电脑平板组AI集群,在家就能跑400B大模型,GitHub狂揽2.5K星
电脑平板组AI集群,在家就能跑400B大模型,GitHub狂揽2.5K星不用H100,三台苹果电脑就能带动400B大模型。 背后的功臣,是GitHub上的一个开源分布式AI推理框架,已经斩获了2.5k星标。
来自主题: AI技术研报
9362 点击 2024-07-23 00:26
 搜索
搜索
不用H100,三台苹果电脑就能带动400B大模型。 背后的功臣,是GitHub上的一个开源分布式AI推理框架,已经斩获了2.5k星标。

Scaling Law还没走到尽头,「小模型」逐渐成为科技巨头们的追赶趋势。Meta最近发布的MobileLLM系列,规模甚至降低到了1B以下,两个版本分别只有125M和350M参数,但却实现了比更大规模模型更优的性能。

多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。

具身智能狂潮降临的一年多里,物理世界与信息的生产与交互方式发生着革命性变化。

东西方AI伴侣的差异化发展

针对视觉-语言预训练(Vision-Language Pretraining, VLP)模型的对抗攻击,现有的研究往往仅关注对抗轨迹中对抗样本周围的多样性,但这些对抗样本高度依赖于代理模型生成,存在代理模型过拟合的风险。
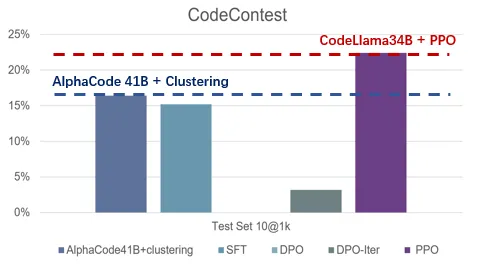
如何让大模型更好的遵从人类指令和意图?如何让大模型有更好的推理能力?如何让大模型避免幻觉?能否解决这些问题,是让大模型真正广泛可用,甚至实现超级智能(Super Intelligence)最为关键的技术挑战。这些最困难的挑战也是吴翼团队长期以来的研究重点,大模型对齐技术(Alignment)所要攻克的难题。
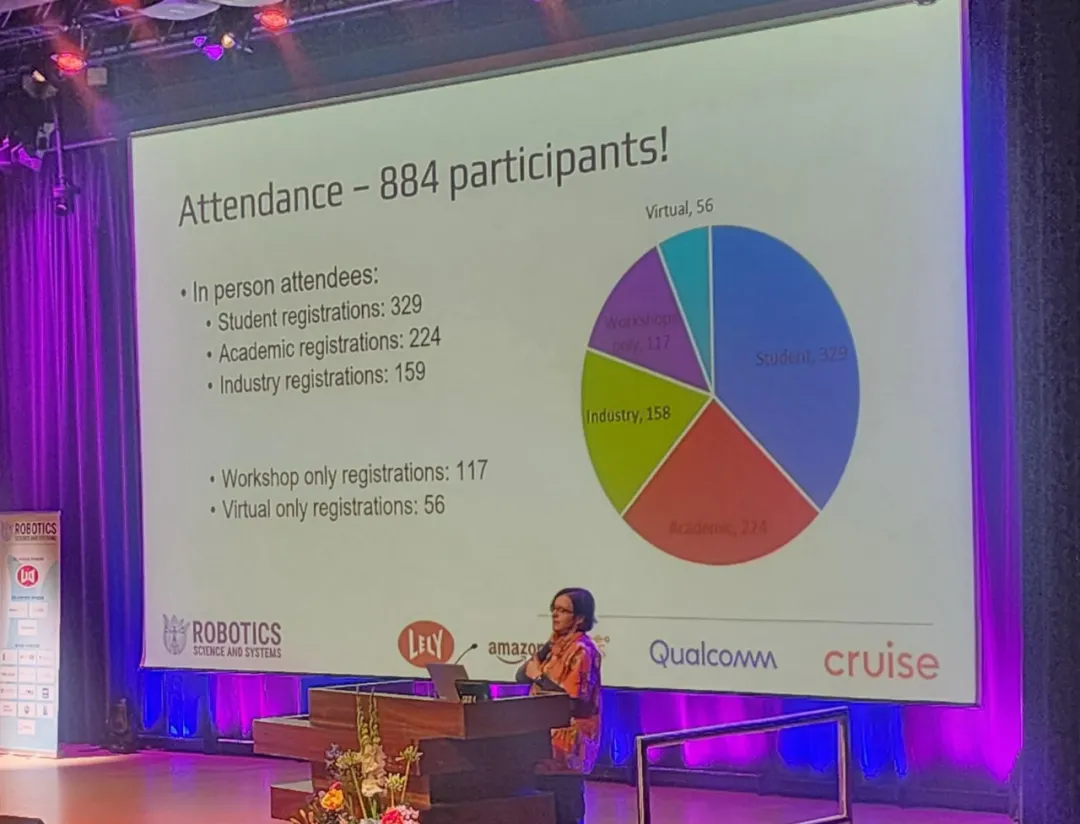
近日,机器人领域著名会议 RSS(Robotics: Science and Systems) 2024 在荷兰代尔夫特理工大学圆满落幕。

在信息爆炸的当今时代,我们如何从浩如烟海的数据中探寻深层次的联系呢?

机器之心独家专访 2011 年诺贝尔经济学奖得主托马斯·萨金特教授