
Meta炸了!LeCun炮轰28岁上司不懂行,实锤Llama 4刷榜丑闻
Meta炸了!LeCun炮轰28岁上司不懂行,实锤Llama 4刷榜丑闻图灵奖大佬LeCun离职Meta后直接开怼:实锤Llama4造假传闻,炮轰原上司Alexandr Wang「不懂科研」,称Meta冲刺「超级智能」完全是被大模型洗脑。同时,他也透露自己的新公司即将在今年发布全新世界模型。
来自主题: AI资讯
8987 点击 2026-01-03 22:24
 搜索
搜索
图灵奖大佬LeCun离职Meta后直接开怼:实锤Llama4造假传闻,炮轰原上司Alexandr Wang「不懂科研」,称Meta冲刺「超级智能」完全是被大模型洗脑。同时,他也透露自己的新公司即将在今年发布全新世界模型。

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。

人类打字速度,竟成了制约AGI的瓶颈?近日,OpenAI Codex负责人Alexander Embiricos爆出了这一惊人观点。Embiricos还预测,2026年,当AI开始在一些领域具备自我审查能力,将触发生产力出现「曲棍球杆式」飞跃增长,并带动人类迈向AGI。

提起马卡龙,你会想到什么?是橱窗里的精致甜点,一种“少女心”的味觉象征?还是代表了温柔优雅的时尚配色?当一个AI产品也被命名为“马卡龙”,这份联想便悄然发生了偏移:从舌尖的甜,转向科技的未知,却又奇妙地保留了那一份色彩与气质。
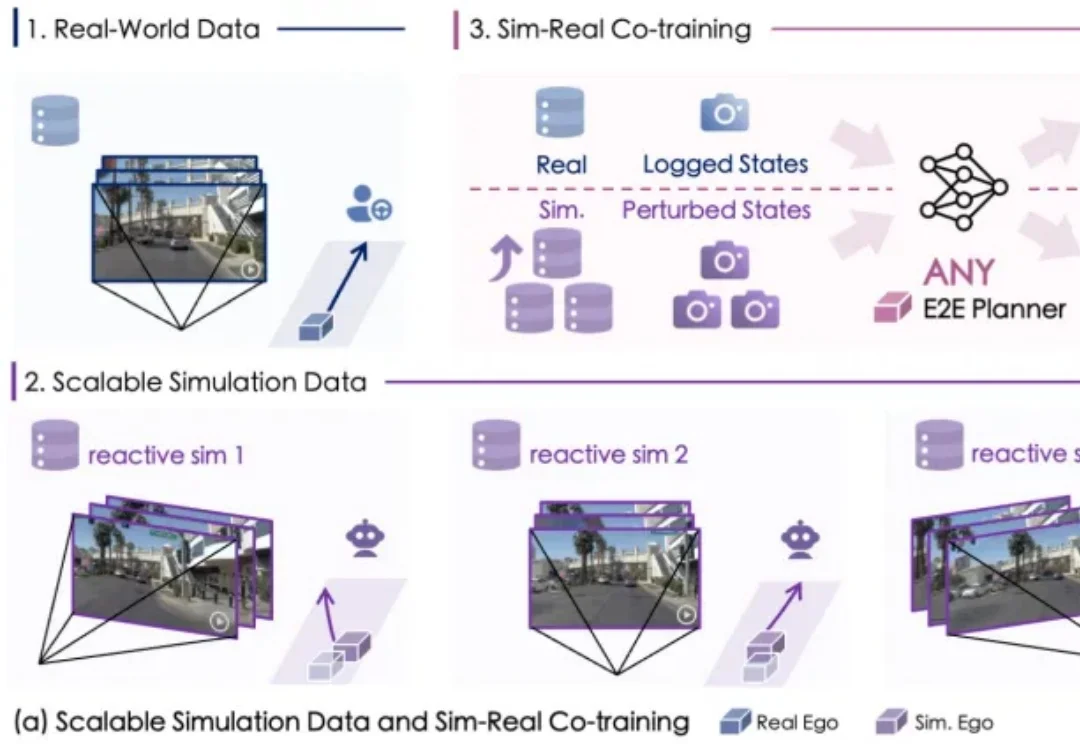
自动驾驶数据荒怎么破?

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。
就在前天,DeepSeek 一口气上新了两个新模型,DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。

DeepSeek-V3.2很强很火爆,但随着讨论的深入,还是有bug被发现了。 并且是个老问题:浪费token。不少网友都提到,DeepSeek-V3.2的长思考增强版Speciale,确确实实以开源之姿又给闭源TOP们上了压力,但问题也很明显:

Perplexity 的首席执行官 Aravind Srinivas 曾直言不讳:“世上万物皆是套壳(Everything is a wrapper)。OpenAI 套的是英伟达的算力和 Azure 的云服务;Netflix 套的是 AWS 的基础设施;就连市值高达 3200 亿美元的 Salesforce,归根结底也不过是 Oracle 数据库的一个高级外壳。”你

突袭!ChatGPT发布三周年,DeepSeek嚯一下发出两个模型:DeepSeek-V3.2和DeepSeek-V3.2-Speciale。前者聚焦平衡实用,适用于日常问答、通用Agent任务、真实应用场景下的工具调用。