
让大模型“边看边改”,视觉分割准确率直接上涨9% | ICML 2026
让大模型“边看边改”,视觉分割准确率直接上涨9% | ICML 2026智能体时代,如何让视觉分割更准确?
来自主题: AI技术研报
9193 点击 2026-05-27 16:31
 搜索
搜索
智能体时代,如何让视觉分割更准确?

就在今天,教皇的首份AI通谕震撼发布,42300字宣言《壮丽人性》引人深思!Anthropic联创也绝望向教皇求助:大模型已经演化出恐惧与悲伤,人类实验室已经无法自我修正。

AI范式从Chat转向Agent时,AI的能力边界正在被重新定义。
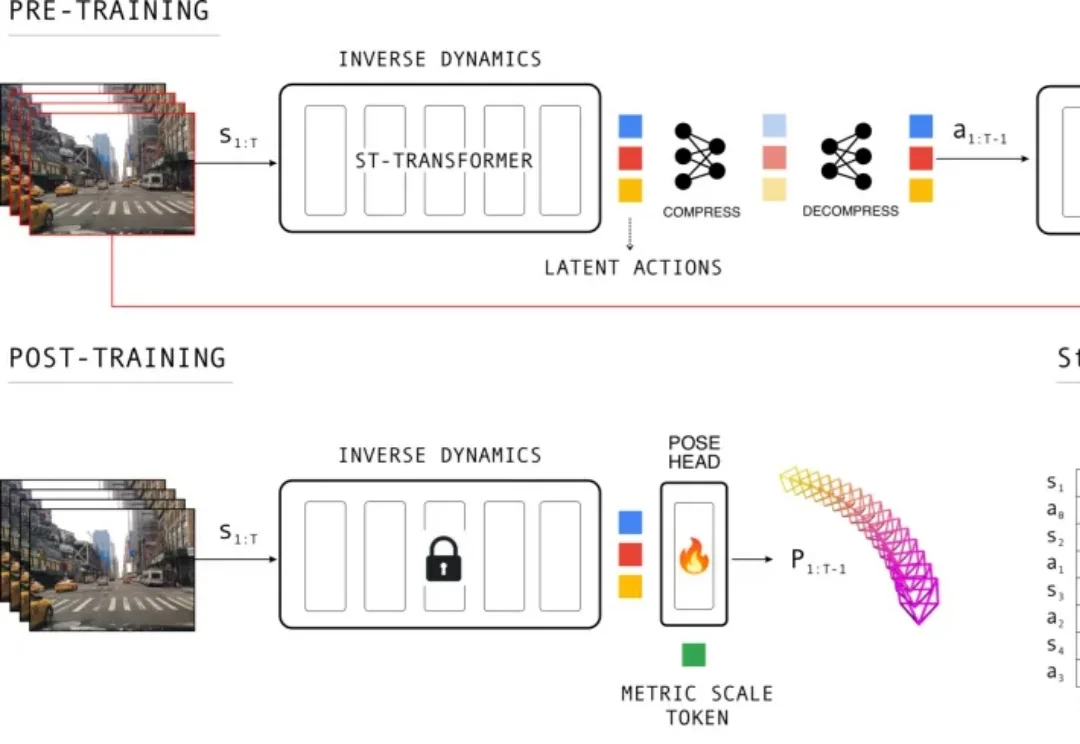
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。

每周25万亿tokens的真实流量、估值一年翻倍——OpenRouter拿下1.13亿美元B轮融资。

红星新闻报道,5月26日,记者联系了多家AI平台,其中豆包客服表示,豆包在高考期间可正常使用,但拍题答疑等类似功能会被禁用,具体情况要以当时页面显示为准,目前还未接到通知。

