
具身大模型LaST₀:双臂/移动/灵巧手全面新SOTA,首次引入隐空间时空思维链
具身大模型LaST₀:双臂/移动/灵巧手全面新SOTA,首次引入隐空间时空思维链LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混
来自主题: AI技术研报
7066 点击 2026-02-08 11:50
 搜索
搜索
LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混
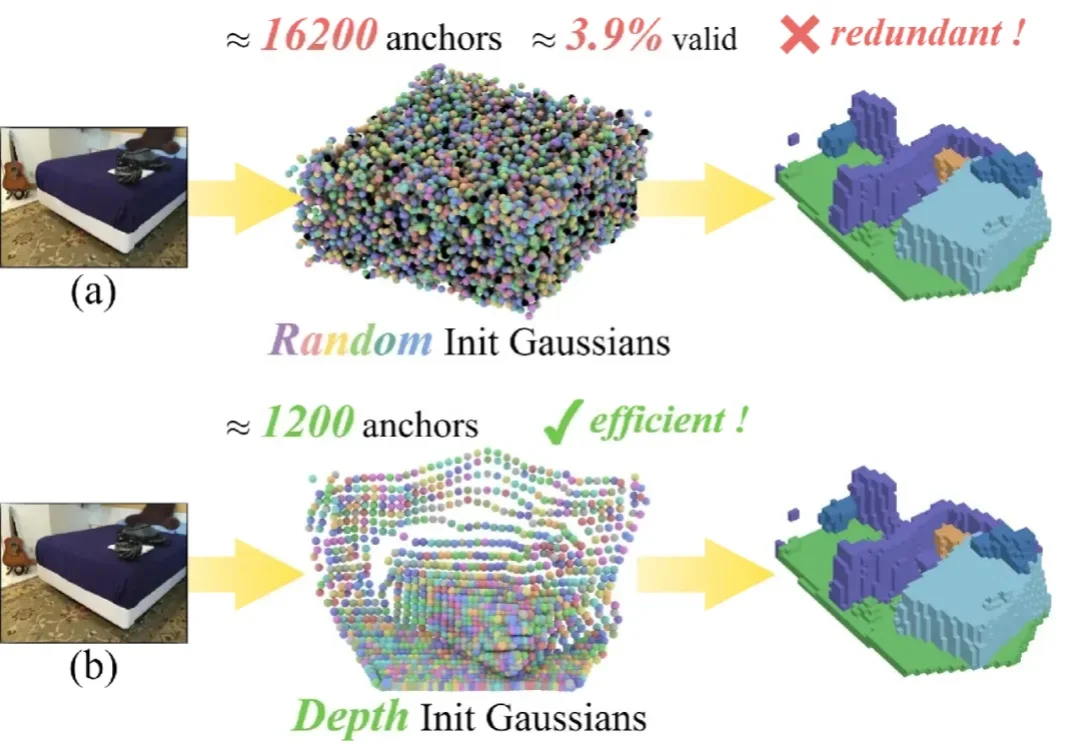
单目 3D 语义场景补全 (Semantic Scene Completion, SSC) 是具身智能与自动驾驶领域的一项核心技术,其目标是仅通过单幅图像预测出场景的密集几何结构与语义标签。

GEM框架利用认知科学原理,从少量人类偏好中提取多维认知评估,让AI在极少标注下精准理解人类思维,提高了数据效率,在医疗等专业领域表现优异,为AI与人类偏好对齐提供新思路。
