连不上Gemini CLI,试下DeepSeek-R1接入Claude code
连不上Gemini CLI,试下DeepSeek-R1接入Claude code这两天Google推出了Gemini-CLI这个编程工具,功能和Claude Code基本一致,结果根本排不上队,登录一下很快闪退,和下图一样,使用感受令人不愉悦。很多人都在等着体验这个新工具,但现实是您可能要等很久才能轮到。
来自主题: AI技术研报
10669 点击 2025-06-27 11:00
 搜索
搜索
这两天Google推出了Gemini-CLI这个编程工具,功能和Claude Code基本一致,结果根本排不上队,登录一下很快闪退,和下图一样,使用感受令人不愉悦。很多人都在等着体验这个新工具,但现实是您可能要等很久才能轮到。

开源且免费!谷歌对编程Agent出手了。
就在刚刚,谷歌深夜悄无声息地扔下了一颗重磅炸弹,正式推出了一个全新的开源AI编程工具:Gemini CLI
刚刚谷歌推出了 Gemini CLI,一个开源的 AI Agent,把 Gemini 的能力直接带到你的终端里。可以把它看作是谷歌版的 Claude Code。最香的是,这玩意儿开源、免费用,背后是带百万上下文的最强 Gemini 模型。
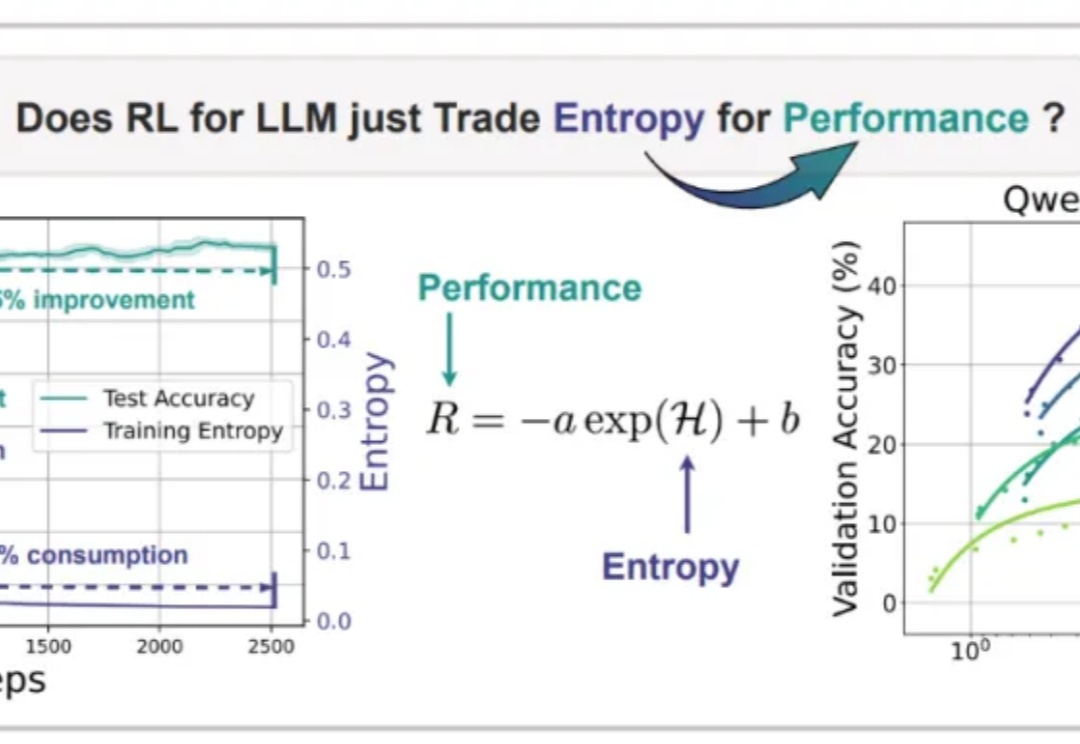
Nature never undertakes any change unless her interests are served by an increase in entropy. 自然界的任何变化,唯有在熵增符合其利益时方会发生——Max Planck
刚刚,OpenAI 正式对外推出了 AI 编码神器 Codex,其目前向 ChatGPT Plus 用户开放。据悉,Codex 在限定时段内提供宽松的使用额度,但在需求高峰期间,可能会对 Plus 用户设置速率限制,以确保其能广泛可用。

如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。

在复杂、未知的现实环境中,传统导航方法往往依赖闭集语义或事先构建的地图,难以实现真正的“按需探索”。为打破这一瓶颈,本文提出了 FindAnything ——一套融合视觉语言模型的对象为中心、开放词汇三维建图与探索系统。
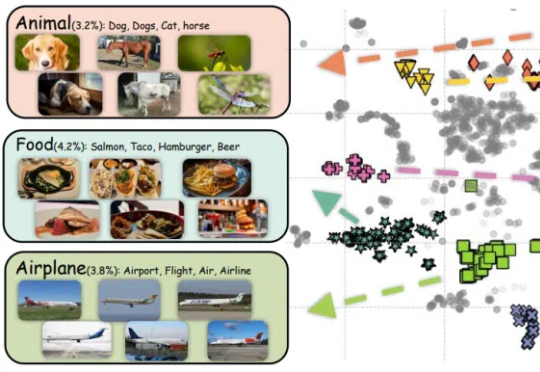
新的亿级大规模图文对数据集来了,CLIP达成新SOTA!

不止GPT-4o可以制作吉卜力风格图像!更多工具都可以制作吉卜力风图像。甚至2分钟之内,还能用照片生成吉卜力风格动画:蒙娜丽莎给你说Hello。