ICML 2026|FusionRoute:从专家路由到自我修正,一种新的多LLM协作范式
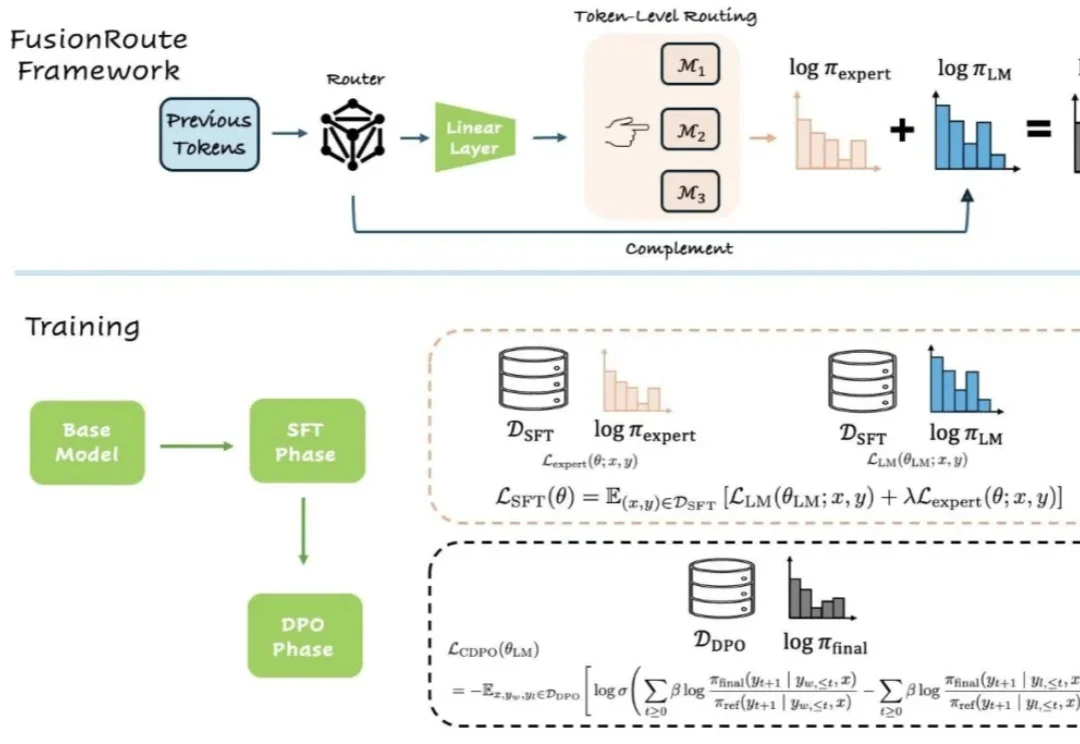
ICML 2026|FusionRoute:从专家路由到自我修正,一种新的多LLM协作范式近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。
来自主题: AI技术研报
10053 点击 2026-06-08 09:47
 搜索
搜索
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。
