
阿里刚开源32B大模型,我们立马测试了“弱智吧”
阿里刚开源32B大模型,我们立马测试了“弱智吧”阿里的通义千问(Qwen),终于拼齐了1.5系列的最后一块拼图—— 正式开源Qwen 1.5-32B。
来自主题: AI技术研报
8562 点击 2024-04-08 10:09
 搜索
搜索
阿里的通义千问(Qwen),终于拼齐了1.5系列的最后一块拼图—— 正式开源Qwen 1.5-32B。

在这个风起云涌的 AI 时代,一场前所未有的资本军备竞赛正在火热上演。算力、算法、数据,这些被视为 AI 领域的三大基石,正成为各大公司争夺的焦点。然而,在这场看似技术驱动的竞赛背后,低成本资金的获取却成为了决定胜负的隐形推手。

在大模型落地应用的过程中,端侧 AI 是非常重要的一个方向。近日,斯坦福大学研究人员推出的 Octopus v2 火了,受到了开发者社区的极大关注,模型一夜下载量超 2k。20 亿参数的 Octopus v2 可以在智能手机、汽车、个人电脑等端侧运行,在准确性和延迟方面超越了 GPT-4,并将上下文长度减少了 95%。此外,Octopus v2 比 Llama7B + RAG 方案快 36 倍。
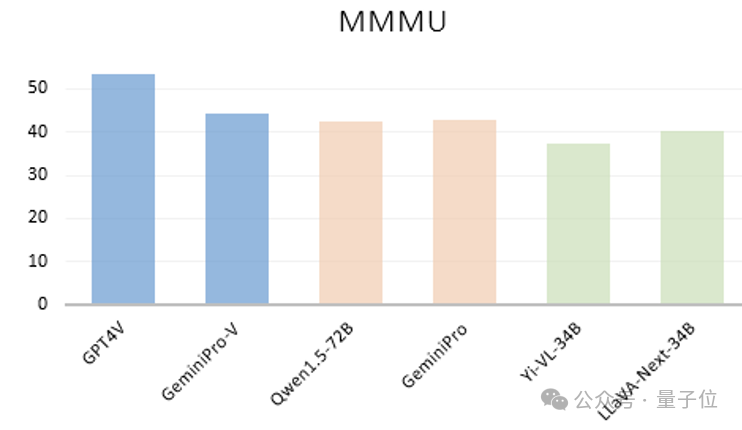
大模型不看图,竟也能正确回答视觉问题?!中科大、香港中文大学、上海AI Lab的研究团队团队意外发现了这一离奇现象。他们首先看到像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,竟然只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。

全球每年有近 500 万人死于抗生素耐药性,因此迫切需要新的方法来对抗耐药菌株。AI 方法可以发现新的抗生素,但现有方法有明显的局限性。性质预测模型很难扩展到大型化学空间。直接设计分子的生成模型可以快速探索广阔的化学空间,但生成的分子难以合成。

模仿人类阅读过程,先分段摘要再回忆,谷歌新框架ReadAgent在三个长文档阅读理解数据集上取得了更强的性能,有效上下文提升了3-20倍。

一家来自纽约的初创公司Hume AI发布了一款标榜为「第一个具有情商的对话式人工智能」的共情语音接口(EVI),并表示其能够从用户那里检测到53种不同的情绪。

一年一度的CVPR 2024录用结果出炉了。今年,共有2719篇论文被接收,录用率为23.6%。
「这是自 Karpathy 和我 2015 年启动这门课程以来的第 9 个年头,这是人工智能和计算机视觉令人难以置信的十年!」知名 AI 科学家李飞飞的计算机视觉「神课」CS231n,又一次开课了。

据国外媒体报道,特斯拉和SpaceX的首席执行官埃隆·马斯克(Elon Musk)日前在“丰富峰会”上与奇点大学和XPRIZE基金会创始人彼得·戴曼迪斯(Peter Diamandis)进行了线上对话。这次峰会由硅谷的奇点大学主办,该大学致力于向商业领袖提供前沿技术咨询。XPRIZE基金会通过举办科学竞赛推动科技创新,其中一些项目得到了马斯克的资助。