
Agent评测的下半场:为什么需要一个「活的」Benchmark?
Agent评测的下半场:为什么需要一个「活的」Benchmark?Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。
来自主题: AI技术研报
6456 点击 2026-05-11 16:08
 搜索
搜索
Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。

就在今天,Carnegie Mellon University(CMU:卡内基梅隆大学)2026 年毕业典礼上,身价逼近 1860 亿美元的「皮衣刀客」黄仁勋站上演讲台,接过科学与技术荣誉博士学位。

上次开源 guizang-ppt-skill(github.com/op7418/guizang-ppt-skill) 之后,大家都非常喜欢,短短几周 Github Star 来到了 6000 多。

AI能实现真正的沉浸式扮演了。

GENE-26.5 值得看的,是它背后的「具身智能版 Harness + 模型」。
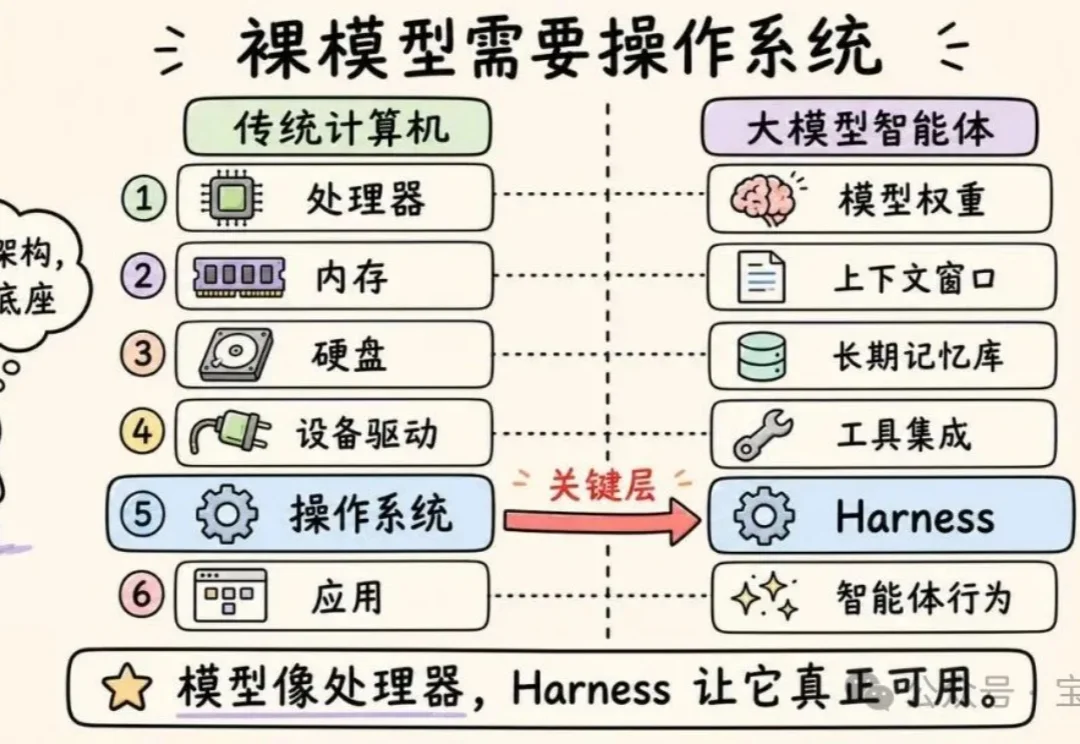
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
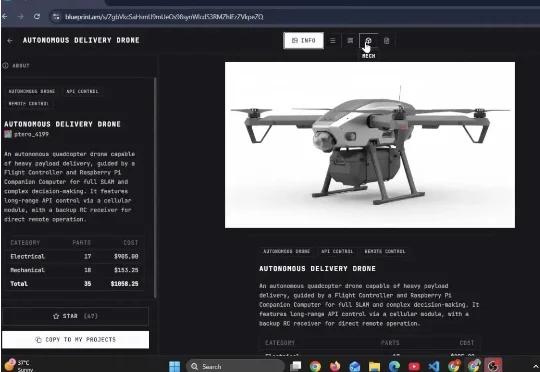
大家好,最近有人刚刚为电子产品开发了一个 Claude Code 工具。 它叫做 Blueprint。输入你想要构建的内容,它就会为你的 Arduino 或树莓派项目生成接线图、物料清单和分步组装指南。能不能自己搭建一个呢?

数学界尘封32年的拉姆齐数经典难题被打破!浙大校友王宜平借助自研AI框架ScaleAutoResearch-Ramsey,成功将拉姆齐数R(3,17) 下界从92提升至93,终结了自1994年以来长期停滞的纪录。

最近,研究机构Palisade Research发布了一项令整个行业震惊的成果—— 研究员在终端只输入了4个单词,AI就完成了从黑客攻击到自我繁衍的全过程。这是AI通过黑客手段实现自我复制的首个纪录!
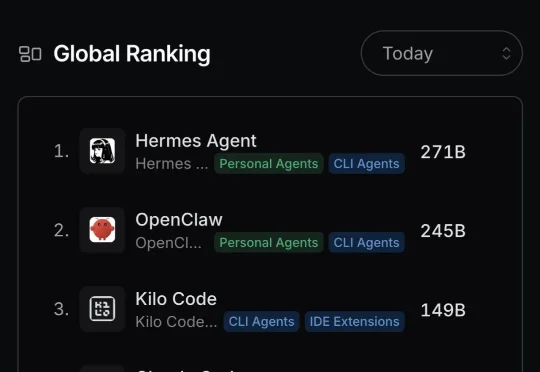
5月9日,Hermes Agent(昵称:爱马仕)登顶OpenRouter全球应用调用量榜首,首次超越OpenClaw(昵称:龙虾)。据OpenRouter应用Token消耗榜最新数据,这一Nous Research旗下开源自进化Agent产品登顶全球应用Token消耗榜,单日Token消耗量达到271B,也就是2710亿Token。