正的机会在应用层,AI原生应用才是下一轮最肥沃的土壤。

包括AIGC在内的技术成为下阶段游戏行业发展的核心动力之一已经是无需多谈的共识。

脱胎自 RISC-V,能把推理训练能效提高 1 万倍。OpenAI 的权力之争才刚刚落幕,一场关键交易悄悄浮出了水面。

12月5-6日,主题为“未来AI设计”的美图创造力大会在厦门举行。美图公司发布自研AI视觉大模型MiracleVision(奇想智能)4.0版本,主打AI设计与AI视频。
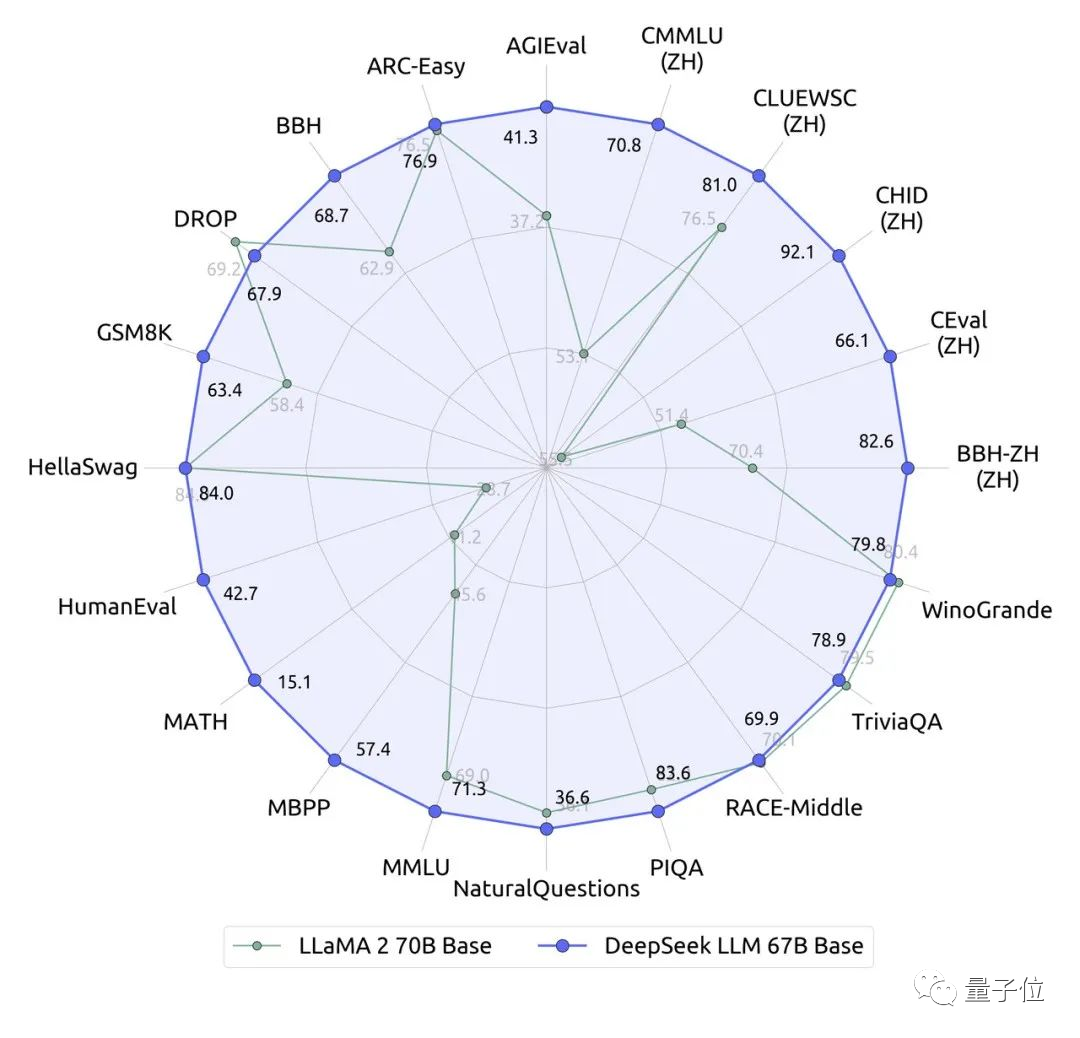
国产大模型刚刚出了一位全新选手:参数670亿的DeepSeek。它在近20个中英文的公开评测榜单上直接超越了同量级、700亿的Llama 2。

大模型的效果好不好,有时候对齐调优很关键。但近来很多研究开始探索无微调的方法,艾伦人工智能研究所和华盛顿大学的研究者用「免调优」对齐新方法超越了使用监督调优(SFT)和人类反馈强化学习(RLHF)的 LLM 性能。