一文搞懂SFT、RLHF、DPO、IFT
一文搞懂SFT、RLHF、DPO、IFTSFT、RLHF 和 DPO 都是先估计 LLMs 本身的偏好,再与人类的偏好进行对齐
来自主题: AI资讯
9055 点击 2024-08-22 17:04
 搜索
搜索
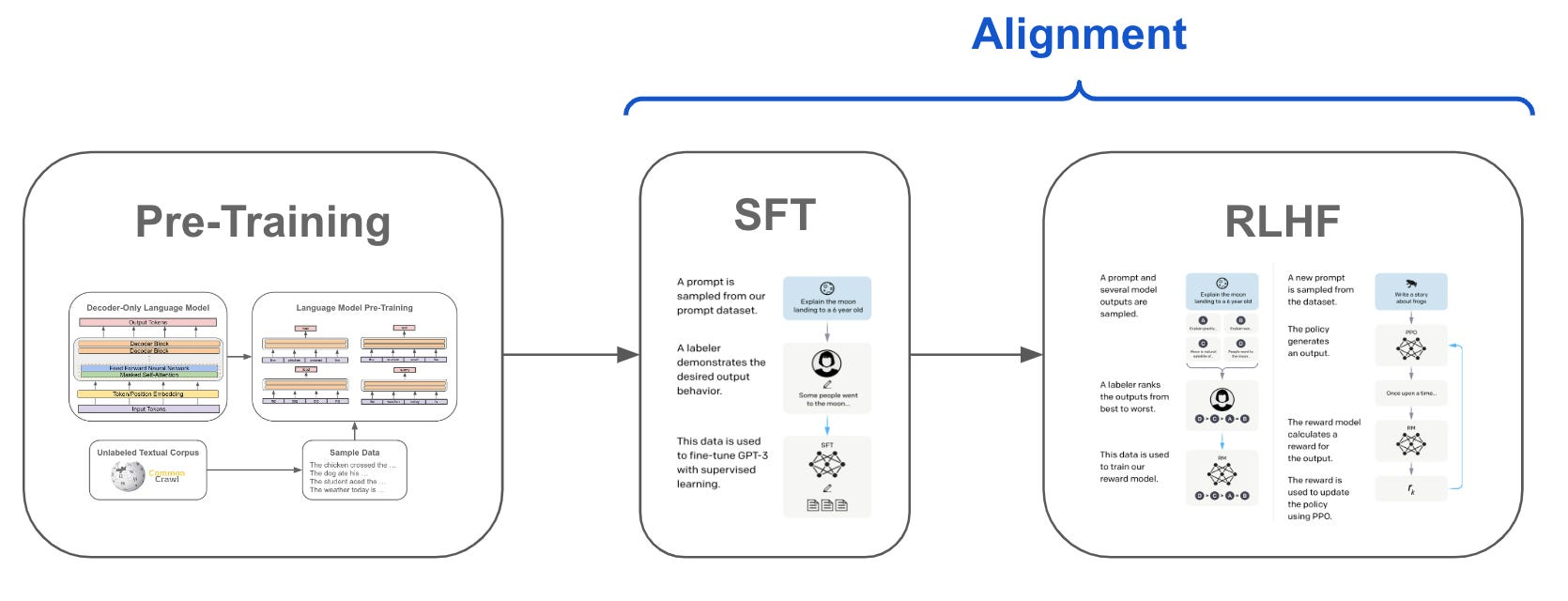
SFT、RLHF 和 DPO 都是先估计 LLMs 本身的偏好,再与人类的偏好进行对齐

虽然大语言模型(LLM)的能力不断突破,但在长文生成方面却一直存在瓶颈。近日,清华大学和智谱AI联合发布的最新研究成果,为解决这一难题提供了创新方案。这项名为"LongWriter"的技术,成功将AI模型的长文生成能力从约2000字提升至10000字以上,同时保持了高质量输出。这一成果通过创新的数据构建方法、模型训练策略和评估基准,为AI长文创作开辟了新天地。

Replika 是一款虚拟陪伴(AI 伴侣)应用,成立于 2017 年,在 LLM 技术爆发之前。

合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。
检索增强生成(Retrieval-Augmented Generation, RAG)技术正在彻底革新 AI 应用领域,通过将外部知识库和 LLM 内部知识的无缝整合,大幅提升了 AI 系统的准确性和可靠性。然而,随着 RAG 系统在各行各业的广泛部署,其评估和优化面临着重大挑战
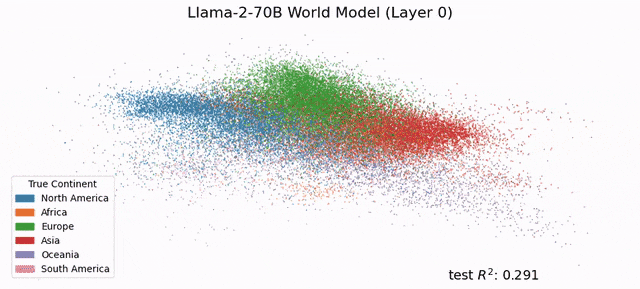
MIT CSAIL的研究人员发现,LLM的「内心深处」已经发展出了对现实的模拟,模型对语言和世界的理解,绝不仅仅是简单的「鹦鹉学舌」。也就说,在未来,LLM会比今天更深层地理解语言。

输出格式不同,竟然还能影响大模型发挥?!

现存的LLM是否真的有用?在工作中真实使用LLM的场景都有哪些?谷歌DeepMind科学家详细分享了他是如何「玩转」AI,帮助自己提质增效的。

最近的论文表明,LLM等生成模型可以通过搜索来扩展,并实现非常显著的性能提升。另一个复现实验也发现,让参数量仅8B的Llama 3.1模型搜索100次,即可在Python代码生成任务上达到GPT-4o同等水平。

预计在 2025 年能看到企业端 GenAI 的大规模放量