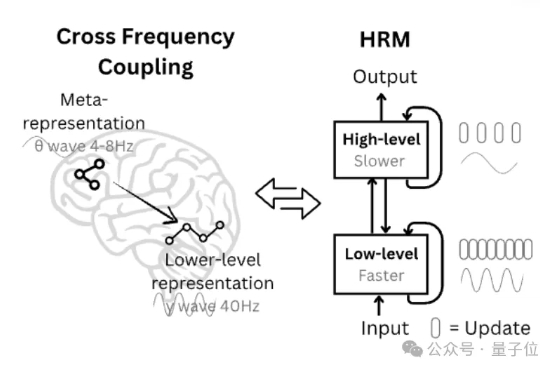
又是王冠:27M小模型超越o3-mini!拒绝马斯克的00后果然不同
又是王冠:27M小模型超越o3-mini!拒绝马斯克的00后果然不同27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
来自主题: AI技术研报
8637 点击 2025-08-10 15:00
 搜索
搜索
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
果然只要坚持每天测Agent, 总能开出金的。Agent们好用但不便宜,有没有那种不烧积分,一句话就能定制多个智能体的Agent开发平台呢?今天就有了!
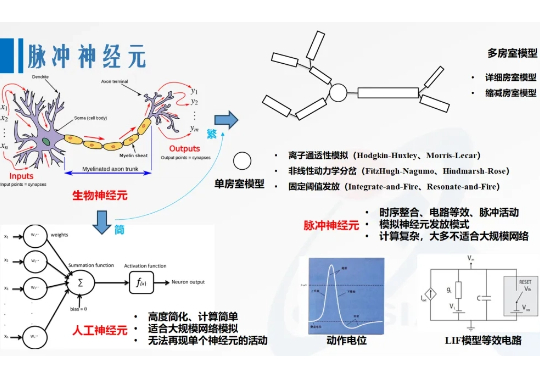
1997年,Wolfgang Maass于Networks of spiking neurons: The third generation of neural network models一文中提出,由脉冲神经元构成的网络——脉冲神经网络(SNN),能够展现出更强大的计算特性,会成为继人工神经网络后的“第三代神经网络模型”[6]。

引言:越过AGI喧嚣,生产力正呼唤“成果交付型”AI

2025年7月21日,斯坦福大学学习加速器(Stanford Accelerator for Learning)发布名为《AI+学习差异:设计无边界的未来》(AI+ Learning Differences: Designing a Future with No Boundaries)白皮书,强调AI可以成为支持有学习差异的学生的有力工具,但前提是其开发要以他们的需求和意见为核心。

在正式走近ChatGPT Agent之前,让我们介绍一下这次谈话的几位主角,他们分别是OpenAI团队核心成员Isa Fulford、Casey Chu和孙之清。我们团队分别开发了Operator和Deep Research,在分析用户请求时发现,Deep Research的用户非常希望模型能够访问需要付费订阅的内容或有门槛的资源,而Operator恰好具备这种能力。
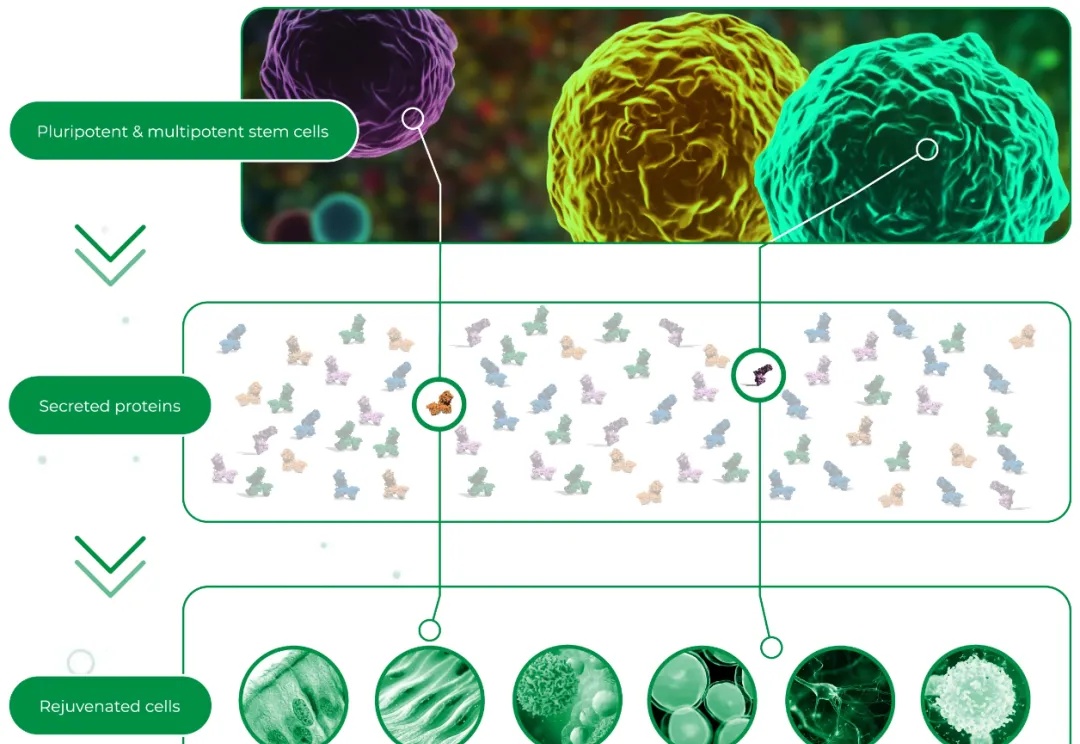
2025年6月11日,礼来和Juvena Therapeutics达成了一项超6.5亿美元的合作协议。根据协议,礼来获得针对多个靶点的主要候选药物的独家许可,并将在Juvena达到特定里程碑后,决定是否推进某个项目,一旦礼来决定推进,其团队将负责所有后续的研发和商业化。
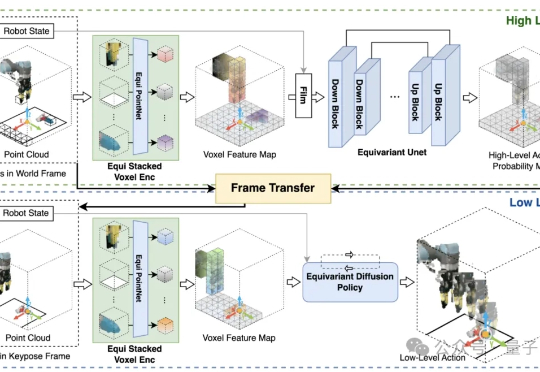
如何让AI像人一样,仅凭少量演示,就能稳健适应复杂多变的真实场景? 美国东北大学和波士顿动力RAI提出了HEP(Hierarchical Equivariant Policy via Frame Transfer)框架,首创“坐标系转移接口”,让机器人学习更高效、泛化更灵活。

就在刚刚,OpenAI最新发布来了,ChatGPT Agent正式对外亮相。这是一个把“想”和“干”统一了的智能体,之前深度研究的思考和分析能力,Operator的操作执行能力,在ChatGPT Agent实现了统一。

每当我们讨论AI对就业的影响时,大多数都是专家拍脑袋的预测。但微软研究院的这篇论文不一样,他们分析了20万个真实的Microsoft bing Copilot用户对话,每一个数据点背后都是一个真实的人,一个真实的工作场景,首次用硬数据告诉我们:AI到底在改变什么工作?哪些工作活动和职业正在被生成式AI(Generative AI)最大程度地影响?