
美国大学生已经提前开始为AI打工了
美国大学生已经提前开始为AI打工了美国大学生已经提前开始为AI打工了
来自主题: AI资讯
6806 点击 2025-03-19 10:08
 搜索
搜索
美国大学生已经提前开始为AI打工了
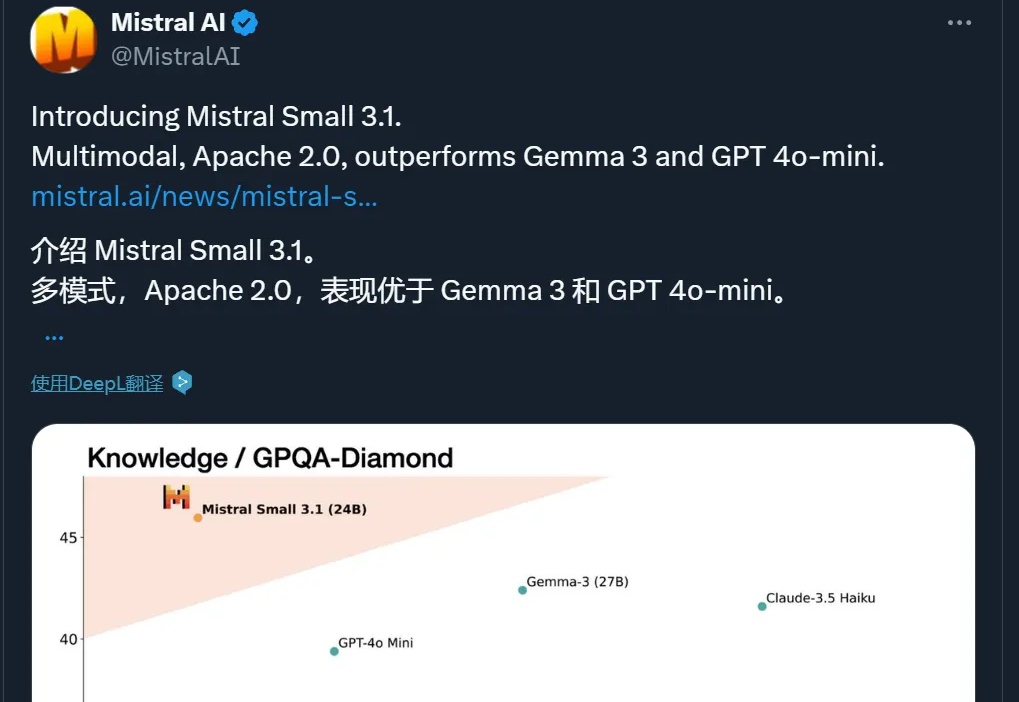
多模态,性能超 GPT-4o Mini、Gemma 3,还能在单个 RTX 4090 上运行,这个小模型值得一试。
Salesforce 的CEO马克·贝尼奥夫上个月宣布 2025 年为“Agentforce 的绝对之年”,这是这家软件公司去年秋天推出的一款产品,旨在帮助客户实现客户服务和其他业务功能的自动化。
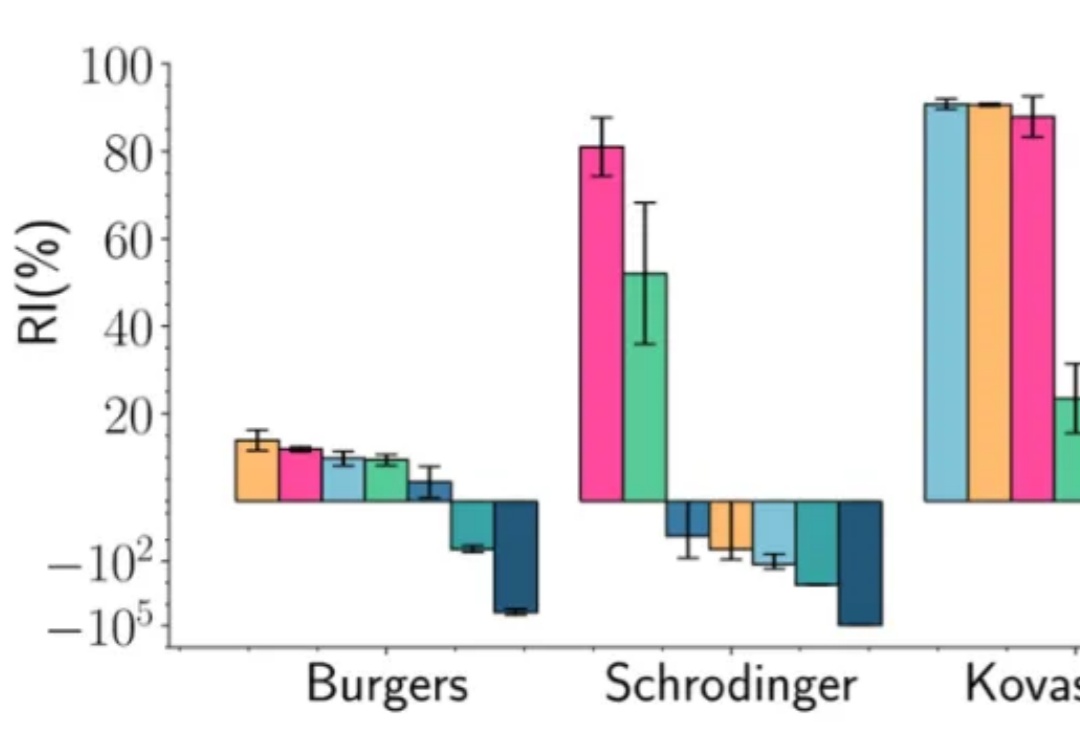
在深度学习的多个应用场景中,联合优化多个损失项是一个普遍的问题。典型的例子包括物理信息神经网络(Physics-Informed Neural Networks, PINNs)、多任务学习(Multi-Task Learning, MTL)和连续学习(Continual Learning, CL)。然而,不同损失项的梯度方向往往相互冲突,导致优化过程陷入局部最优甚至训练失败。