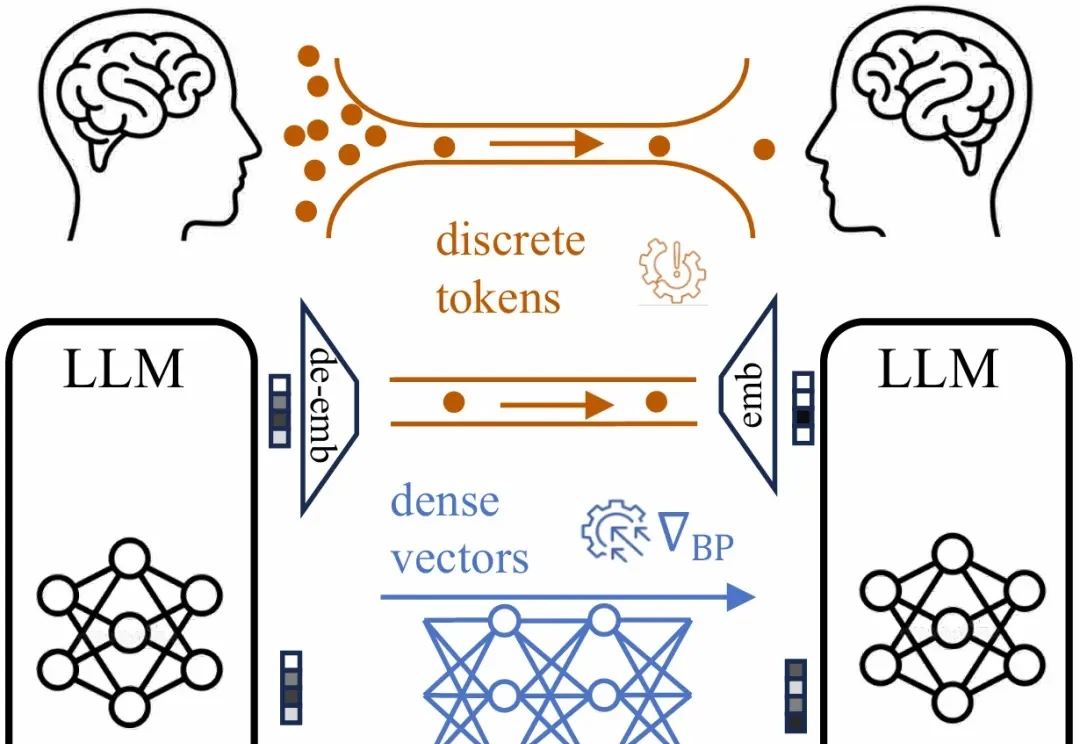
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。
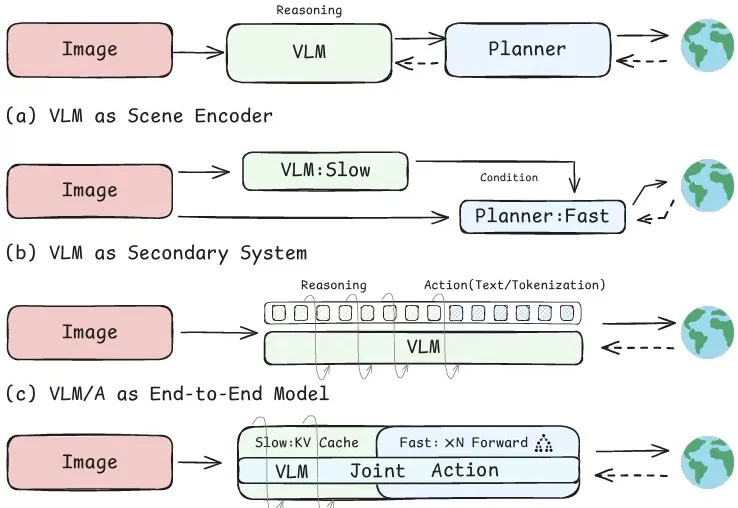
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。

智能体时代,如何让视觉分割更准确?
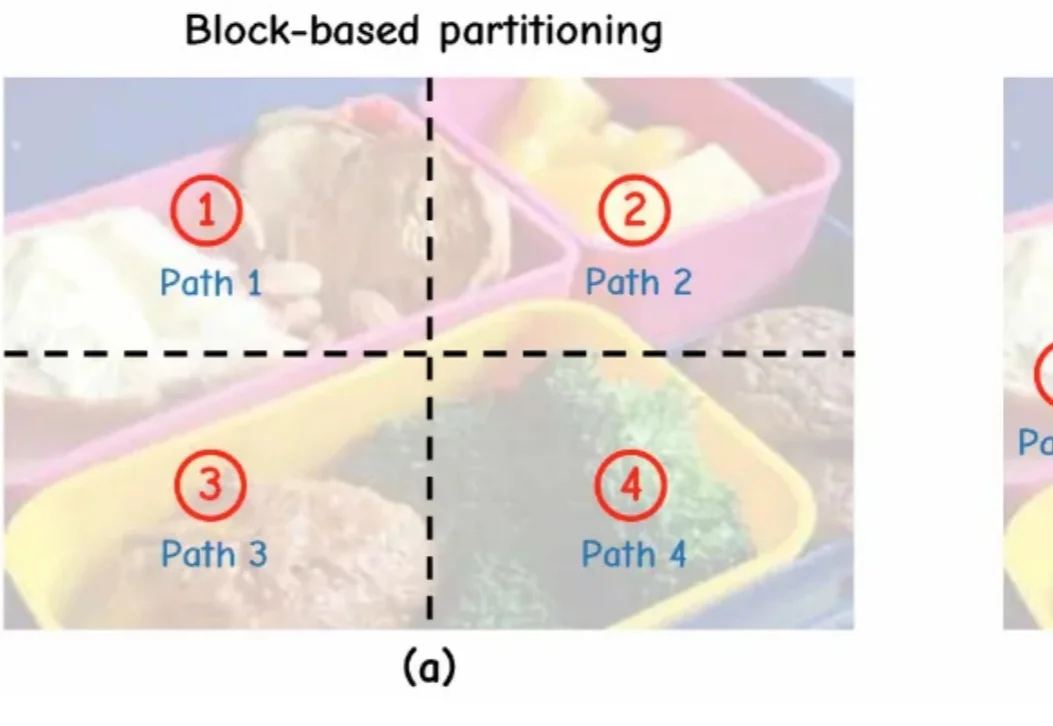
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。
