
生产力提升30%!微软最大规模调研报告出炉,AI工具成打工人效率神器
生产力提升30%!微软最大规模调研报告出炉,AI工具成打工人效率神器AI在现实工作环境中如何影响了工作效率?微软发起一项最大规模的调查研究,AI工具在工作场景中最大提效30%。
来自主题: AI技术研报
11089 点击 2024-08-14 17:02
 搜索
搜索
AI在现实工作环境中如何影响了工作效率?微软发起一项最大规模的调查研究,AI工具在工作场景中最大提效30%。

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?

Mamba 架构的大模型又一次向 Transformer 发起了挑战

TII开源全球第一个通用的大型Mamba架构模型Falcon Mamba 7B,性能与Transformer架构模型相媲美,在多个基准测试上的均分超过了Llama 3.1 8B和Mistral 7B。

三维数字人生成和编辑在数字孪生、元宇宙、游戏、全息通讯等领域有广泛应用。传统三维数字人制作往往费时耗力,近年来研究者提出基于三维生成对抗网络(3D GAN)从 2D 图像中学习三维数字人,极大提高了数字人制作效率。

今年 3 月份,英伟达 CEO 黄仁勋举办了一个非常特别的活动。他邀请开创性论文《Attention Is All You Need》的作者们齐聚 GTC,畅谈生成式 AI 的未来发展方向。
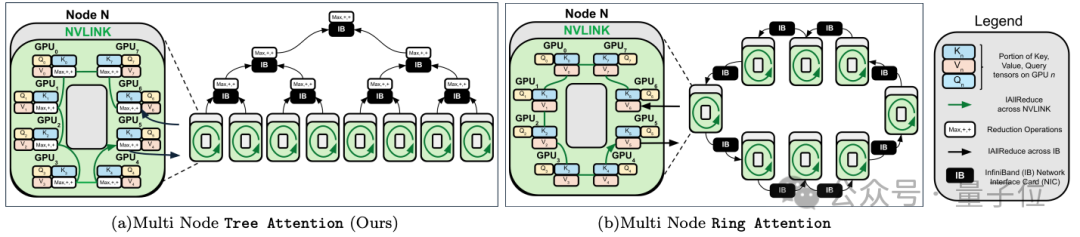
跨GPU的注意力并行,最高提速8倍,支持512万序列长度推理。

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。

ChatGPT,就是新的Excel! 红杉资本分析师、Every联合创始人兼CEO Dan Shipper,最近给出了这样的论断。 并且,他在长篇博客中做出了详实的分析,为什么ChatGPT和Claude将催生下一波初创公司,催生出三千多亿美元的市场。

2024年,投资市场的钱都流向了哪里?