为了想清楚 Agent 时代怎么发社交平台,我做了 ArcSocial
为了想清楚 Agent 时代怎么发社交平台,我做了 ArcSocial为了想清楚 Agent 时代怎么发社交平台,我做了 ArcSocial 。ArcSocial 不是为了让 AI 替我写文章,而是为了把人的判断、Agent 的协作和平台发布流程组织成可追溯、可维护的工作区。
来自主题: AI资讯
9545 点击 2026-06-28 11:44
 搜索
搜索
为了想清楚 Agent 时代怎么发社交平台,我做了 ArcSocial 。ArcSocial 不是为了让 AI 替我写文章,而是为了把人的判断、Agent 的协作和平台发布流程组织成可追溯、可维护的工作区。
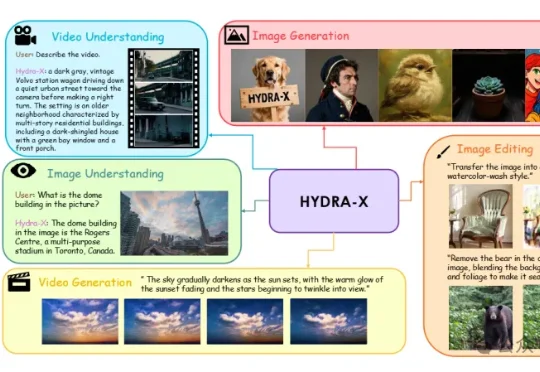
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。

Kimi、智谱和 MiniMax 幕后的 “财务管家”Airwallex 空中云汇,正尝试回答 “AI 时代钱如何在全球丝滑流动” 这一难题。近期,Airwallex 完成 3.2 亿美元 H 轮融资,成为估值 110 亿美元超级独角兽。本轮融资由 Addition 领投,Baillie Gifford、 Amex Ventures 等几家欧美资本跟投

看《堡垒之夜》的游戏录像,也能训练AI?没错,一家靠着海量游戏录像训练AI的公司General Intuition,刚刚完成3.2亿美元(约合人民币21.77亿元)融资。General Intuition公开披露的融资总额已达4.54亿美元,估值23亿美元。

Qualcomm 正在与 Modular 进行高级别谈判,拟收购该人工智能基础设施软件公司,交易估值约为 40 亿美元,据熟悉此事的人士称。这些人士表示,一笔交易可能会在未来几周内宣布,但他们要求不透露姓名,因为相关信息属于私人性质。

如果我们谈到 AI 赋能带来的科学突破,AlphaFold 一定是不可忽略的一项。它解决了困扰生物学界半个多世纪的蛋白质折叠难题,大量压缩了得到蛋白质结构的时间,从原来的一年,到现在的几分钟。它的核心开发者之一 John Jumper 也因这一贡献在 2024 年摘得诺贝尔化学奖。

当全球具身智能行业还在争论技术路线时,一家中国公司已经率先定义并跑通了自己的答案。深度机智提出的「人类学习」路线——以人类数据为起点、动作建模为中心、机器人为 AI 而生——正在被英伟达、Physical Intelligence 等海外头部机构沿同一方向跟进。
刚刚,翁荔(Lilian Weng)的博客 Lil'Log 终于更新了!要知道,自从她联合创立了 Thinking Machines Lab 之后,她那让许多人受益良多的博客就鲜少更新了——距离她上一次更新,已经过去了 13 个月。

6 月 25 日,一条消息在硅谷引起震动——美国政府要求 OpenAI 分阶段发布它的最新模型 GPT-5.6。不是建议,不是「我们希望你考虑一下」,而是白宫网络安全总监办公室,和科技政策办公室联合提出的正式要求。Sam Altman 在当天的员工 Q&A 上告知团队,GPT-5.6 将先以有限预览形式发布给一小批合作伙伴,政府会「逐客户审批」谁能用。

近期Radical AI 的 CEO Joseph Krause接受了一次深度访谈,在访谈中,他揭开了现在资本热炒的 “AI for Science” 的虚假外衣。如果你以为搞材料研发只要像生物制药一样,用大模型在云端“跑个分”就能大力出奇迹,那这期节目会给你狠狠上一课,你会发现,真正的材料学 AI 护城河,离我们简单的想象差了十万八千里。