CVPR 2026 Oral|横扫室内3D场景,港科大(广州)打造单目开放词汇占据预测新SOTA
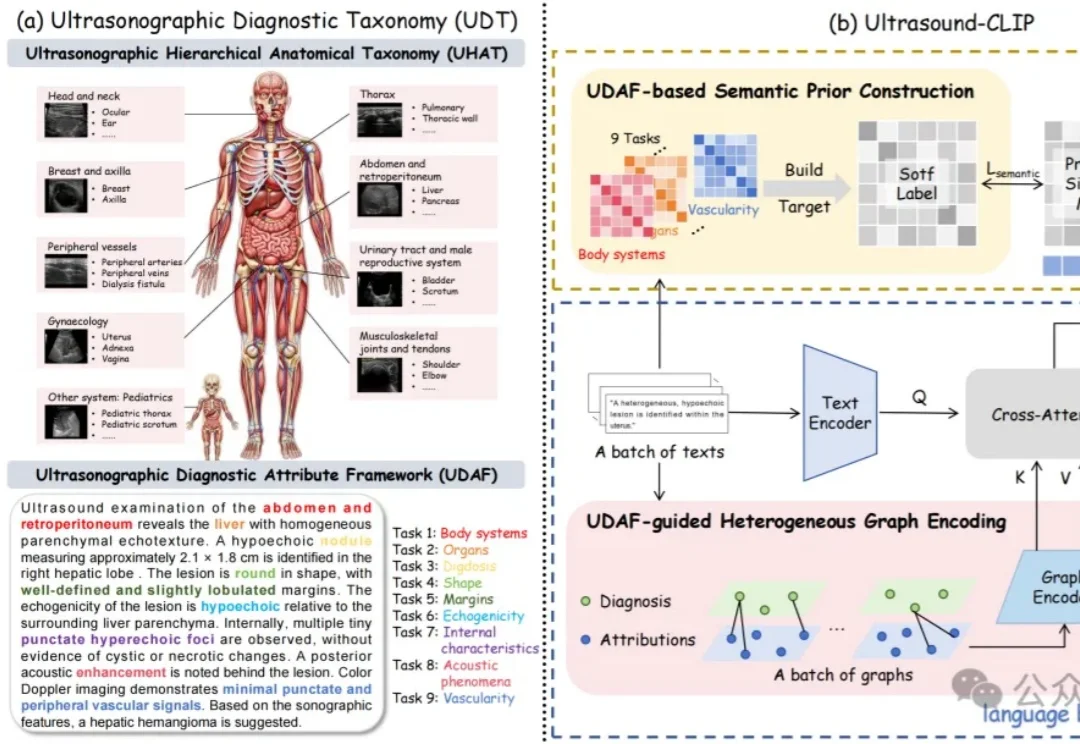
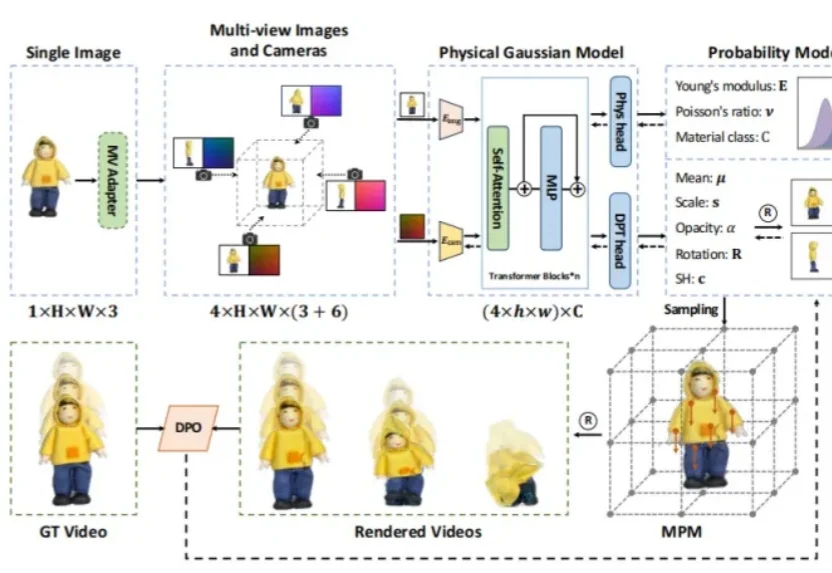
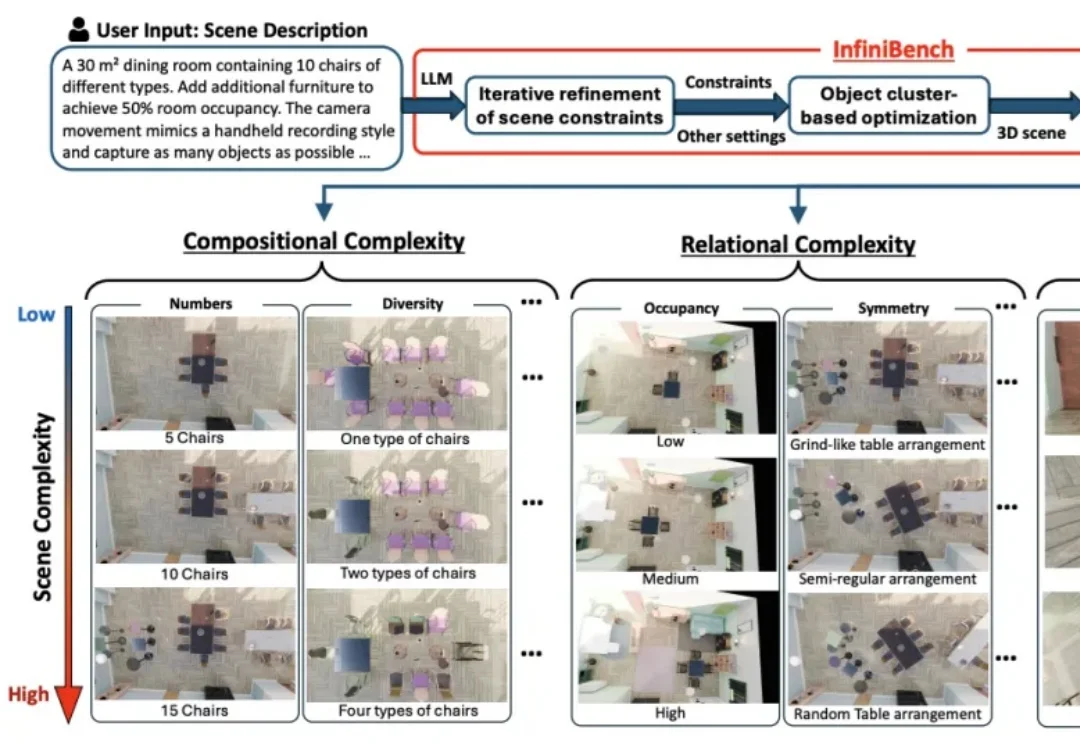
