
2026年中国AI应用全景图谱报告发布
2026年中国AI应用全景图谱报告发布有一个问题,值得在2026年认真问一次—— 你上一次用AI应用,是让它回答了一个问题,还是让它完成了一件事?
来自主题: AI资讯
9514 点击 2026-05-21 09:47
 搜索
搜索
有一个问题,值得在2026年认真问一次—— 你上一次用AI应用,是让它回答了一个问题,还是让它完成了一件事?

2026年,AI产业正在进入新一轮高强度算力周期。
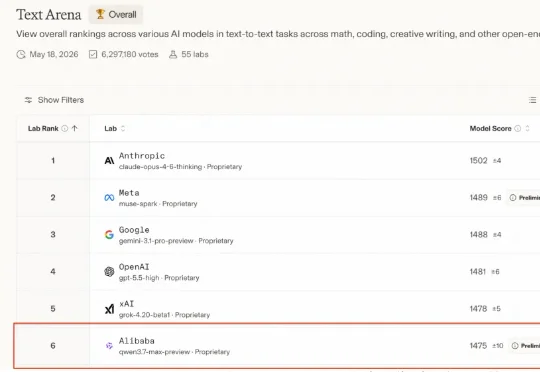
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型

今日,在2026阿里云峰会上,阿里云正式亮出Agentic时代 “超级算力地基”。阿里云正式发布磐久AL128超节点服务器,搭载平头哥首次亮相的自研训推一体AI芯片真武M890,搭配自研互联芯片ICN Switch 1.0,单机柜128张AI芯片紧密耦合,组成一台“计算机”。
近日,美国耶鲁大学博士毕业生李昊特和合作者开发了一套叫 MOSAIC 的 AI 系统,把化学合成知识分成了 2,498 个专业领域,每个领域训练一个专家模型。

5 月 20 日,具身智能初创公司贝塔无限(Beta Infinity)宣布完成种子+ 轮融资。本轮由世纪华通参与的盛趣泰和基金与和利资本联合领投,毅达资本、南山战新投等机构跟投。这是该公司成立后完成的第二轮融资,累计融资金额达数亿元,资金将主要用于核心技术研发及产品试制等。

教宗利奥十四世将于 5 月 26 日发布任期首份通谕,主题直指 AI,Anthropic 联合创始人、Claude 缔造者 Chris Olah 受邀同台。梵蒂冈同步成立 AI 委员会。一个两千年的古老机构,正试图用道德权威填补 AI 治理的真空——它覆盖的人口,比任何一部 AI 法案的管辖范围都大。
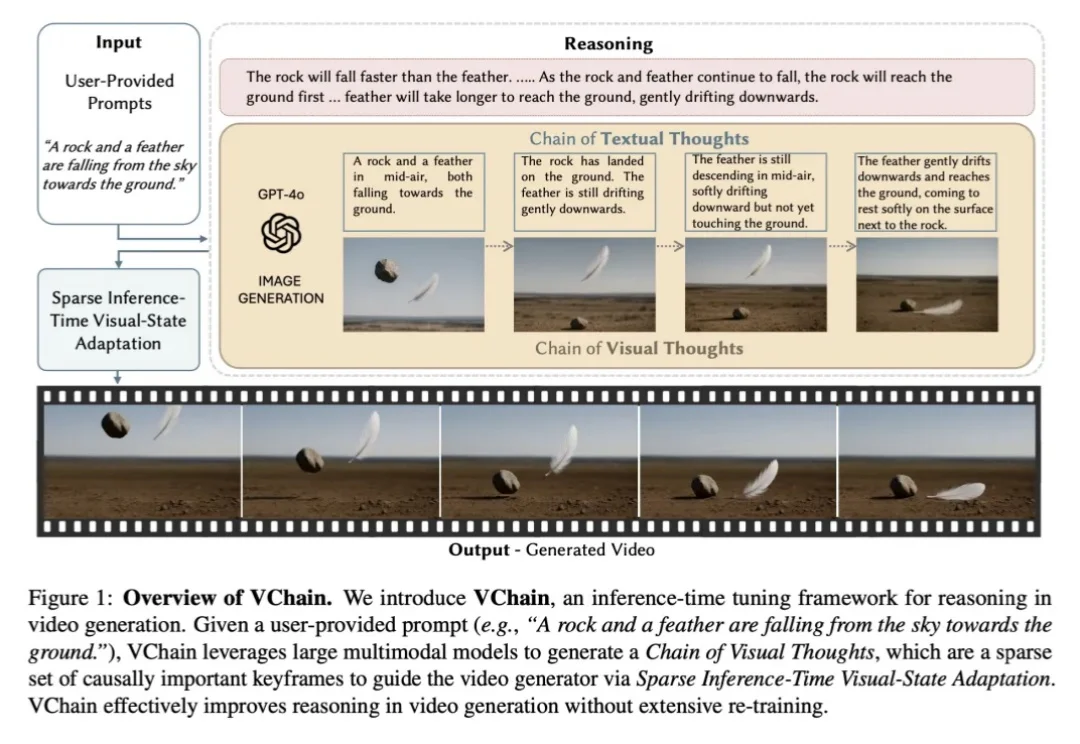
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
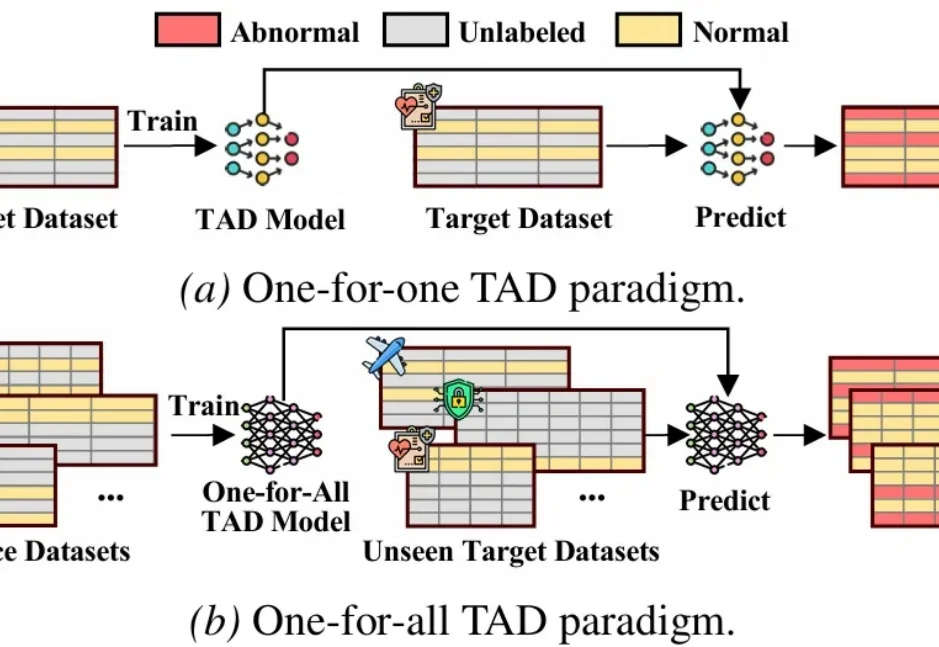
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。

2026 年 5 月的硅谷,对于 AI 算力的“饥荒”和焦虑,正达到一个前所未有的高度。