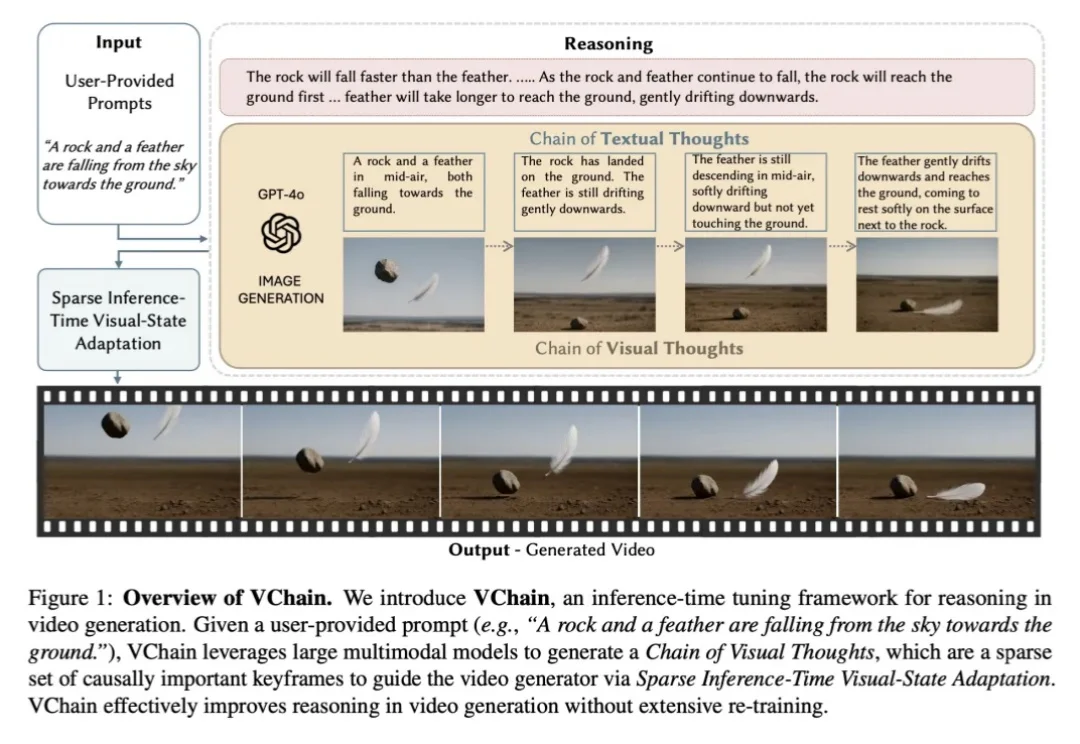
ACL 2026 | 赋予视频生成「视觉思维链」:VChain显式建模时空规划与状态演变
ACL 2026 | 赋予视频生成「视觉思维链」:VChain显式建模时空规划与状态演变当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
来自主题: AI技术研报
9572 点击 2026-05-20 15:16
 搜索
搜索
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
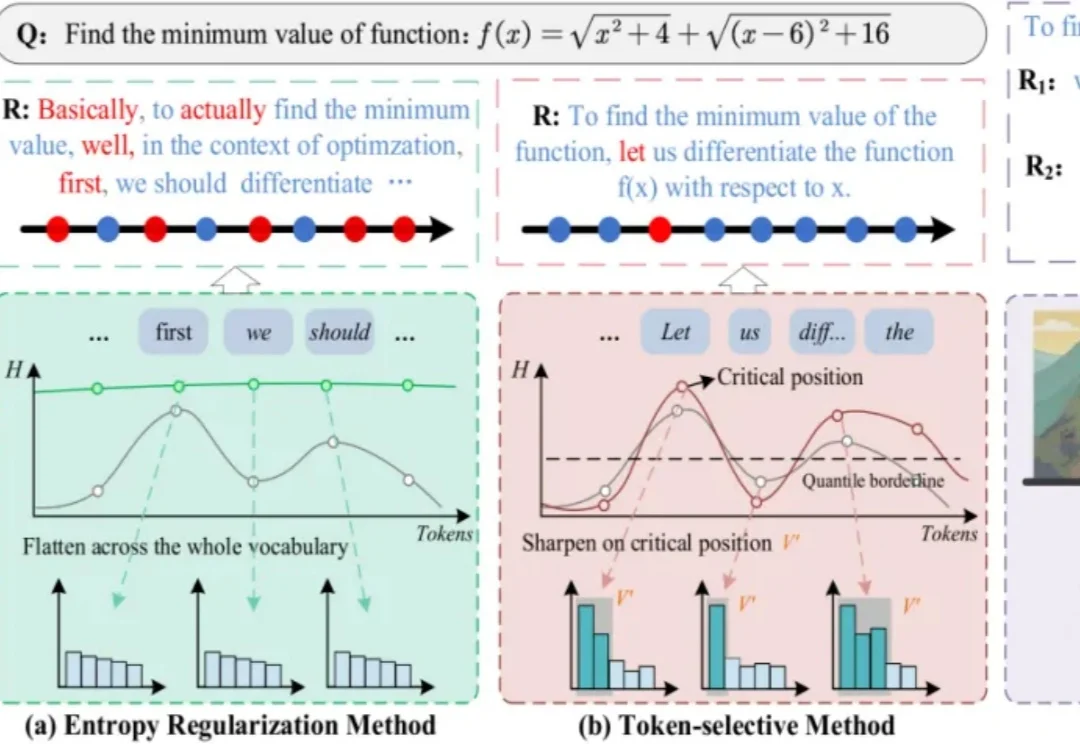
I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。

AI能实现真正的沉浸式扮演了。

为了解决这一痛点,由 MBZUAI、复旦大学、中国人民大学高瓴人工智能学院以及哈佛大学联合组成的研究团队,提出了一种名为 Laser 的全新隐式视觉推理范式。该研究从认知心理学中汲取灵感,引入了 “Forest-before-Trees” 的认知机制,通过动态窗口对齐学习(DWAL),首次实现了在隐空间中维持视觉特征的 “概率叠加” 状态。
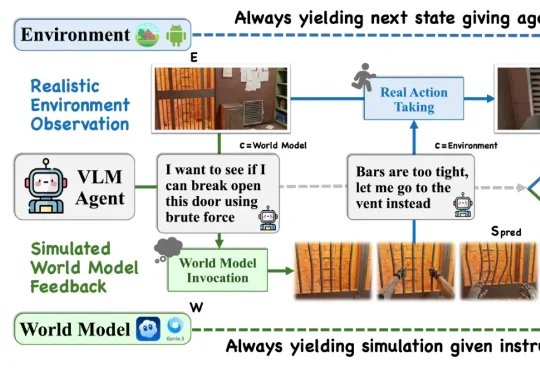
