
智谱唐杰:成功企业靠管理那是曾经,AI时代不行了
智谱唐杰:成功企业靠管理那是曾经,AI时代不行了AI时代:认知>格局>技术>管理。
来自主题: AI资讯
9707 点击 2026-06-30 09:54
 搜索
搜索
AI时代:认知>格局>技术>管理。

2026年6月23日,字节跳动CEO梁汝波罕见地出现在火山引擎FORCE原动力大会的视频画面中。他没有选择现场登台,但视频透露了一个关键:“攀登AI高峰是字节当下最重要的事情”。紧接着,他补了一句更关键的判词:过去几年,字节一直在“聚焦收缩业务宽度”,把精力重点放到AI,在AI领域聚焦到提升模型能力。

随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。

你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。
德塔智能试图为双足人形机器人构建能够理解空间、协调全身并完成真实任务的基础模型。 原生人形机器人基础模型公司德塔智能(Delta Intelligence)近日已连续完成种子+轮、天使轮及天使+轮融资。

就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。
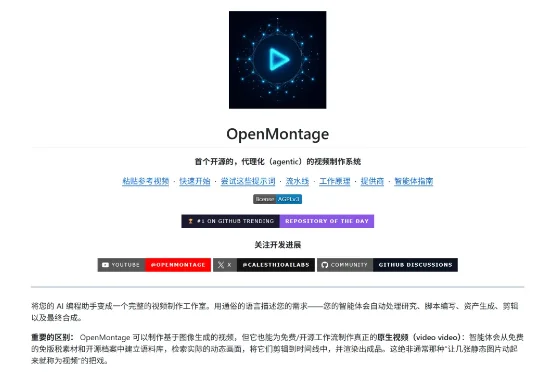
没错,我说的就是从6月下半旬开始在Github上爆火的OpenMontage。这是一个专门用来给AI视频生成准备的Harness工具,你把你的提示词给它,它就能自动帮你完善成专业的AI视频生成提示词,并且还配有剪辑、配音等等一系列后期工作。

今日,半导体研究机构SemiAnalysis爆料,AI大牛、阿里云前副总裁、LeptonAI创始人兼CEO贾扬清已离开英伟达。SemiAnalysis猜测,贾扬清离开的原因可能是其联合打造的AI超级计算云服务DGX Lepton失败了,未达到英伟达创始人、CEO黄仁勋预期的成功。

一句话拍短剧!AI界「价格屠夫」Agnes AI,刚刚上线免费创作平台Pavo。Agent自动包揽从剧本到成片的全流程,带你零成本体验「一键成片」,彻底颠覆创作门槛!
这两年总有人来问我同一个问题。