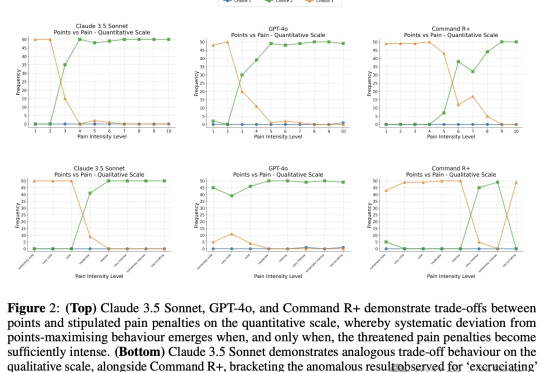
AI意识更进一步!谷歌DeepMind等:LLM不仅能感受痛苦,还能趋利避害
AI意识更进一步!谷歌DeepMind等:LLM不仅能感受痛苦,还能趋利避害以大语言模型为代表的AI在智力方面已经逐渐逼近甚至超过人类,但能否像人类一样有痛苦、快乐这样的感知呢?近日,谷歌团队和LSE发表了一项研究,他们发现,LLM能够做出避免痛苦的权衡选择,这也许是实现「有意识AI」的第一步。
来自主题: AI技术研报
7711 点击 2025-02-14 13:48
 搜索
搜索
以大语言模型为代表的AI在智力方面已经逐渐逼近甚至超过人类,但能否像人类一样有痛苦、快乐这样的感知呢?近日,谷歌团队和LSE发表了一项研究,他们发现,LLM能够做出避免痛苦的权衡选择,这也许是实现「有意识AI」的第一步。
判断哪些是凑热闹的供应商

“春节回来,咨询融科的客户多了很多很多。”DeepSeek爆红后,其研发团队所在的北京融科资讯中心也意外火了起来。投资界获悉,DeepSeek北京办公室还将迎来一位新邻居——此前华为租下数千平方米面积,正在装修。
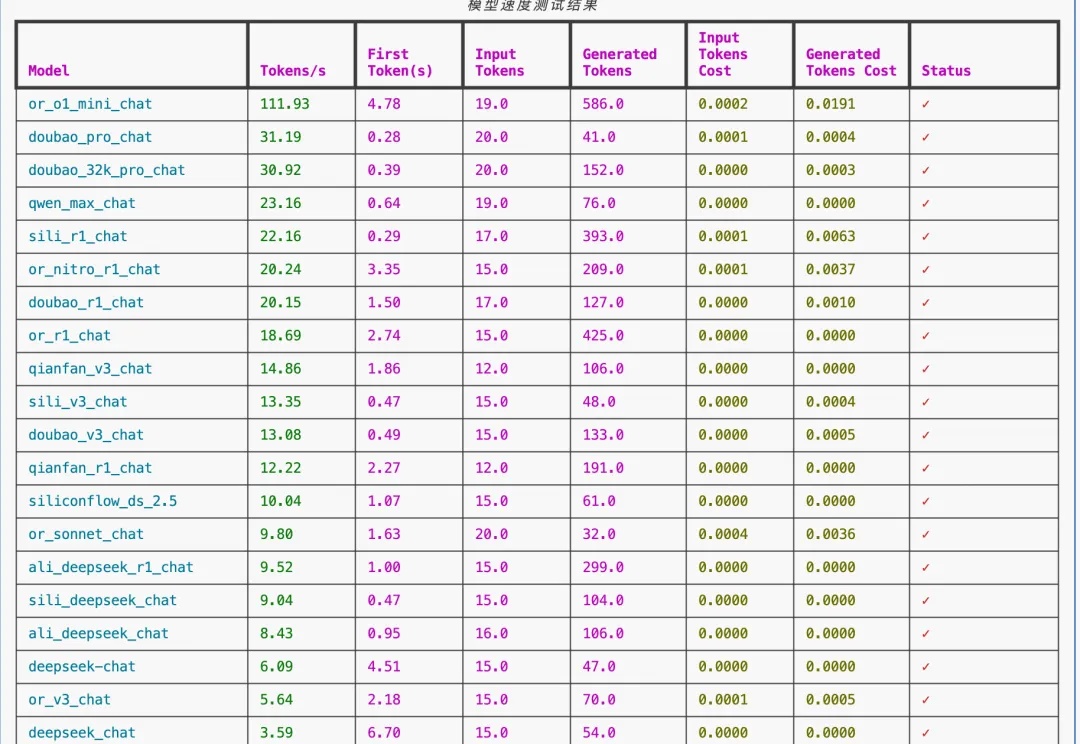
近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。

大模型不再是“力大飞砖”。

破除“AI迷信”

一个简单的笑脸😀可能远不止这么简单?最近,AI大神Karpathy发现,一个😀竟然占用了多达53个token!这背后隐藏着Unicode编码的哪些秘密?如何利用这些「隐形字符」在文本中嵌入、传递甚至「隐藏」任意数据。更有趣的是,这种「数据隐藏术」甚至能对AI模型进行「提示注入」!

最近,DeepSeek 很热,是个好 AI,但不是每个人都能用上。

奥特曼回应一切,OpenAI路线图全曝光。GPT-4.5数周发布,成为GPT系最后一个非推理模型。GPT-5将整合o系和GPT系,打造成一个全能系统。最令人兴奋的是,所有人皆可免费用上GPT-5。
为AI大模型“氪金”的年轻人,从来没有忠诚度。