Meta用40万个GPU小时做了一个实验,只为弄清强化学习Scaling Law
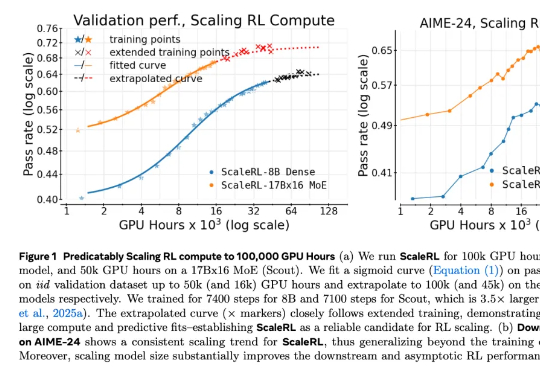
Meta用40万个GPU小时做了一个实验,只为弄清强化学习Scaling Law在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?
来自主题: AI技术研报
9934 点击 2025-10-19 17:54
 搜索
搜索
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?

近日,谷歌与耶鲁大学联合发布的大模型C2S-Scale,首次提出并验证了一项全新的「抗癌假设」。这一成果表明,大模型不仅能复现已知科学规律,还具备生成可验新科学假设的能力。
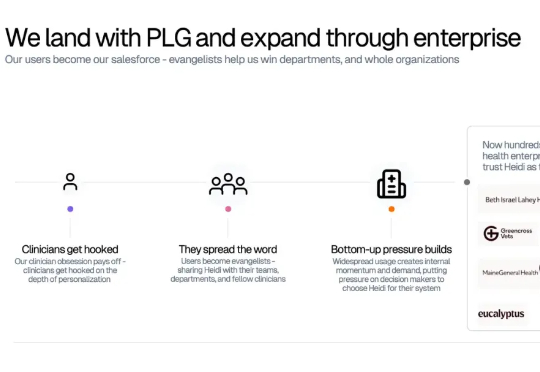
2021年,他与技术合伙人 Waleed Mussa 共同创立了 Heidi Health。仅仅18个月后,这家公司就将超过1800万小时的时间还给了一线医疗工作者,支持了超过7300万次患者就诊,覆盖116个国家。而就在最近,Heidi Health 宣布完成了6500万美元的B轮融资,

大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。

靠AI挖出了癌症潜在新疗法,AI医疗领域再添猛将。谷歌、耶鲁联手,给攻克冷肿瘤找到了新方法。
来自加拿大蒙特利尔三星先进技术研究所(SAIT)的高级 AI 研究员 Alexia Jolicoeur-Martineau 介绍了微型递归模型(TRM)。这个 TRM 有多离谱呢?一个仅包含 700 万个参数(比 HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,
来自 UIUC 与 Salesforce 的研究团队提出了一套系统化方案:UserBench —— 首次将 “用户特性” 制度化,构建交互评测环境,用于专门检验大模型是否真正 “懂人”;UserRL —— 在 UserBench 及其他标准化 Gym 环境之上,搭建统一的用户交互强化学习框架,并系统探索以用户为驱动的奖励建模。
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”

Alex 是一家开发 AI 招聘官的初创公司,该公司表示其技术已帮助企业进行视频面试和电话初筛。约18 个月前联合创办 Alex 的王亚伦(图中下排居中)向 TechCrunch 透露,该公司的语音 AI 工具能在求职者投递简历后立即开展自主面试。"我们的 AI 招聘官每天进行数千场面试,帮助求职者进入全球顶尖企业工作,"他说道。
一家来自印度苏拉特的创业公司 Rocket.new 却声称他们解决了这个问题。不仅如此,他们还刚刚完成了1500万美元的种子轮融资,由Salesforce Ventures和Accel联合领投,Together Fund跟投。更令人惊讶的是,这家公司从beta版上线到完成融资仅用了3个月时间,目前已经拥有40万用户,分布在180个国家,年收入达到450万美元。