
又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!
又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!
来自主题: AI技术研报
11169 点击 2024-10-19 14:15
 搜索
搜索
又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!

今天,Meta 分享了一系列研究和模型,这些研究和模型支撑 Meta 实现高级机器智能(AMI)目标,同时也致力于开放科学和可复现性。

训练Transformer,用来解决132年的数学世纪难题!
最新消息,DenseNet 作者之一刘壮将于 2025 年 9 月加盟普林斯顿大学,担任计算机科学系助理教授一职。

行业大震荡来了!IT巨头诺基亚,被曝已在中国裁员2000人。而在美国,英特尔已经已经裁掉超2250人。Meta今年的「裁员大礼包」也如时到来,离谱的是,有人竟因「滥用25美元餐补」被开除?
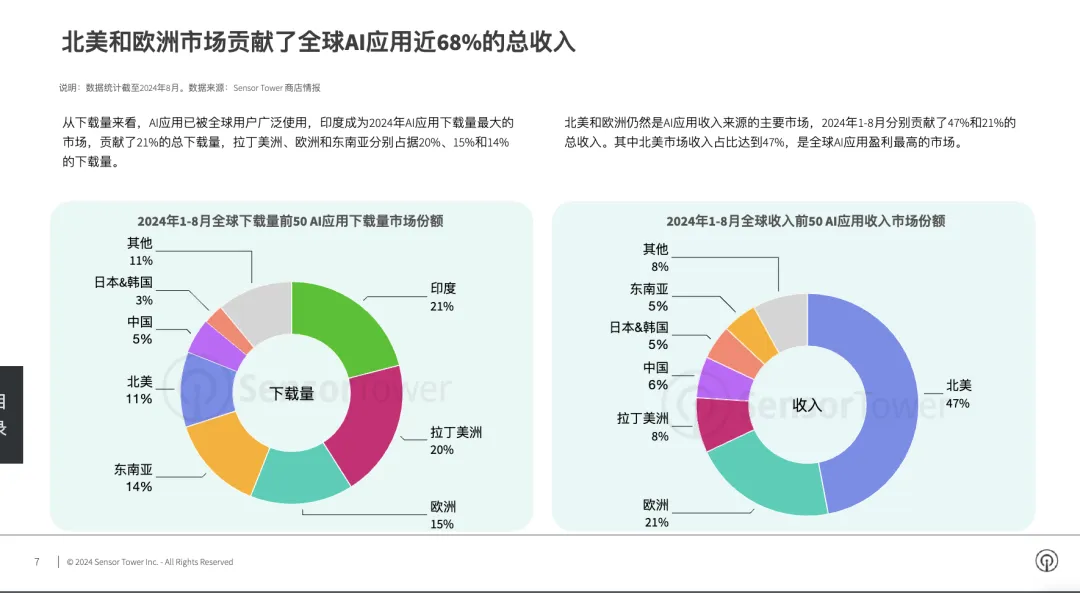
从GPT诞生到现在已经两年了,如果说一开始大模型之战还是属于“神仙打架”,那么2024年AI应用的爆发,让普通人有了更加切身的体会。

在数字人领域,形象的生成需要依赖于基础的表征学习。FaceChain 团队除了在数字人生成领域持续贡献之外,在基础的人脸表征学习领域也一直在进行深入研究。

极大缩短每月记账所需时间,只有会计才能懂这个AI有多好用!
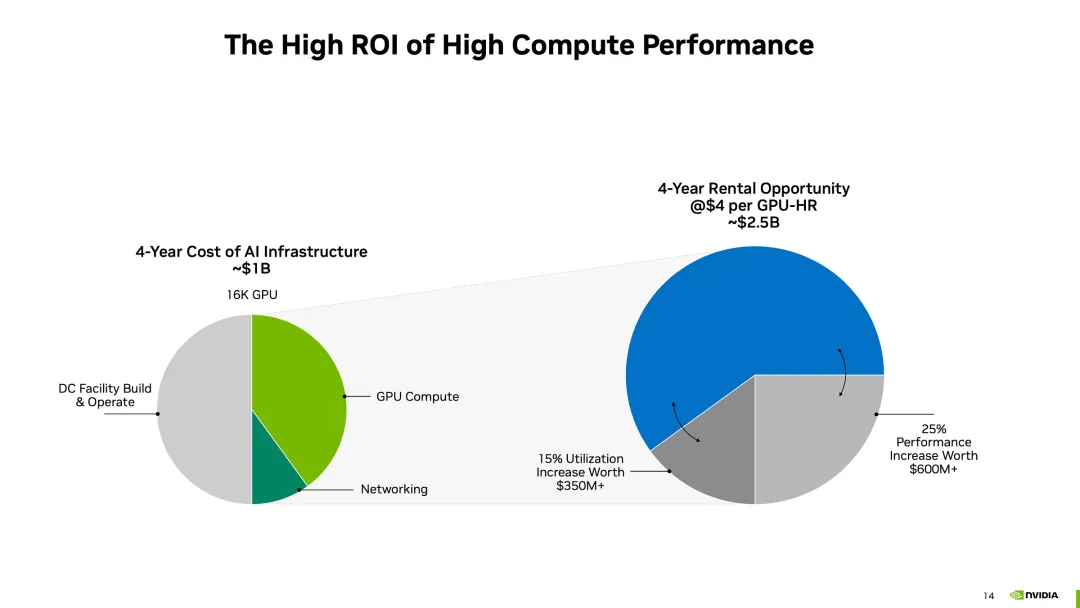
红杉资本的报告曾指出,AI产业的年产值超过6000亿美元,才够支付数据中心、加速GPU卡等AI基础设施费用。而现在一种普遍说法认为,基础模型训练的资本支出是“历史上贬值最快的资产”,但关于GPU基础设施支出的判定仍未出炉,GPU土豪战争仍在进行。

10 月 12 日,一个平平无奇的周六上午,B 站首页给笔者推送了一个名为「EVE」的 AI 社交新品的预告片