
独家 | 字节火山引擎提升MaaS营收目标至全年150亿元,Seedance 2.0单月营收已超10亿元
独家 | 字节火山引擎提升MaaS营收目标至全年150亿元,Seedance 2.0单月营收已超10亿元如果模型能力断层领先,那么买单的人自然会出现。
来自主题: AI资讯
9704 点击 2026-06-03 15:26
 搜索
搜索
如果模型能力断层领先,那么买单的人自然会出现。

独家获悉,字节跳动多模态负责人周畅管理范围再次扩大,原由李航负责的 Seed Robotics 团队已向周畅汇报月余,李航现以顾问身份负责学术合作方向。字节也正在招聘具身智能技术负责人,负责机器人业务整体规划,职级定位为 L8,对标阿里 P10-P11,将向周畅汇报。该岗位候选人主要来自头部具身智能创业公司技术负责人。
刚刚,顾全全发文告别字节 Seed 团队。在此之前,他是 Seed 旗下聚焦科学智能领域的 AI4S 团队核心成员。顾全全是机器学习理论、大模型对齐以及 AI4S 科学智能领域知名的学者。他于 2007 年和 2010 年分获清华大学自动化专业学士、控制科学与工程硕士学位,2014 年获伊利诺伊大学香槟分校计算机科学博士学位,随后在普林斯顿大学运筹与金融工程系(ORFE)开展统计学博士后研究。

VAST近期完成合计近2亿美元的A+及A++轮融资,领投方为渶策资本、国寿长三角科创基金。拿到这笔钱的同时,VAST也带来了他们最新的世界模型进展:Project Eden。区别于业内「动作条件视频生成」与「静态3D场景生成」等常规路径,Project Eden创造性地将底层状态推演与视觉呈现进行了原生解耦。

对于 Seedance 视频生成模型,大家都不陌生了。
核心观点:由前Apple Vision Pro两位技术负责人联合创办的Reactor,近期完成5900万美元种子轮及A轮融资,由Lightspeed Venture Partners领投,WndrCo
近日,字节旗下AI视频创作工具小云雀的短剧Agent正式更新到2.0版本。自Seedance 2.0这一视频生成模型横空出世以来,小云雀一直是其原生支持的平台。由于整体使用门槛相对较低,小云雀也逐渐积累起一批AI短剧和AI短片创作者。
编辑|Panda 数学正在迎来 AI 革命。 最近几个月尤为明显。比如,就在前几天,Google DeepMind 新论文宣布其最新系统 AlphaProof Nexus 在一次自主运行中,解决了 3

7×24,AI也吃不消。
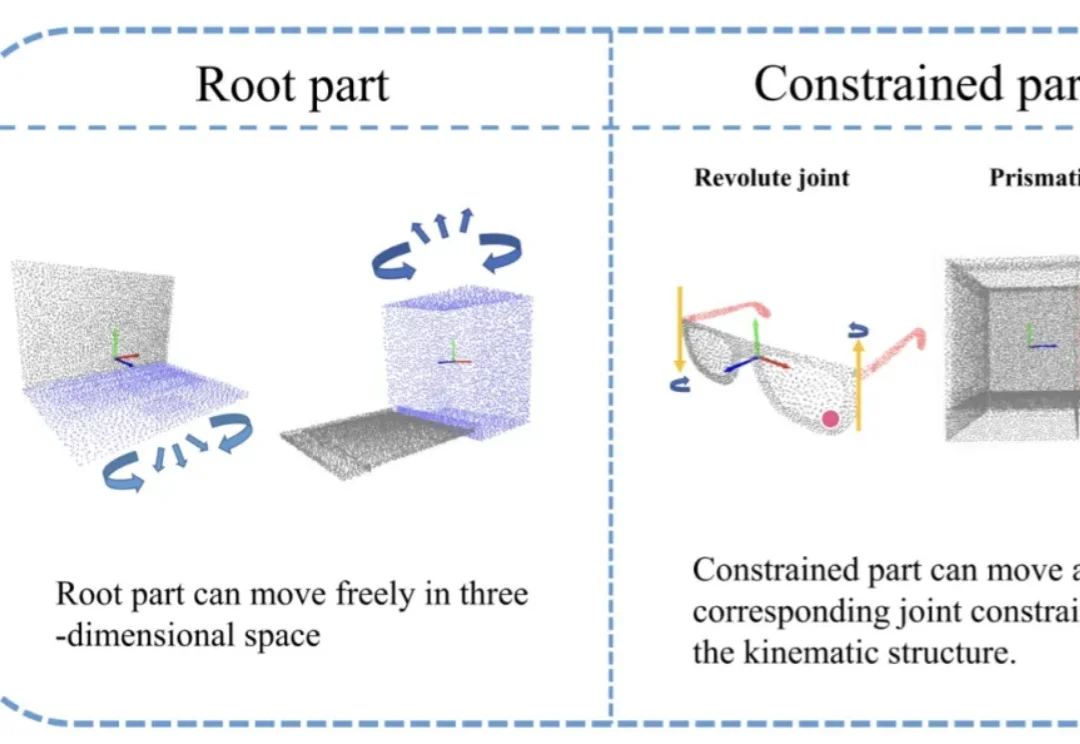
在具身智能快速发展的今天,机器人已经不再满足于「看见」刚体物体,而是开始真正走向复杂环境中的交互与操作。从机械臂开柜门,到服务机器人整理抽屉,再到工业场景中的工具操作,大量真实世界目标都属于关节物体(Articulated Objects)。