
刚刚,DeepMind最强「基础世界模型」诞生!单图生1分钟游戏世界,解锁下一代智能体
刚刚,DeepMind最强「基础世界模型」诞生!单图生1分钟游戏世界,解锁下一代智能体谷歌DeepMind最新基础世界模型Genie 2登场!只要一张图,就能生成长达1分钟的游戏世界。从此,我们将拥有无限的具身智能体训练数据。更有人惊呼:黑客帝国来了。
来自主题: AI资讯
8268 点击 2024-12-05 10:16
 搜索
搜索
谷歌DeepMind最新基础世界模型Genie 2登场!只要一张图,就能生成长达1分钟的游戏世界。从此,我们将拥有无限的具身智能体训练数据。更有人惊呼:黑客帝国来了。
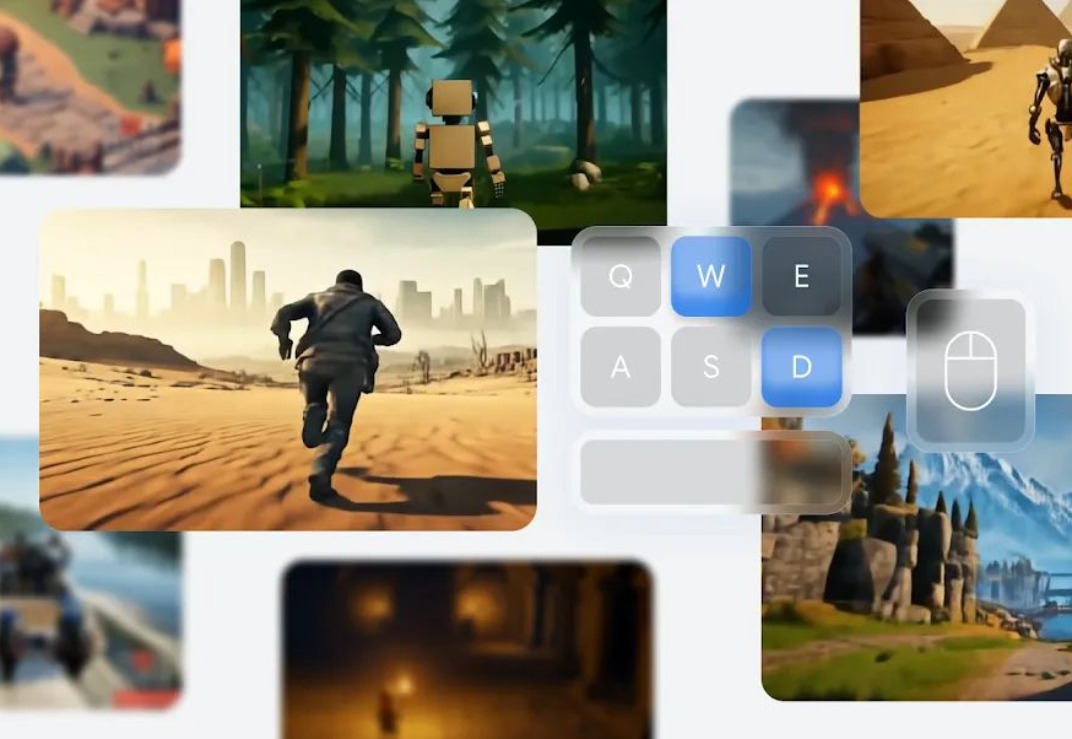
就在刚刚,Google Deepmind 深夜放大招,发布了最新基础世界模型 Genie 2。 想体验游戏世界?未来只需一张图片就能实现。 作为一个基础世界模型,Genie 2 能够凭借开局一张图生成各种可操作、可玩的 3D 环境。

2023 年,阿里妈妈首次提出了 AIGB(AI-Generated Bidding)Bidding 模型训练新范式(参阅:阿里妈妈生成式出价模型(AIGB)详解)。
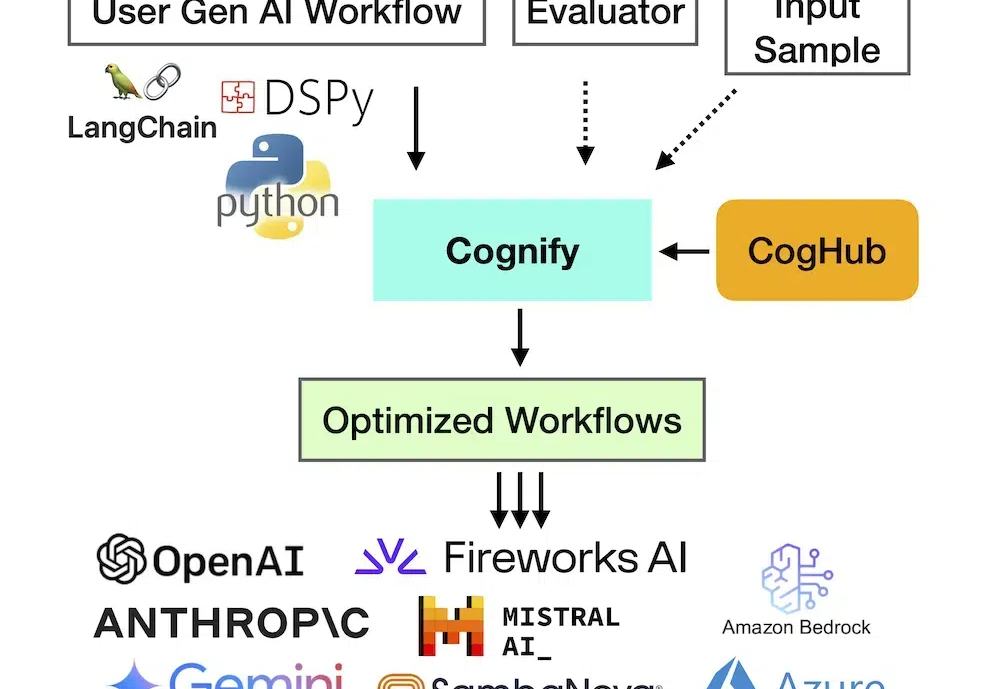
近几年在生成式 AI 技术和商业创新飞速发展的背景下,创建高质量且低成本的生成式 AI 应用在业界仍有相当难度,主要原因在于缺乏系统化的调试和优化方法。

