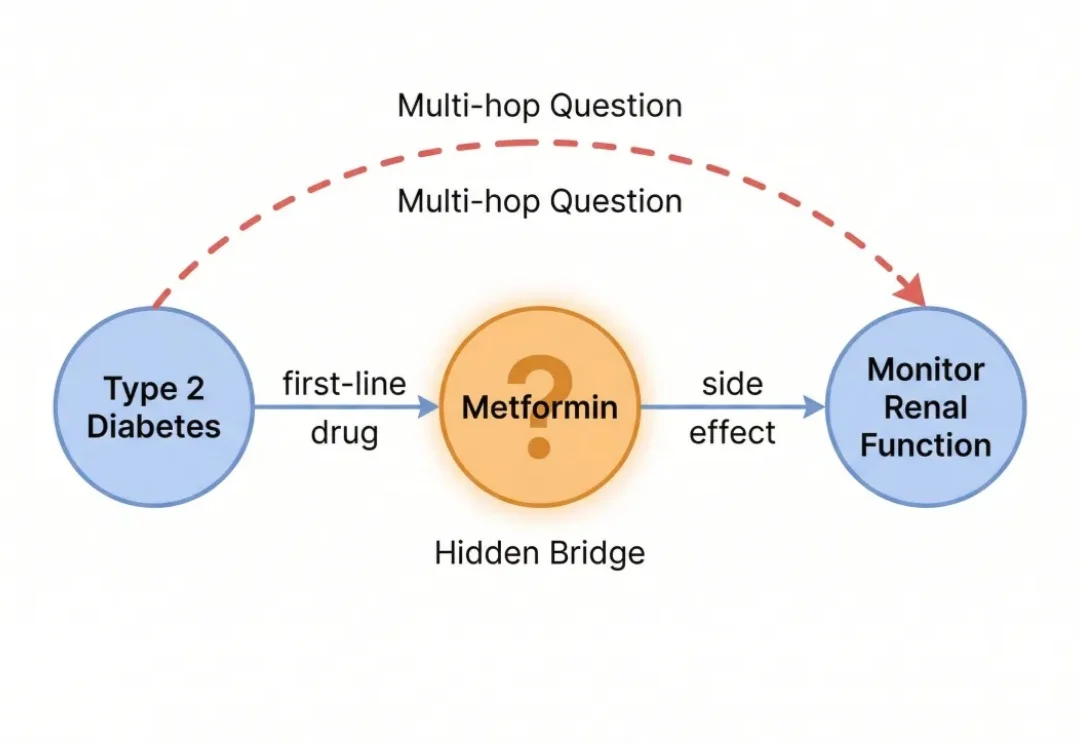
Vector Graph RAG 开源!一套向量数据库同时搞定语义检索+RAG多跳
Vector Graph RAG 开源!一套向量数据库同时搞定语义检索+RAG多跳做 RAG 多跳问答的朋友,应该没有人还没被图数据库PUA 过。
来自主题: AI技术研报
10036 点击 2026-04-23 09:23
 搜索
搜索
做 RAG 多跳问答的朋友,应该没有人还没被图数据库PUA 过。

用AI跑批量任务的人,手里基本都有一个干活的模型,不是最聪明,但要快、要便宜,稳定不出岔子。
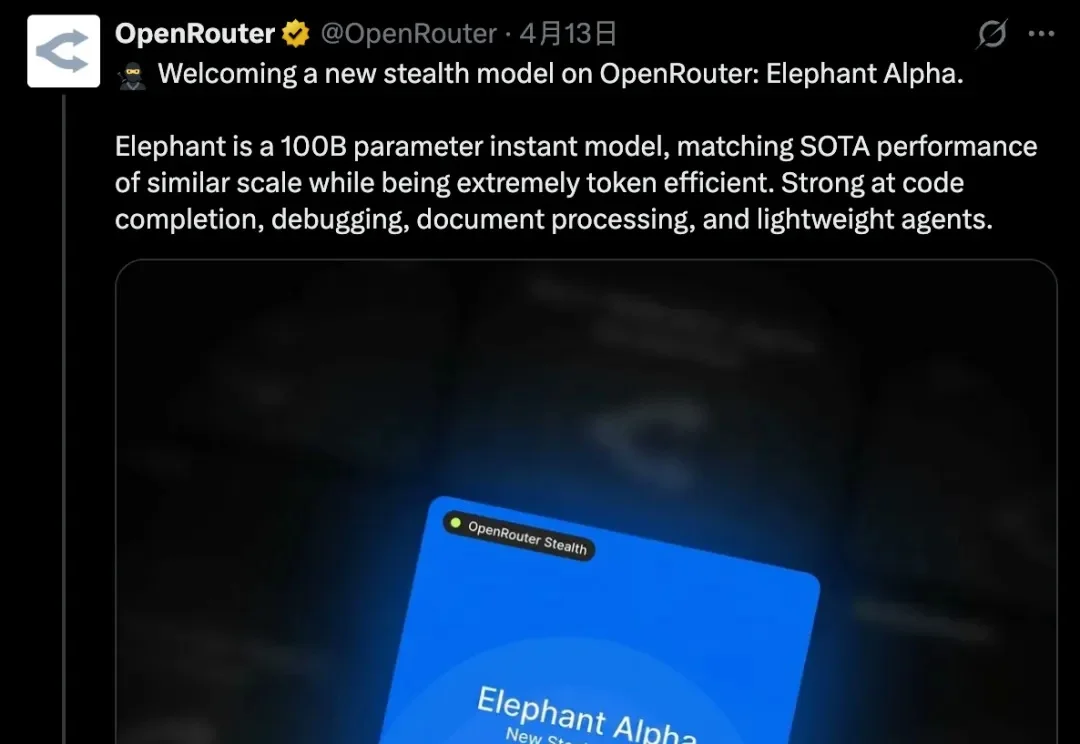
神秘模型Elephant的面纱,终于被揭开了。

