
GPT-4现场被端侧小模型“暴打”,商汤日日新5.0:全面对标GPT-4 Turbo
GPT-4现场被端侧小模型“暴打”,商汤日日新5.0:全面对标GPT-4 Turbo是的,就是在一场《街头霸王》游戏现场PK中,发生了这样的名场面。
来自主题: AI技术研报
8393 点击 2024-04-26 11:02
 搜索
搜索
是的,就是在一场《街头霸王》游戏现场PK中,发生了这样的名场面。
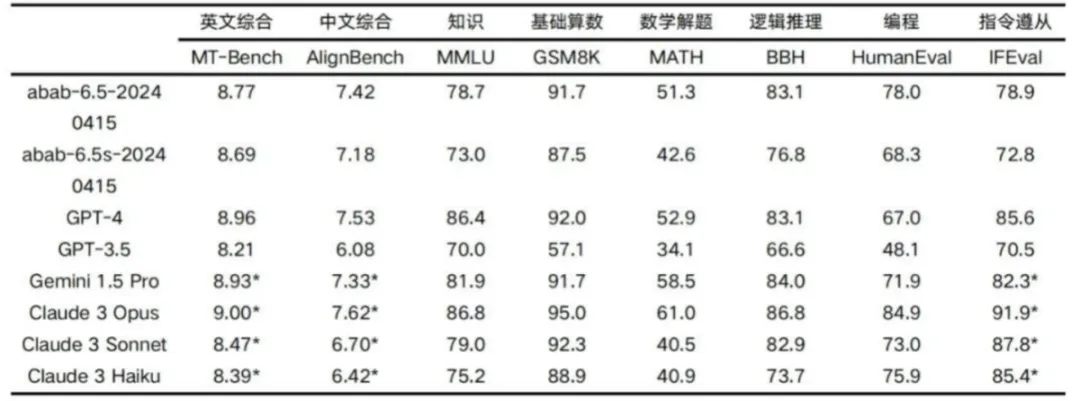
继 1 月推出国内首个基于 MoE 架构的千亿参数量大语言模型 abab6 后,上周,通用人工智能创业公司、中国估值最高的大模型公司之一 MiniMax 推出了万亿 MoE 模型 abab 6.5。根据 MiniMax 发布的技术报告,在各类核心能力测试中,abab 6.5接近 GPT-4、 Claude 3 Opus 、Gemini 1.5 Pro 等世界领先的大语言模型。
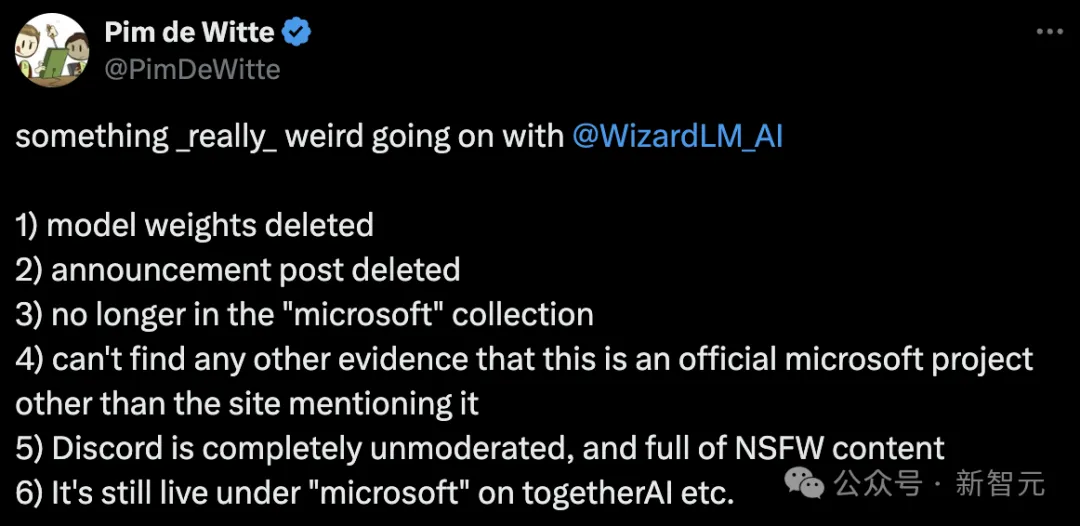
上周,微软空降了一个堪称GPT-4级别的开源模型WizardLM-2。 却没想到发布几小时之后,立马被删除了。
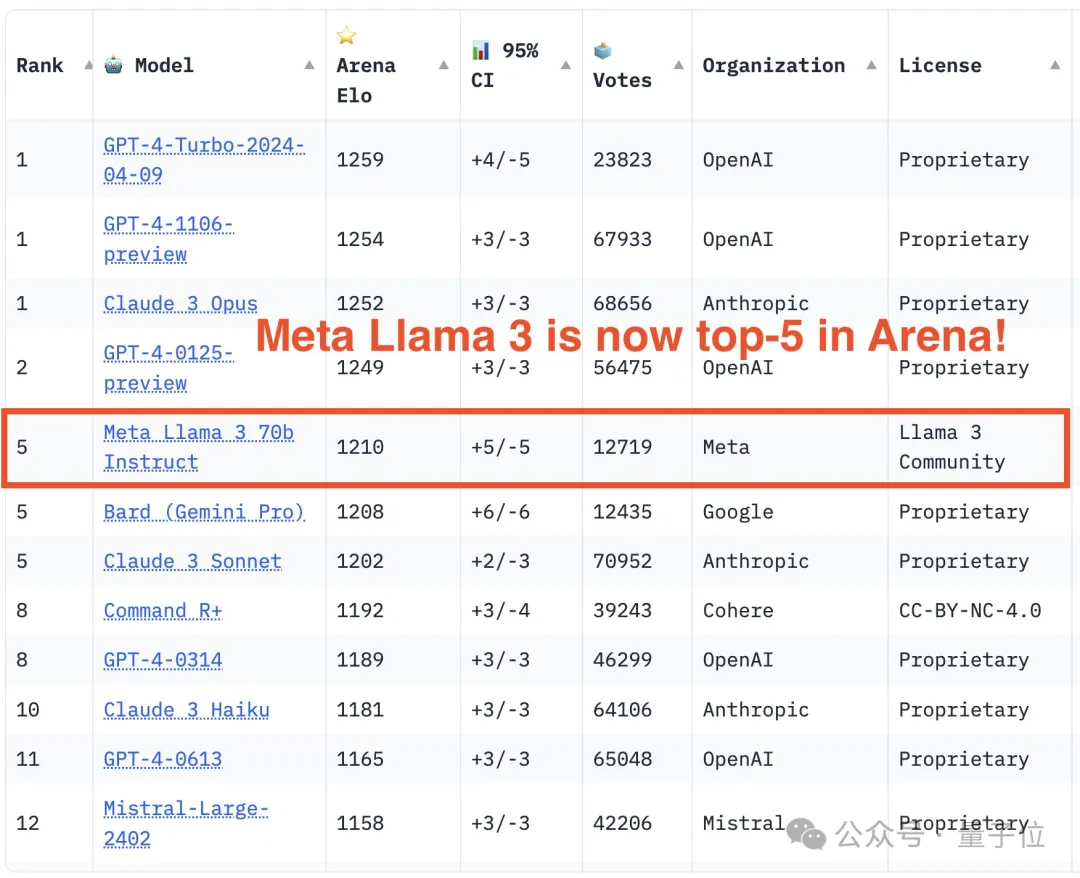
关于Llama 3,又有测试结果新鲜出炉—— 大模型评测社区LMSYS发布了一份大模型排行榜单,Llama 3位列第五,英文单项与GPT-4并列第一。
近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显著的成功。然而,作为许多下游任务的基础模型,当前的 MLLM 由众所周知的 Transformer 网络构成,这种网络具有较低效的二次计算复杂度。

