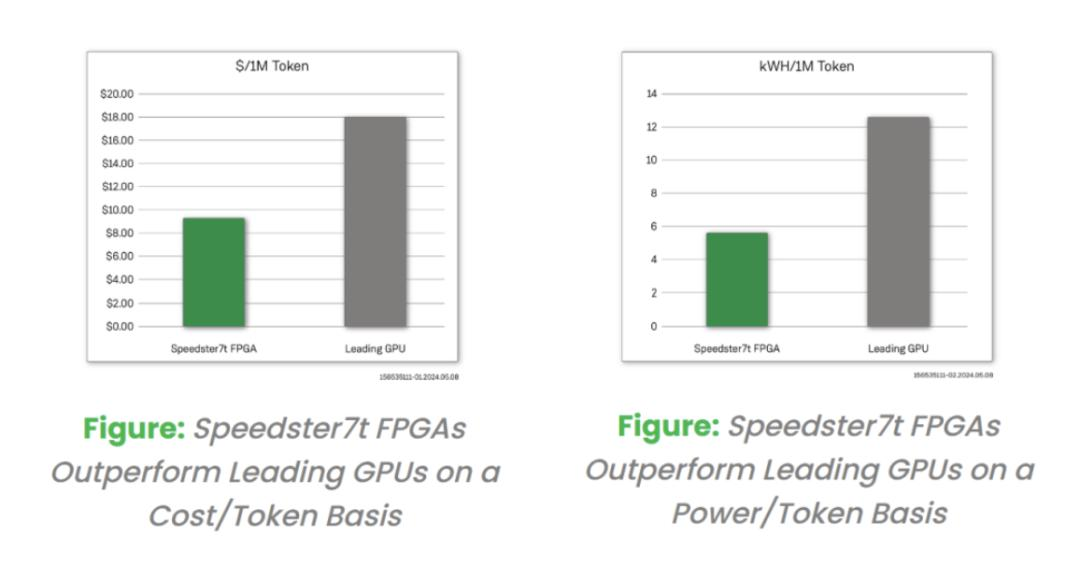
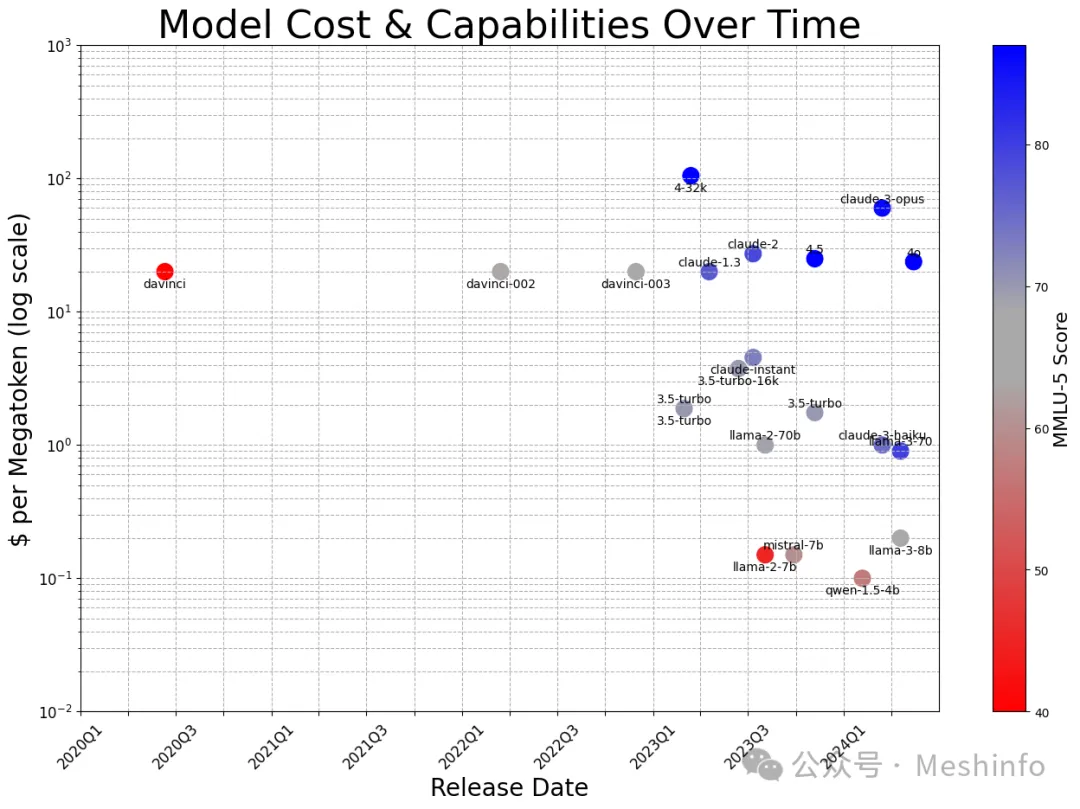
英伟达开源3400亿巨兽,98%合成数据训出最强开源通用模型!性能对标GPT-4o
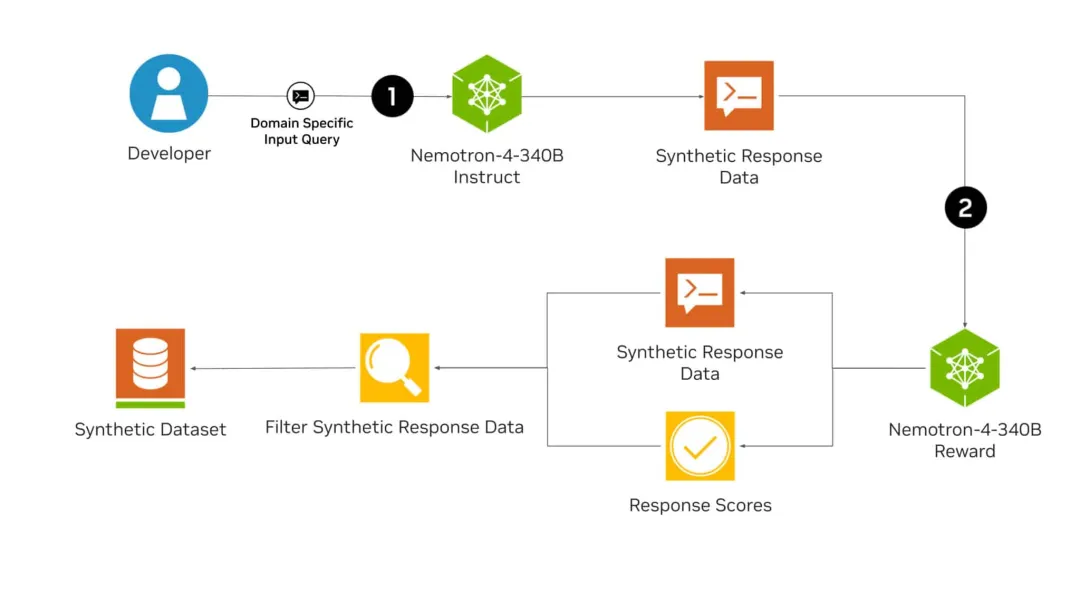
英伟达开源3400亿巨兽,98%合成数据训出最强开源通用模型!性能对标GPT-4o刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4掰手腕!
来自主题: AI技术研报
6386 点击 2024-06-15 15:58