AI诞生于硅谷、起势于水泥丛林。人们对情感的需求暴增,自然地,让AI+情感陪伴赛道火出天际,成为2024年下半年,创投行业为数不多的创新亮点。在数科星球DigitalPlanet所接触的众多企业中,他们纷纷将触角瞄向了“断舍离”的白领阶层,更有一部分人认为,出海是大势所趋。所以,众多AI出海的消息屡屡见诸报端。

谷歌团队发现了全新Scaling Law!新方法DiLoCo被证明更好、更快、更强,可在多个数据中心训练越来越大的LLM。
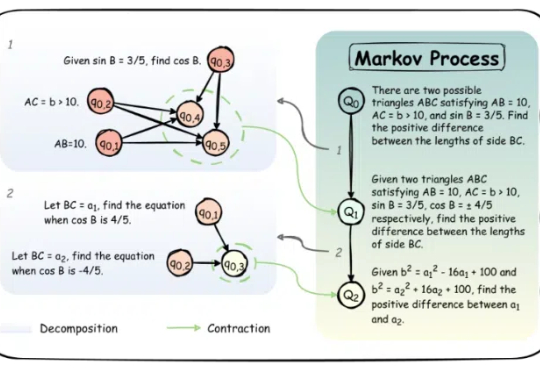
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。

谷歌Gemini全新升级!深度研究全球免费体验,还将支持45余种语言。谷歌旗下App与Gemini互联,正在2.0 Flash Thinking Experimental中上线。利用Gems更是可以量身定制「AI专家」:家教、健身教练、编程搭档都不在话下!
现在是 2025 年,新论文要以博客形式出现。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。