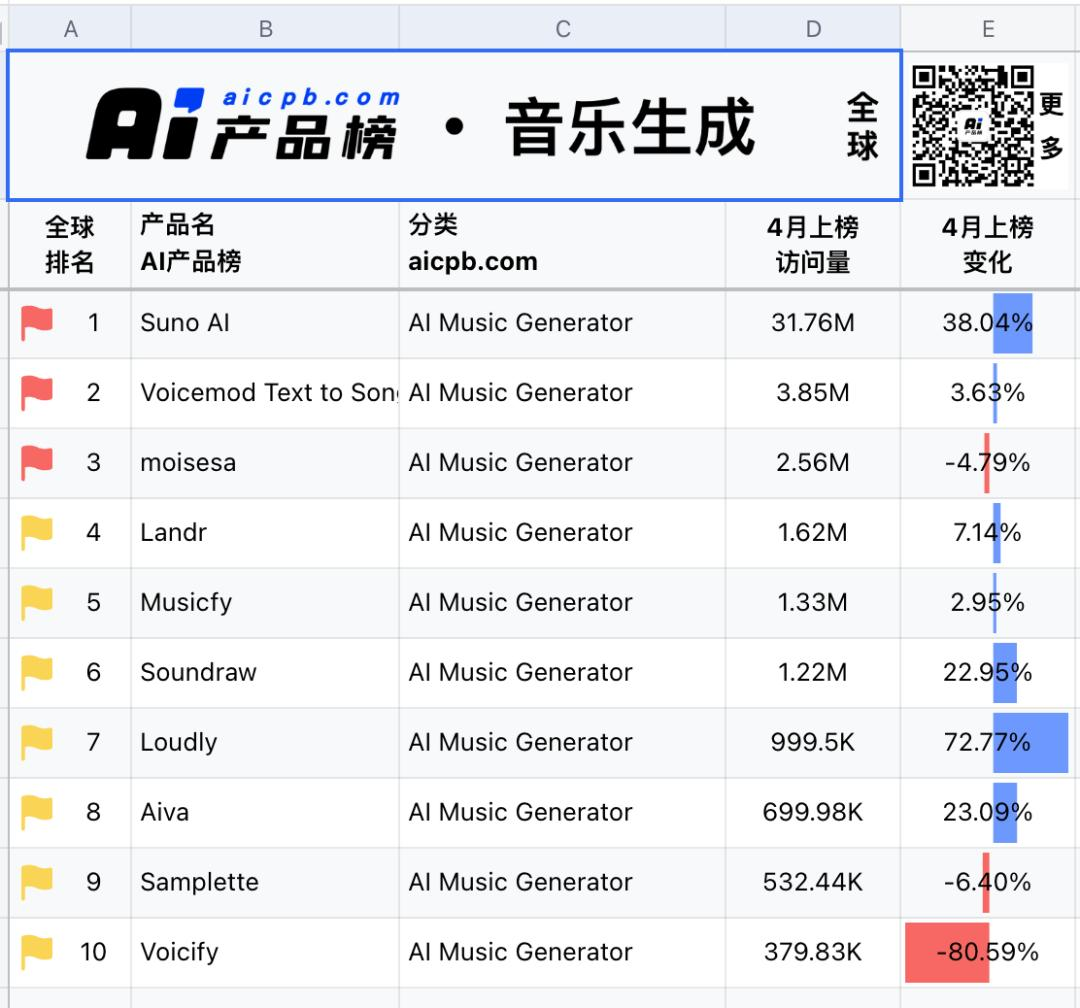
音乐的门槛,又一次被AI拉低了
音乐的门槛,又一次被AI拉低了第一批AI音乐的听众群,正在Suno的社区中被培养出来。
来自主题: AI资讯
10759 点击 2024-06-01 17:48
 搜索
搜索
第一批AI音乐的听众群,正在Suno的社区中被培养出来。

以科技伦理视角,应对不确定性的底线。

即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。

由业内大佬Amnon Shashua创立的Mentee Robotics,突然放出大招,将AI的能力嵌入到机器人的各个层面,实现了与世界的动态交互。

Aya23在模型性能和语言种类覆盖度上达到了平衡,其中最大的35B参数量模型在所有评估任务和涵盖的语言中取得了最好成绩。

在LLM能力突飞猛进的当下,所有研究者似乎都在关注数据、算力、算法等模型开发的各个方面,但OpenAI研究员Jason Wei最近发布的一篇博客文章提醒我们,模型评估的工作同样非常重要。如何开发出优秀的评估测试,对AI能力的发展方向至关重要。

斯坦福大学的研究人员研究了RAG系统与无RAG的LLM (如GPT-4)相比在回答问题方面的可靠性。研究表明,RAG系统的事实准确性取决于人工智能模型预先训练的知识强度和参考信息的正确性。
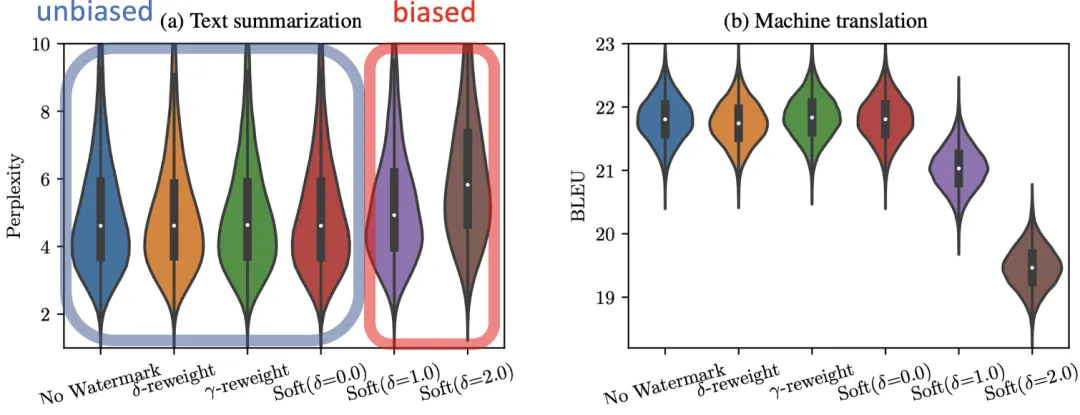
随着大语言模型(LLM)的快速发展,其在文本生成、翻译、总结等任务中的应用日益广泛。如微软前段时间发布的Copilot+PC允许使用者利用生成式AI进行团队内部实时协同合作,通过内嵌大模型应用,文本内容可能会在多个专业团队内部快速流转,对此,为保证内容的高度专业性和传达效率,同时平衡内容追溯、保证文本质量的LLM水印方法显得极为重要。

AI 智能体的宣传很好,现实不太妙。

当火山引擎要在阿里的腹地与其贴脸开打,还有一场场硬仗等待着他。