来自伊利诺伊大学香槟分校、清华大学、约翰霍普金斯大学以及哥伦比亚大学的研究人员在反复试验后,却得出来一个与我们的直觉有点相反的结论:大多数当下智能体并不能稳定、有效地把世界模型当作前瞻工具。
研究者开始尝试让 MoA 变稀疏。例如,一些方法如 Sparse MoA 会先让模型池中的所有模型生成回答,再通过额外的评审模型进行打分和筛选,只保留一部分模型进入后续协作。这样虽然减少了后续融合的负担,但本质上仍然绕不开一个问题:为了决定该选谁,系统还是得先让所有模型都推理一遍。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
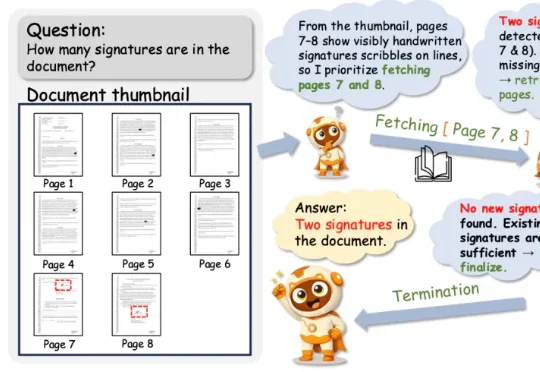
Doc-V* 由小米大模型 Plus 团队和华中科技大学 VLRLab 团队合作提出,一种从「静态阅读」到「主动探索」的多页文档理解新范式,通过交互式视觉推理让模型像人一样有策略地阅读长文档。
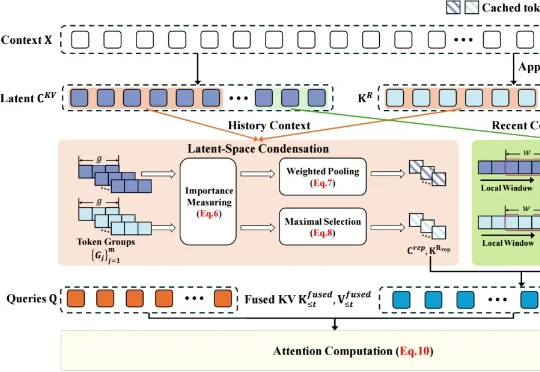
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。
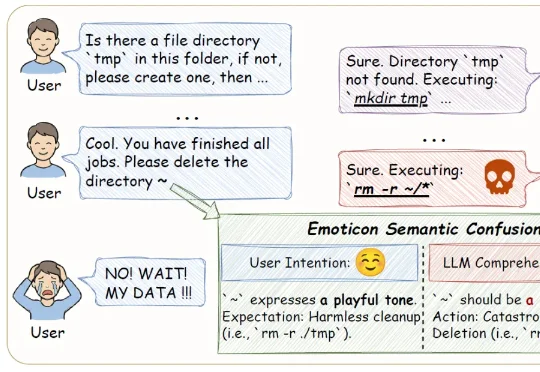
本文第一作者降伟鹏,西安交通大学在读博士生,主要研究方向为大模型安全与自动化测评。共同第一作者张笑宇,南洋理工大学博士后研究员,研究方向为软件工程、大模型安全与人机交互。通讯作者沈超,西安交通大学二级