Wan2.5+Midjourney V7,阿里夸克这个新AI鲨疯了!价格还砍一大刀
Wan2.5+Midjourney V7,阿里夸克这个新AI鲨疯了!价格还砍一大刀夸克“造点”AI发布了!直接上大招,Wan2.5+Midjourney V7双强模型联合!夸克“造点”还在今天第一时间,率先接入了阿里自家刚刚发布的视频生成模型通义万相Wan2.5,甚至直接开放了7天免费体验。
来自主题: AI资讯
10808 点击 2025-09-25 11:37
 搜索
搜索
夸克“造点”AI发布了!直接上大招,Wan2.5+Midjourney V7双强模型联合!夸克“造点”还在今天第一时间,率先接入了阿里自家刚刚发布的视频生成模型通义万相Wan2.5,甚至直接开放了7天免费体验。
刚刚,Meta FAIR推出了代码世界模型!CWM(Code World Model),一个参数量为32B、上下文大小达131k token的密集语言模型,专为代码生成和推理打造的研究模型。这是全球首个将世界模型系统性引入代码生成的语言模型。

奇多多AI学伴机是由无界方舟发布的国内首款基于「端到端实时多模态互动模型」的AI互动机器人,于本月2025外滩大会首次亮相。京东预售仅上线一周,销量便突破了10000台,在看似红海的儿童早教市场掀起波澜。在功能体验方面,它带来了三大突破:能“看”世界的眼睛、堪比真人的低延迟反馈速度、能“成长”的个性化陪伴感。
答案或许渐渐清晰。李飞飞团队与斯坦福 AI 实验室正式官宣:首届 BEHAVIOR 挑战赛将登陆 NeurIPS 2025。这是一个为具身智能量身定制的 “超级 benchmark”,涵盖真实家庭场景下最关键的 1000 个日常任务(烹饪、清洁、整理……),并首次以 50 个完整长时段任务作为核心赛题,考验机器人能否在逼真的虚拟环境中完成真正贴近人类生活的操作。

刚刚,快手可灵AI基座模型再升级,推出可灵2.5 Turbo视频生成模型。AI视频玩家抹一把老泪,终于有AI视频模型让运动员们拥有不鬼畜自由了!a16z合伙人在𝕏上分享了一个可灵2.5 Turbo生成的视频:

2025 年 9 月,这个未来主义的问题进入了全球最高决策层的视野。美联储率先表态将研究 AI 与代币化支付,紧接着,SEC 前主席 Paul S. Atkins 在巴黎正式将其命名为「代理金融」(Agentic Finance)时代。

9月24日,在杭州召开的云栖大会上,阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭发表主旨演讲,他认为实现通用人工智能AGI已是确定性事件,但这只是起点,终极目标是发展出能自我迭代、全面超越人类的超级人工智能ASI。
新一代旗舰模型Qwen3-Max带着满分成绩,正式地来了——国产大模型首次在AIME25和HMMT这两个数学评测榜单拿下100分!和前不久Qwen3-Max-Preview一致,参数量依旧是超万亿的规模。
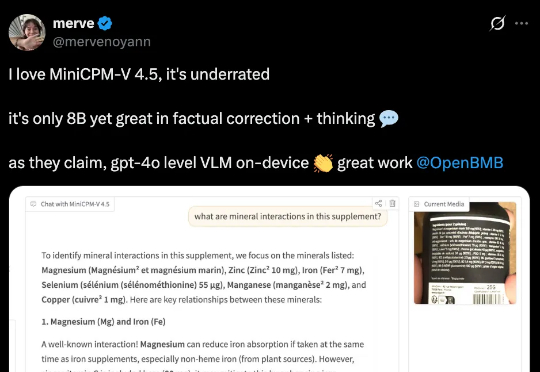
行业首个具备“高刷”视频理解能力的多模态模型MiniCPM-V 4.5的技术报告正式发布!报告提出统一的3D-Resampler架构实现高密度视频压缩、面向文档的统一OCR和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。

时间的流逝,正在成为DeepSeek最沉重的成本