随着AI技术的不断突破,虚拟数字人和AI养成类游戏正成为数字创作领域的新风向标。从HeyGen、商汤SenseAvatar到腾讯智影,用户上传视频即可轻松生成高拟真度的数字人,标志着个性化内容生产进入了技术主导创作的新篇章。

36氪获悉,近日北京悦点科技有限公司(以下简称“悦点科技”)完成数千万元人民币的天使轮融资。本轮融资由云启资本独家投资,融得资金将主要用于公司在企业级GenAI应用平台的进一步研发和商业拓展。
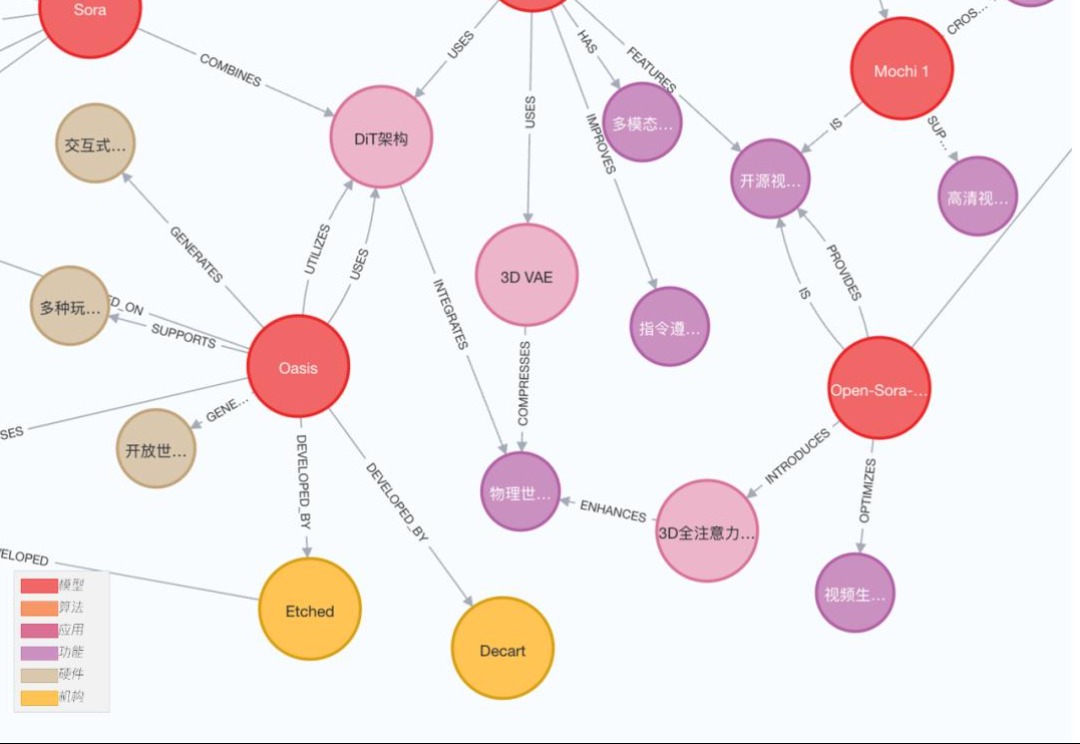
本期 AGI 路线图中关键节点:Sora、DiT、Runway Gen-3、可灵 AI、Oasis、世界模拟器
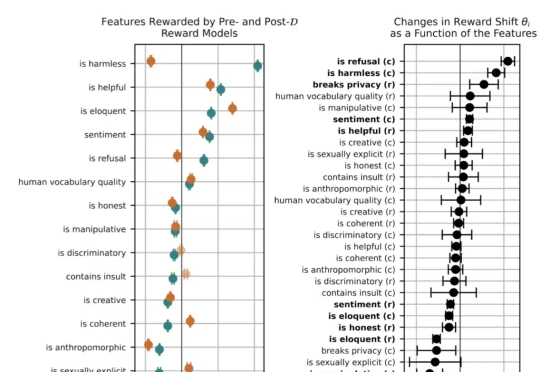
之前领导OpenAI安全团队的北大校友翁荔(Lilian Weng),离职后第一个动作来了。当然是发~博~客。这次的博客一如既往万字干货,妥妥一篇研究综述,翁荔本人直言写起来不容易。主题围绕强化学习中奖励黑客(Reward Hacking)问题展开,即Agent利用奖励函数或环境中的漏洞来获取高奖励,而并未真正学习到预期行为。

上周我们受谷歌邀请,来到了国际象棋世界冠军赛的现场。其中最激动的就是采访世界冠军丁立人老师(中国第一个男子国际象棋世界冠军!采访稿过几天会发布!)以及体验谷歌的 AI 展区!展区包括 AI 象棋解说(Chatting Chess),帮助小白和观众通俗易懂地学习如何下棋;

绘本故事在小红书赛道可以产生变现,相信您肯定了解,无论是做绘本售卖、挂小车、还是起号,都是不二之选.但制作过程是极其繁琐,如果不尝试AI agent coze工作流模式,只能使用很多软件相互协调搭配制作。 这是舰长使用工作流生成后,剪映剪辑后的效果视频