最近几年,AI技术的发展远远超出普通大众和研究者的预期,「通用人工智能(AGI)」的概念也从科幻小说中走进了日常生活的讨论中,成为了许多科技公司和研究机构所追求的最终目标。

大家相互薅羊毛,要用,但要小心用,一不小心就尴尬了。 一位国产大模型算法工程师在接受「甲子光年」采访时的吐槽,可以说是非常到位了。 它准确地阐述 AI 业内一个所有人「心照不宣」的公开秘密。

91行代码、1056个token,GPT-4化身黑客搞破坏!

就在刚刚,Meta官网上新,官宣了Llama 3 80亿和700亿参数版本
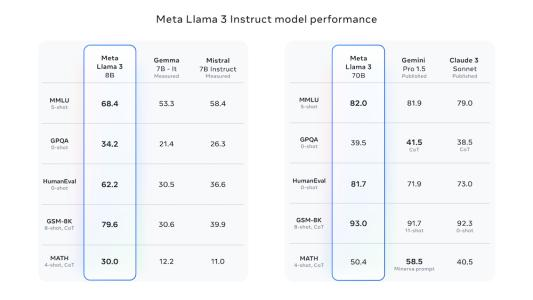
智东西4月19日消息,Meta推出迄今为止能力最强的开源大模型Llama 3系列,发布8B和70B两个版本。 Llama 3在一众榜单中取得开源SOTA(当前最优效果)。Llama 3 8B在MMLU、GPQA、HumanEval、GSM-8K等多项基准上超过谷歌Gemma 7B和Mistral 7B Instruct。