
Llama-2+Mistral+MPT=? 融合多个异构大模型显奇效
Llama-2+Mistral+MPT=? 融合多个异构大模型显奇效融合多个异构大语言模型,中山大学、腾讯 AI Lab 推出 FuseLLM
来自主题: AI技术研报
5756 点击 2024-01-27 13:51
 搜索
搜索
融合多个异构大语言模型,中山大学、腾讯 AI Lab 推出 FuseLLM
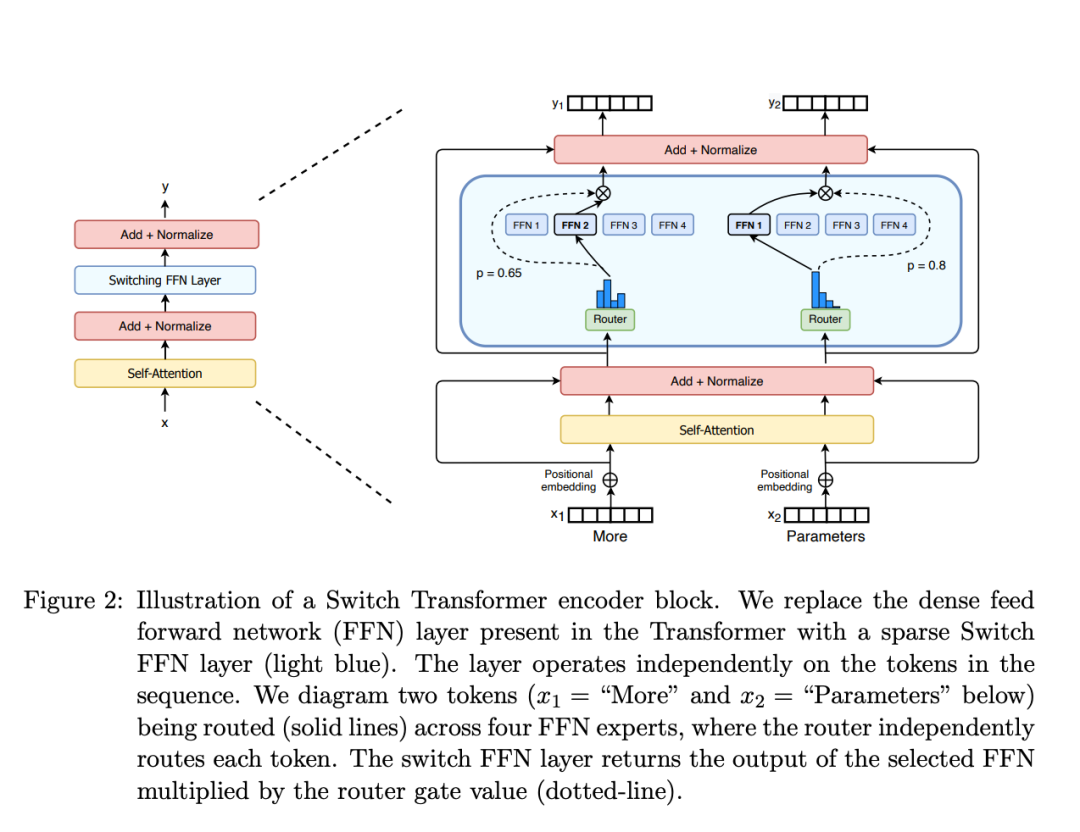
本文将介绍 MoE 的构建模块、训练方法以及在使用它们进行推理时需要考虑的权衡因素。
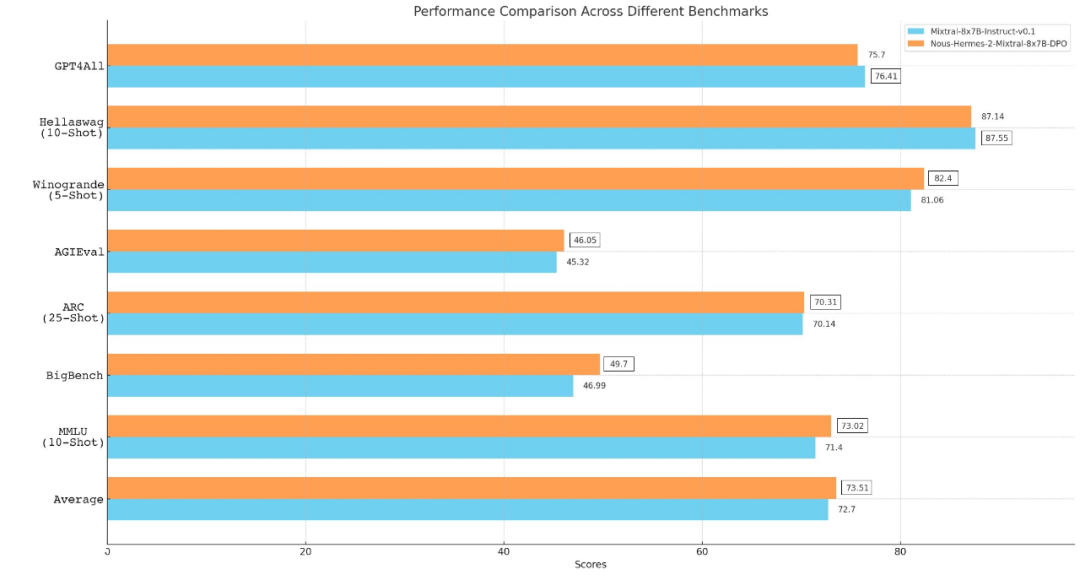
从 Llama、Llama 2 到 Mixtral 8x7B,开源模型的性能记录一直在被刷新。由于 Mistral 8x7B 在大多数基准测试中都优于 Llama 2 70B 和 GPT-3.5,因此它也被认为是一种「非常接近 GPT-4」的开源选项。