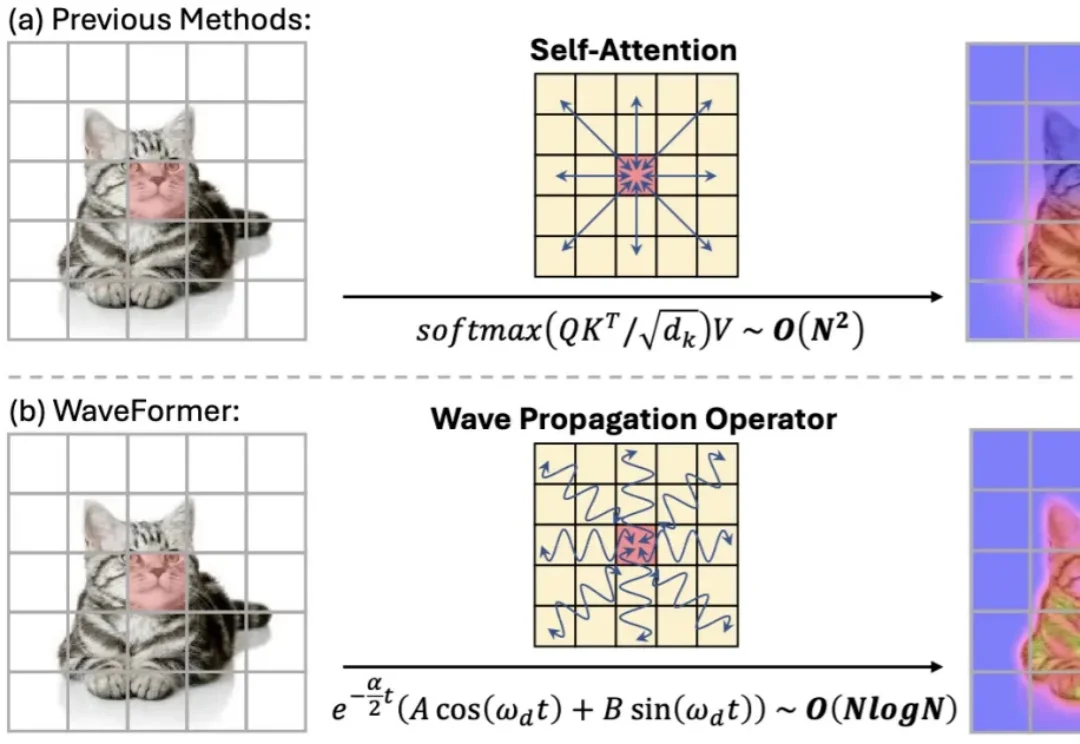
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。
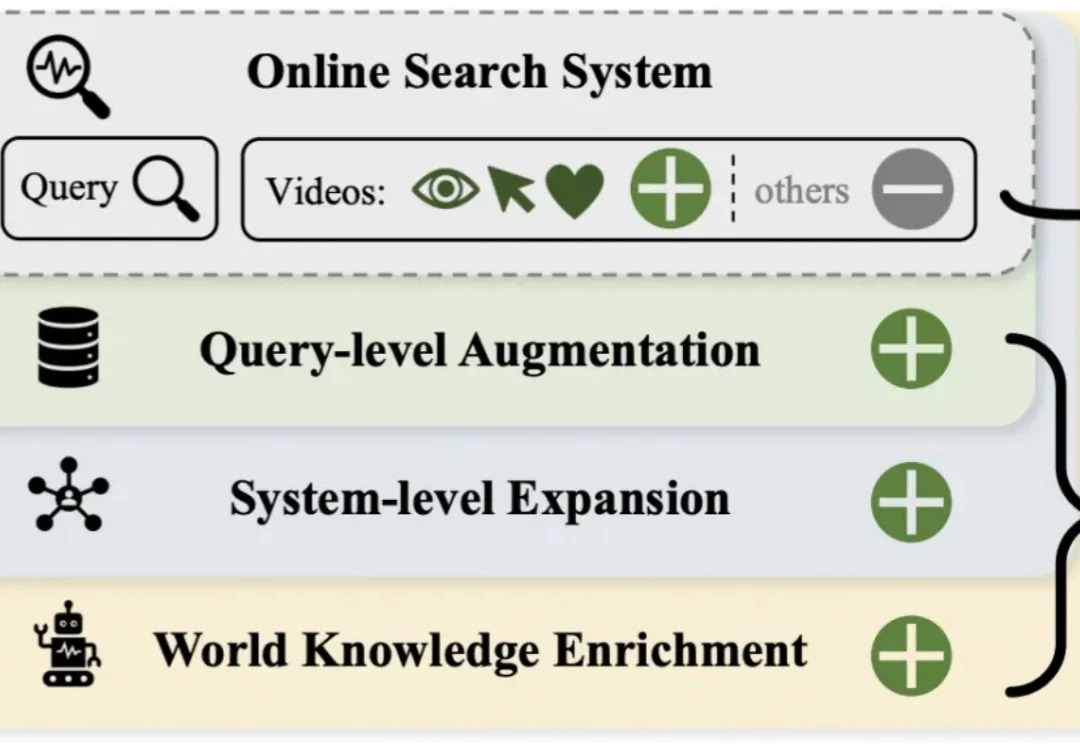
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的「自强化」训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。
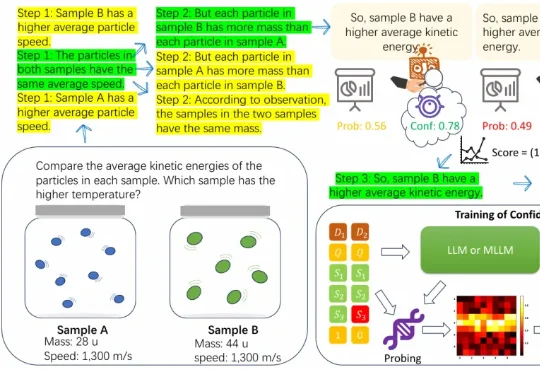
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式
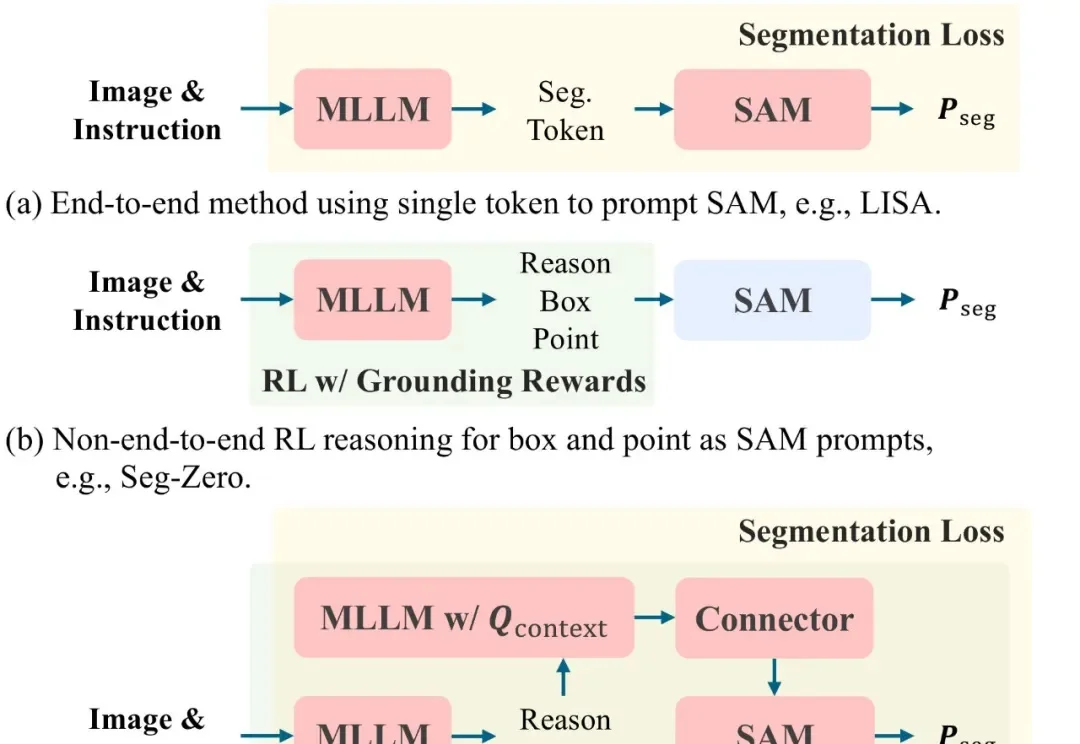
文本提示图像分割(Text-prompted image segmentation)是实现精细化视觉理解的关键技术,在人机交互、具身智能及机器人等前沿领域具有重大的战略意义。这项技术使机器能够根据自然语言指令,在复杂的视觉场景中定位并分割出任意目标。

在 SIGGRAPH Asia 2025 期间,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究

多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理?

作者在包含 50 多个任务的多个仿真和真实世界场景中评估了 SpatialActor。它在 RLBench 上取得了 87.4% 的成绩,达到 SOTA 水平;在不同噪声条件下,性能提升了 13.9% 至 19.4%,展现出强大的鲁棒性。目前该论文已被收录为 AAAI 2026 Oral,并将于近期开源。