北京大学彭宇新教授团队开源最新多轮交互式商品检索模型、数据集及评测基准
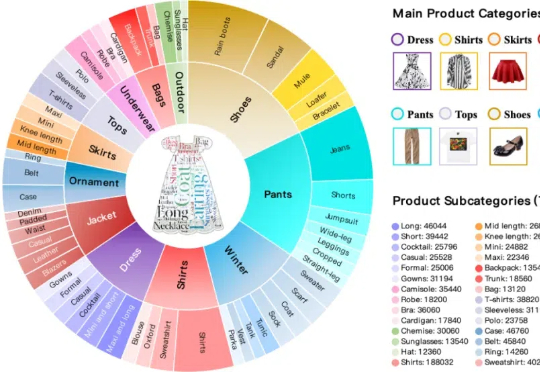
北京大学彭宇新教授团队开源最新多轮交互式商品检索模型、数据集及评测基准本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。
来自主题: AI技术研报
9090 点击 2025-03-05 08:46