据 FT 报道,字节跳动正在向旗下 Seed 部门员工开放新一轮豆包股认购权,每股 13 美元。Seed 目前约有 2000 名员工,包括核心研究员、基础设施工程师、数据标注团队和翻译人员。
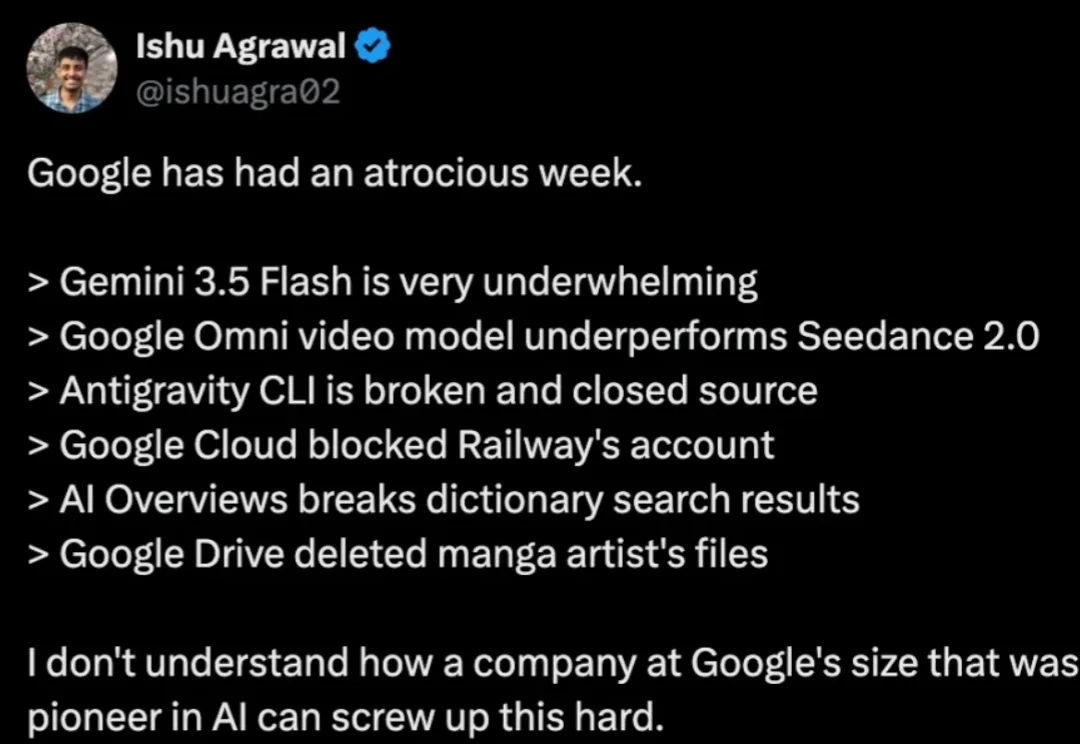
最近,谷歌的日子不太好过。
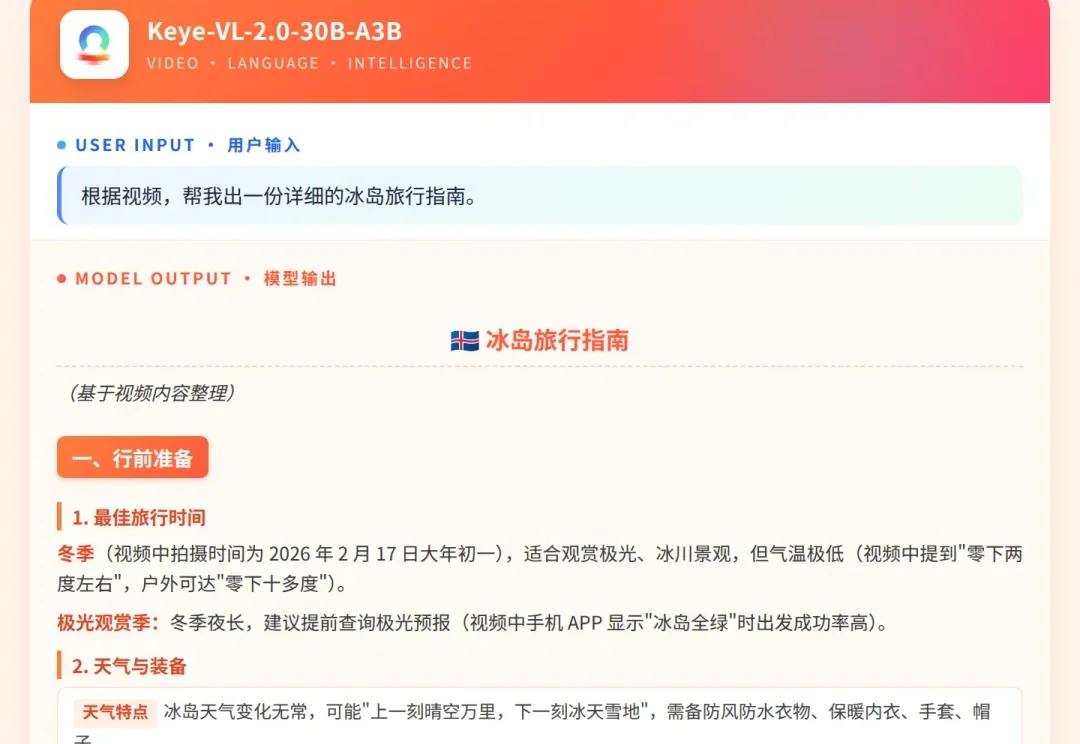
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。
DeepSeek研究员陈德里,在个人博客更新一篇研究综述论文。用的是他自己的技能DeliAutoResearch,DeepSeek-V4-Pro研究和写作,GPT-Image2画图。论文共迭代6次(V1:4 次,V2:1 次,V3:1 次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,写了2234行LaTeX代码。