三思而后行,让大模型推理更强的秘密是「THINK TWICE」?
三思而后行,让大模型推理更强的秘密是「THINK TWICE」?近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
来自主题: AI技术研报
10405 点击 2025-04-06 16:55
 搜索
搜索
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
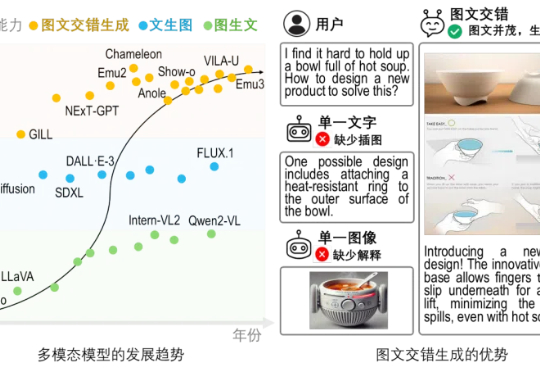
文生图 or 图生文?不必纠结了!

DeepSeek新论文来了!在清华研究者共同发布的研究中,他们发现了奖励模型推理时Scaling的全新方法。DeepSeek R2,果然近了。
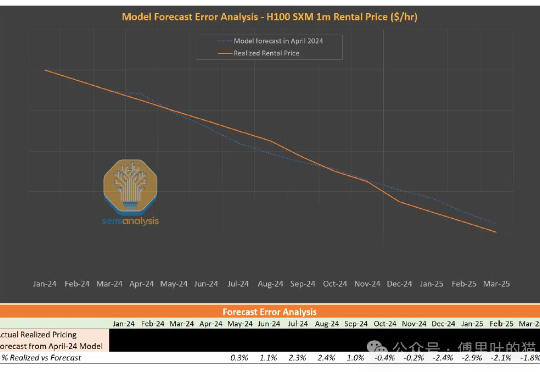
前几天有朋友还在问我GPU租赁市场的情况,正好SemiAnalysis出了这篇文章:GPU云ClusterMA评级系统 | GPU租用指南。

通过完全启用并发多块执行,支持任意专家数量(MAX_EXPERT_NUMBER==256),并积极利用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE Align & Sort逻辑被精心设计,实现了显著的性能提升:A100提升3倍,H200提升3倍,MI100提升10倍,MI300X/MI300A提升7倍...
在InternVL-2.5上实现10倍吞吐量提升,模型性能几乎无损失。
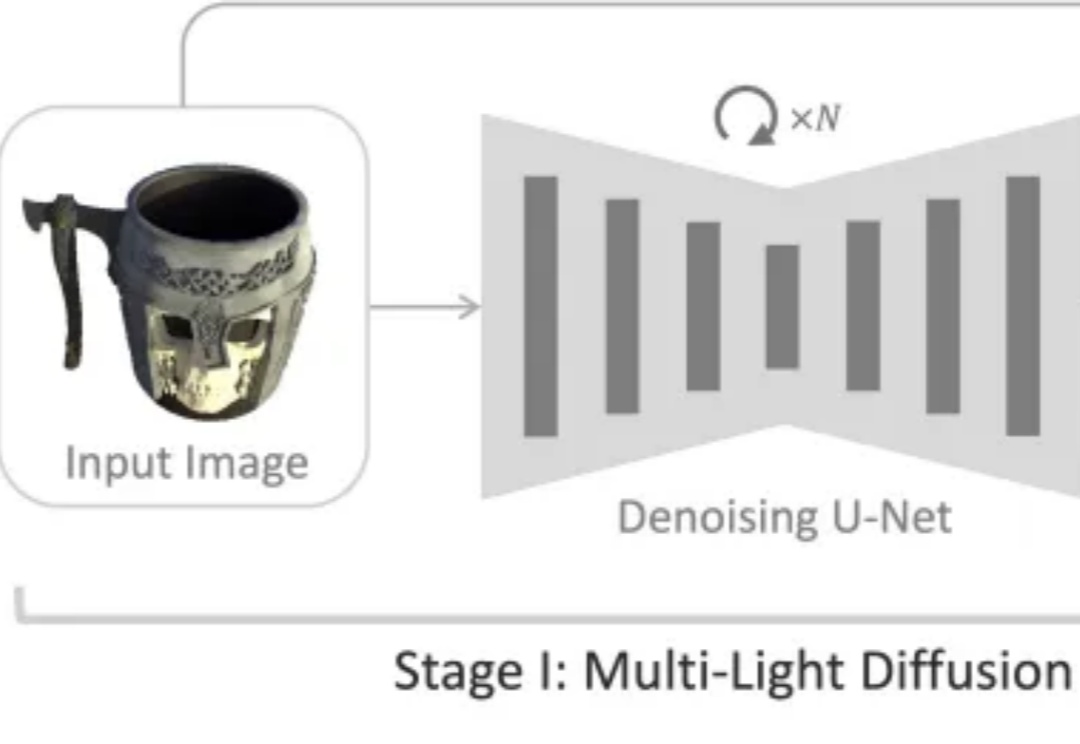
如何从一张普通的单幅图像准确估计物体的三维法线和材质属性,是计算机视觉与图形学领域长期关注的难题。
刚刚,Local AI 领域的 Libra 团队发布了一段最新技术演示视频,展示了用户通过自然语言交互直接生成 Agent,并利用本地消费级算力支持 Agent 进行长程 (Long-Horizon) 推理,最终完成复杂任务。