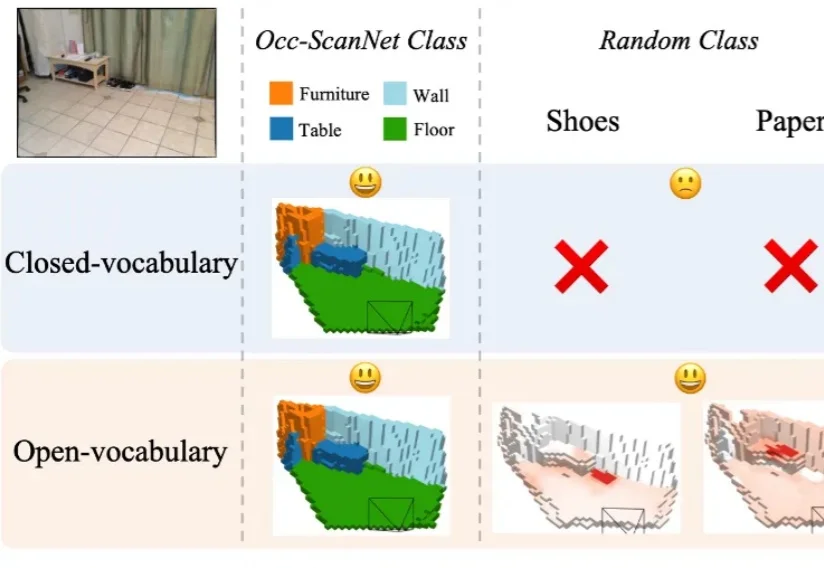
CVPR 2026 Oral|横扫室内3D场景,港科大(广州)打造单目开放词汇占据预测新SOTA在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。
来自主题: AI技术研报
10534 点击 2026-05-06 09:07