
DeepSeek首轮融资曝光,估值450亿美元
DeepSeek首轮融资曝光,估值450亿美元据金融时报的最新消息,多家机构目前正寻求领投 DeepSeek 的首轮融资。如果谈判顺利,DeepSeek 在本轮的估值将达到约 450 亿美元。短短几周内,DeepSeek 的估值就从刚开始被爆料的 200 亿美元一路狂飙翻倍。
来自主题: AI资讯
9497 点击 2026-05-06 16:46
 搜索
搜索
据金融时报的最新消息,多家机构目前正寻求领投 DeepSeek 的首轮融资。如果谈判顺利,DeepSeek 在本轮的估值将达到约 450 亿美元。短短几周内,DeepSeek 的估值就从刚开始被爆料的 200 亿美元一路狂飙翻倍。

独家获悉,Kimi (月之暗面)即将完成新一轮 20 亿美元融资,投后估值突破 200 亿美元。本轮融资由美团龙珠领投,中国移动、CPE(中信产业基金)等参投,其中仅龙珠就出手超 2 亿美元。

2026 年 3 月底,Ollama 发布了一则更新公告:其 Mac 版本的底层推理引擎,将从沿用多年的 llama.cpp 切换为苹果的 MLX 框架。

2026年5月4日,testingcatalog在Anthropic的Web/Mobile客户端里挖出隐藏功能Orbit。5月6日,Code with Claude大会在旧金山开幕。Orbit不等你开口就从Gmail、Slack、GitHub里替你干活了。
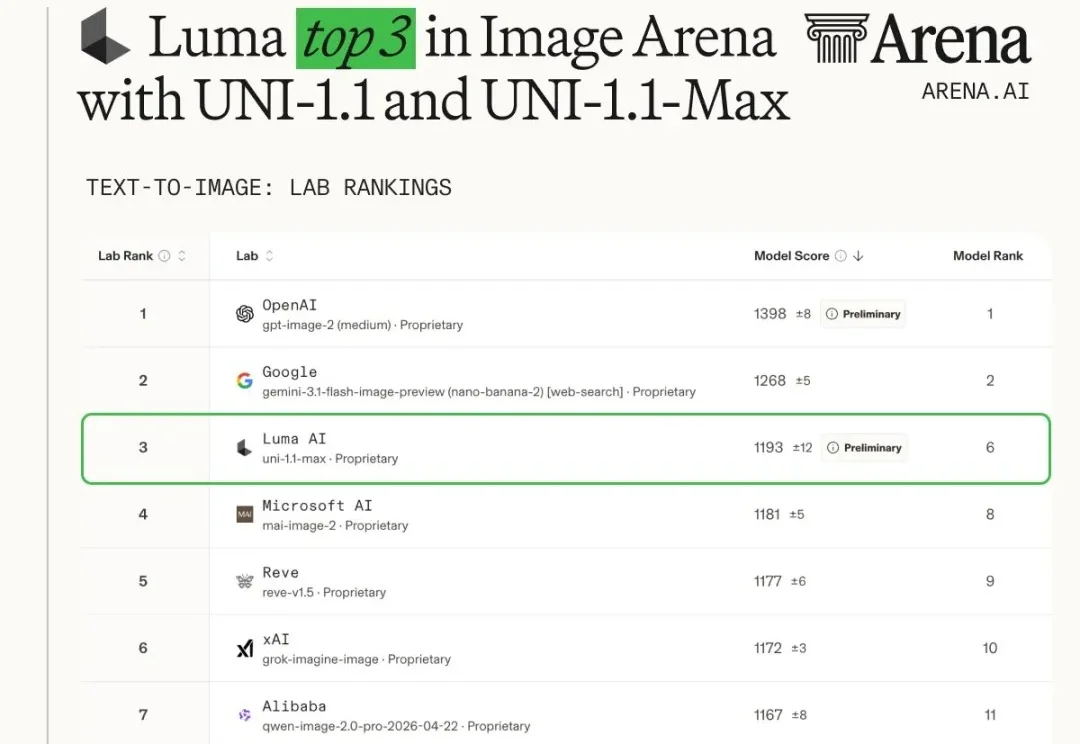
今年以来,图像生成模型的迭代节奏明显加快。

1000亿美元砸向AWS算力,5座核电站级别的能耗,营收狂飙至300亿——Anthropic和亚马逊刚刚签下了AI史上最疯狂的「军火合同」。

你有没有想过,为什么 AI 读一篇短文游刃有余,却在面对一整个代码库时频频出错?

我在淘宝上花了28块钱,买了一个很奇葩的东西。

2026 年,「数据」正成为具身智能竞赛的新焦点,京东、百度等科技巨头纷纷入局。然而,喧嚣之中,一个根本问题悬而未决:什么样的数据,才是具身智能真正需要的?

独家获悉,字节跳动日前低调公布全球首个25B级、基于混合专家 (MoE) -扩散自注意力机制(DiT) 的开源增强统一多模态模型Mamoda2.5。Mamoda2.5依托Qwen3-VL-8B、128 个专家,Top-8 路由的MoE+DiT架构搭建,最终模型参数高达250亿,而每次仅激活约30亿参数(约12%)。