3月31日,AI制药公司Isomorphic Labs宣布在第一次外部融资中筹集了6亿美元,由Thrive Capital领投,GV参投,现有投资者谷歌母公司Alphabet跟投。Isomorphic Labs成立于2021年,创始人兼CEO为2024年诺贝尔化学奖得主Demis Hassabis,其使命是运用AI治疗所有疾病。
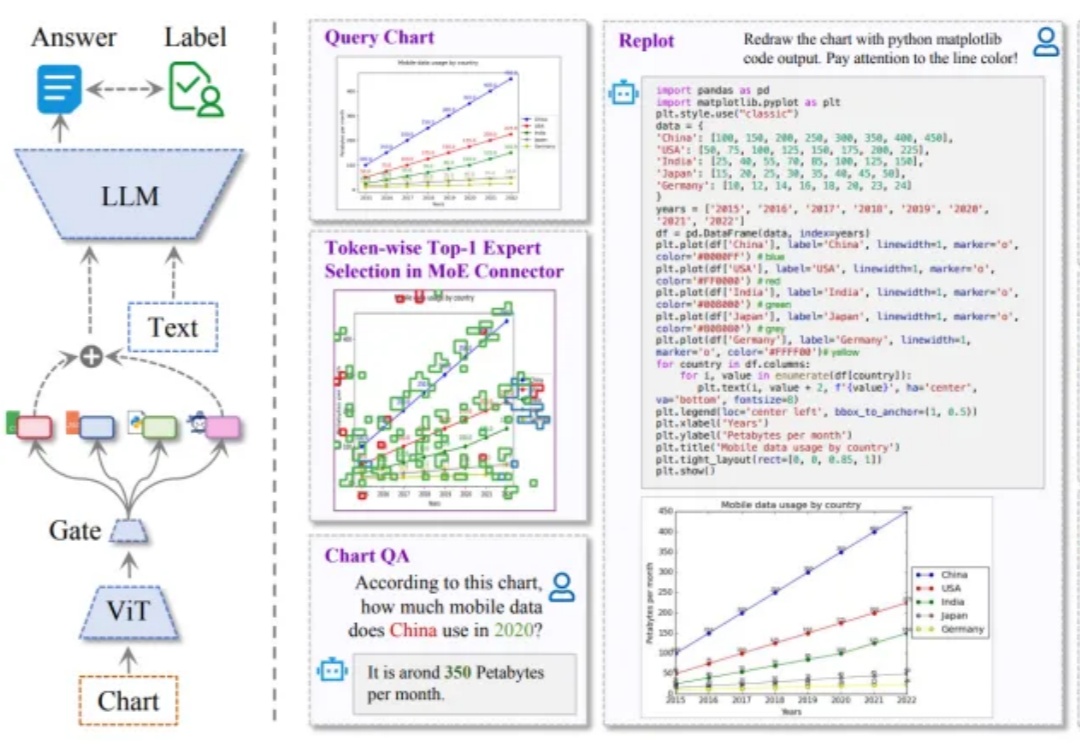
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%