
清华北航博士生「强迫」Gemma-2说中文!弱智吧、角色扮演、数学问题表现惊喜
清华北航博士生「强迫」Gemma-2说中文!弱智吧、角色扮演、数学问题表现惊喜谷歌的Gemma 2刚刚发布,清华和北航的两名博士生就已经成功推出了指令微调版本,显著增强了Gemma 2 9B/27B模型的中文通用对话、角色扮演、数学、工具使用等能力。
来自主题: AI资讯
11084 点击 2024-07-06 18:50
 搜索
搜索
谷歌的Gemma 2刚刚发布,清华和北航的两名博士生就已经成功推出了指令微调版本,显著增强了Gemma 2 9B/27B模型的中文通用对话、角色扮演、数学、工具使用等能力。

近日,来自谷歌DeepMind的研究人员,推出了专门用于评估大语言模型时间推理能力的基准测试——Test of Time(ToT),从两个独立的维度分别考察了LLM的时间理解和算术能力。

大语言模型有道德推理能力吗?不仅有,甚至可能在道德推理方面超越普通人和专家学者!最新研究发现:GPT-4o针对道德难题给出的建议比人类专家更让人信服。

只有10亿参数的xLAM-1B在特定任务中击败了LLM霸主:OpenAI的GPT-3.5 Turbo和Anthropic的Claude-3 Haiku。上个月刚发布的苹果智能模型只有30亿参数,就连奥特曼都表示,我们正处于大模型时代的末期。那么,小语言模型(SLM)会是AI的未来吗?

开源大语言模型(LLM)百花齐放,为了让它们适应各种下游任务,微调(fine-tuning)是最广泛采用的基本方法。基于自动微分技术(auto-differentiation)的一阶优化器(SGD、Adam 等)虽然在模型微调中占据主流,然而在模型越来越大的今天,却带来越来越大的显存压力。

只要仍使用英语训练 LLM 模型,美国就还有优势。
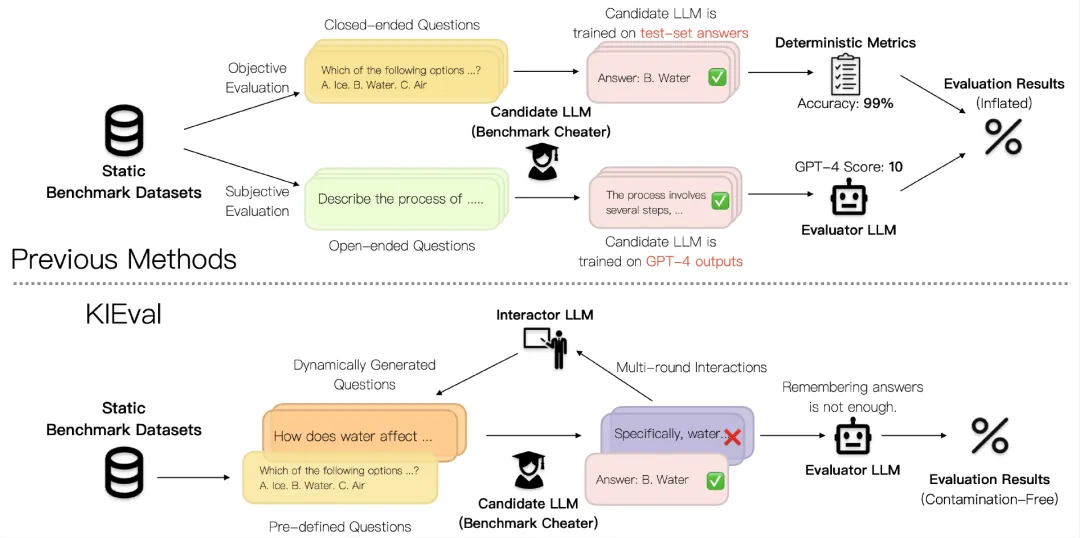
当前大语言模型(LLM)的评估方法受到数据污染问题的影响,导致评估结果被高估,无法准确反映模型的真实能力。北京大学等提出的KIEval框架,通过知识基础的交互式评估,克服了数据污染的影响,更全面地评估了模型在知识理解和应用方面的能力。

「微调你的模型,获得比GPT-4更好的性能」不只是说说而已,而是真的可操作。最近,一位愿意动手的ML工程师就把几个开源LLM调教成了自己想要的样子。

本文研究发现大语言模型在持续预训练过程中出现目标领域性能先下降再上升的现象。

人工智能(AI)在过去十年里取得了长足进步,特别是在自然语言处理和计算机视觉领域。然而,如何提升 AI 的认知能力和推理能力,仍然是一个巨大的挑战。