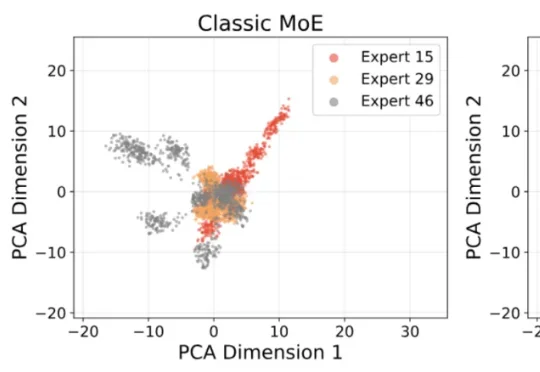
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。
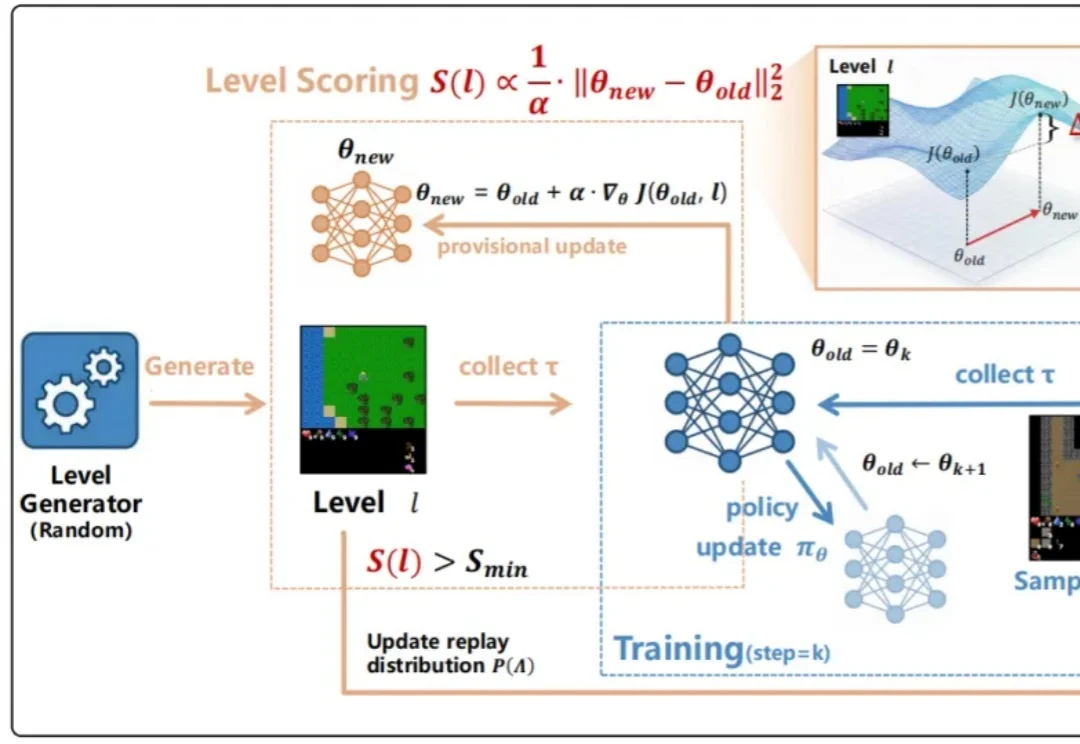
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
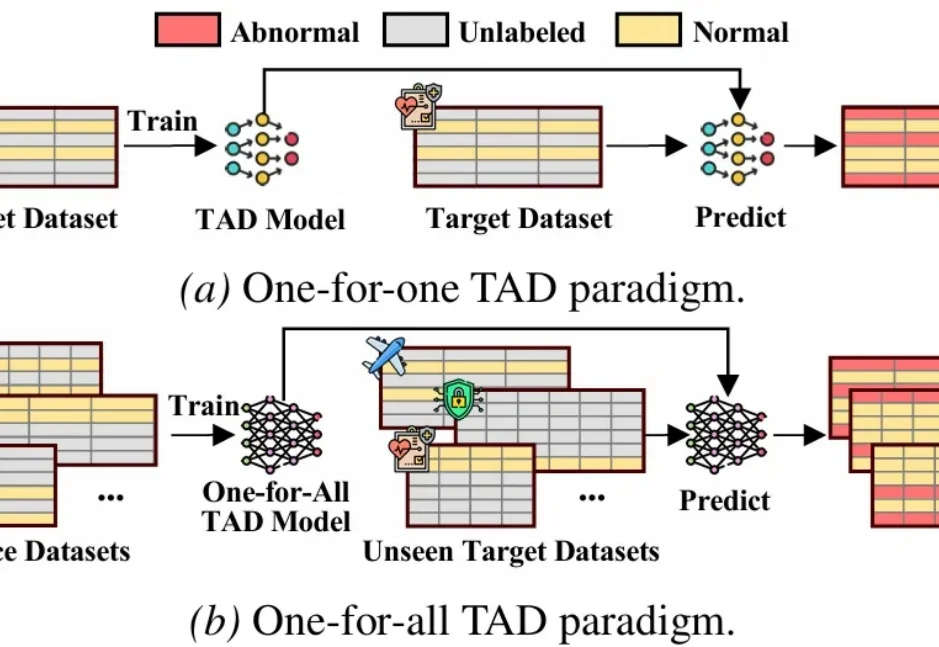
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。