AI科技评论独家获悉,卡内基梅隆⼤学机器⼈研究院(CMURI)博⼠后、悉尼⼤学(USYD)⻓聘助理教授WilliamZhi联合创办具⾝智能公司⸺ZenoAI(芝诺机器⼈),致⼒于打造通⽤全栈物理智能(Full-stackPhysicalAI),提供可靠的全⾝灵巧操作解决⽅案。

如果把今天最热门的几个方向摆在一起看,你会发现它们其实在卡同一道坎。

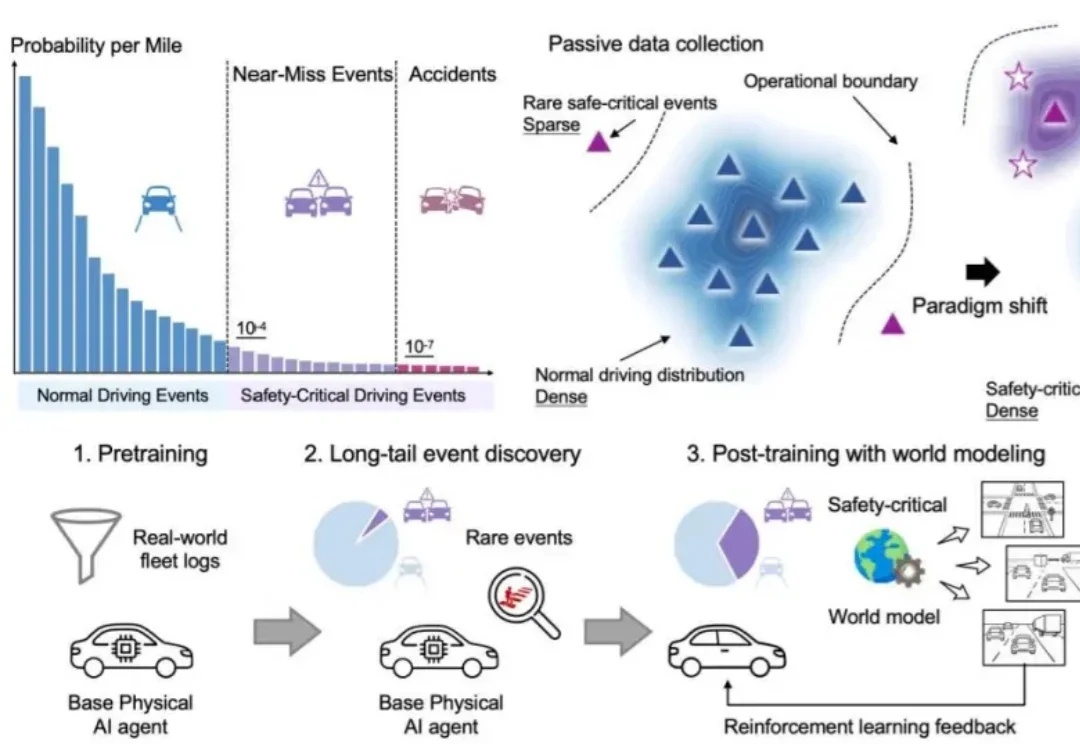
如何创建大规模的Physical AI数据,来加速Physical AI开发者的进展。我们采取的方法,本质上是用算力去换数据;
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。

4 月初,LM Arena 评测平台上出现了三个匿名图像模型,代号分别是 maskingtape-alpha、packingtape-alpha、gaffertape-alpha。几小时后它们消失了。OpenAI 官方还没有正式宣布这个模型,但根据 API 返回的元数据和用户侧的测试记录,它已经有了一个被广泛接受的名字:GPT Image 2。
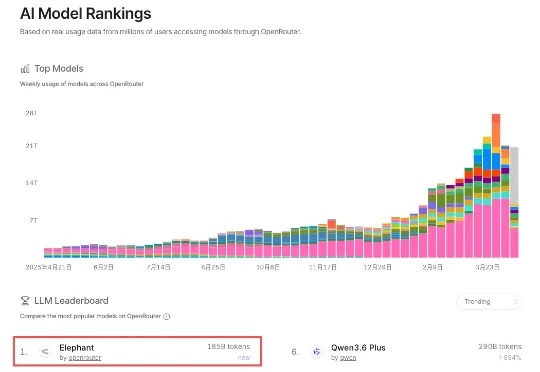
浪费的原因很具体,AI应用从“对话”转向“执行”,这些计算资源流向了较贵的大型旗舰模型,Agent在复杂多轮任务中,历史文件、对话会不断累积,大量无用、冗余、过期的信息会不断产生并且重复计算,Token消耗因此指数级增长。也就是说,企业和开发者在用最贵的车跑最短的路。
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。