刚刚,硅谷这篇文章刷屏了!
刚刚,硅谷这篇文章刷屏了!今天,硅谷一篇长文《The next biggest moat in AI》刷屏了,作者是 Foundation Capital 合伙人、前麦肯锡咨询师 Jaya Gupta。这篇文章在 X 上 12 小时获得了130万阅读,被一群创始人和打工人同时转发,原因是它同时提供了两套视角:
来自主题: AI资讯
9051 点击 2026-05-10 14:43
 搜索
搜索
今天,硅谷一篇长文《The next biggest moat in AI》刷屏了,作者是 Foundation Capital 合伙人、前麦肯锡咨询师 Jaya Gupta。这篇文章在 X 上 12 小时获得了130万阅读,被一群创始人和打工人同时转发,原因是它同时提供了两套视角:

数学界尘封32年的拉姆齐数经典难题被打破!浙大校友王宜平借助自研AI框架ScaleAutoResearch-Ramsey,成功将拉姆齐数R(3,17) 下界从92提升至93,终结了自1994年以来长期停滞的纪录。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。

Nacos 作为 Skill Registry AI Agent 进入日常工作流后,能力复用的载体正在发生变化。 过去,我们复用的是脚本、配置、模板和文档;现在,越来越多可复用经验会被沉淀成 Skil
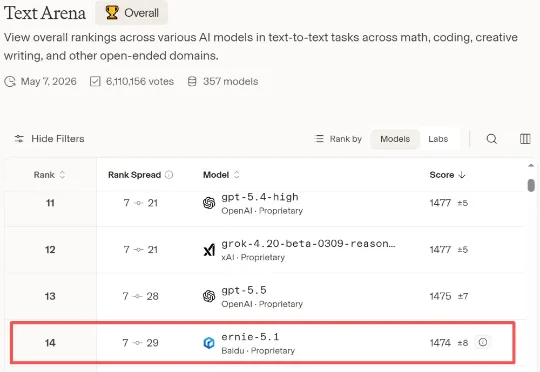
今日,百度推出新一代基础模型文心5.1。百度称,文心5.1将总参数压缩至约1/3、激活参数压缩至约1/2,使用业界同规模模型约6%的预训练成本,实现同级别模型基础效果领先。不过,百度并未明确说明这一“6%成本”的具体对标模型范围与口径。

2025 年圣诞前夕,一款名叫 Rezona 的 AI 互动内容平台在海外上线,不到 4 个月时间,周活就超过 150 万,海外创作者社群超过 3 万人,并在年后快速完成了四轮融资。

日前,上海基流科技股份有限公司(下称:基流科技)正式向港交所递交招股书,冲击港股 “AI基础设施第一股”,独家保荐人为国泰海通。基流科技目前是中国规模最大的独立AI算力集群提供商。这家公司成立三年即冲刺IPO,以清北学霸为核心班底,3名执行董事都是“90后”——33岁的董事长胡效赫、35岁的联席董事长王旭阳、33岁的联席首席执行官谢文奇。

4月,DeepSeek(深度求索)罕见展开一场巨额融资计划,同时吸引了腾讯和阿里巴巴两家大厂。我们独家获悉,近期,阿里巴巴和DeepSeek谈崩了。一位接近DeepSeek的人士告诉我们,双方未能在融资具体条款上达成一致。一方面,阿里的自有生态对DeepSeek而言,适配度不高,而DeepSeek也不缺乏外部注资的候选股东,希望尽量减少条款层面的束缚。

刚刚,阿里旗下首款AI眼镜——千问AI眼镜S1迎来开售后的首次重磅更新,发布了海量新功能升级。从AI主动编排执行复杂任务、AI制定运动计划、AI订票点外卖到AI扫单车、AI拍照解题等,智东西第一时间现场体验了这些新功能。
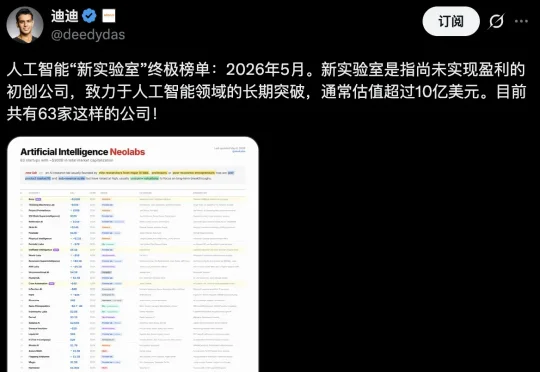
63家AI新实验室,总估值约3000亿!Ilya在搞安全超级智能,Murati在重建通用架构,贝佐斯在造机器人,孙正义押注具身智能……这不是一份融资名单,更是一场胜率未知的基础研究豪赌。