2023年,有超过10家AI初创公司接受了传统科技巨头的大额投资,不断建立并且强化了微软—OpenAI式的合作关系,甚至引发了英美两国的监管机构的关注。

爆火社区的Mixtral 8x7B模型,今天终于放出了arXiv论文!所有模型细节全部公开了。

无需微调,只要四行代码就能让大模型窗口长度暴增,最高可增加3倍!而且是“即插即用”,理论上可以适配任意大模型,目前已在Mistral和Llama2上试验成功。
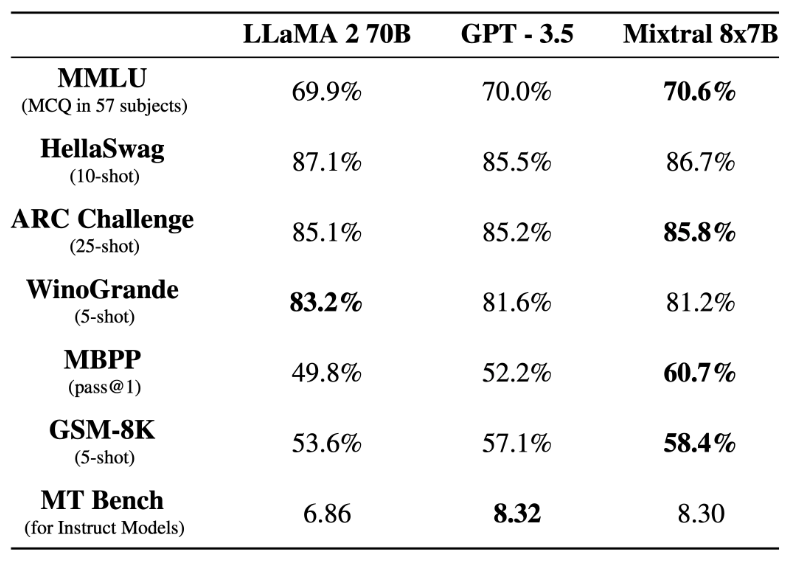
前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。

混合专家模型(MoE)成为最近关注的热点。

谷歌发布Gemini以后,一直宣称Gemini Pro要优于GPT-3.5,而CMU的研究人员通过自己实测,给大家来了一个客观中立第三方的对比。结果却是GPT-3.5几乎还是全面优于Gemini Pro,不过双方差距不大。

小模型的风潮,最近愈来愈盛,Mistral和微软分别有所动作。而网友实测发现,Mistral-medium的代码能力竟然完胜了GPT-4,而所花成本还不到三分之一。