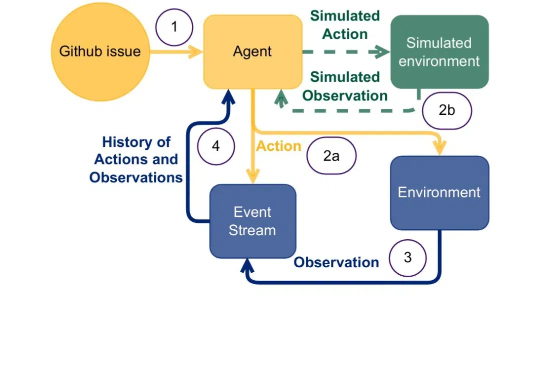
DeepSeek关键RL算法GRPO,有人从头跑通了,贡献完整代码
DeepSeek关键RL算法GRPO,有人从头跑通了,贡献完整代码GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存?有人给出了些破解方法》。
来自主题: AI技术研报
10310 点击 2025-03-02 15:14
 搜索
搜索
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存?有人给出了些破解方法》。
原来,大型推理模型(Large Reasoning Model,LRM)像人一样,在「用脑过度」也会崩溃,进而行动能力下降。

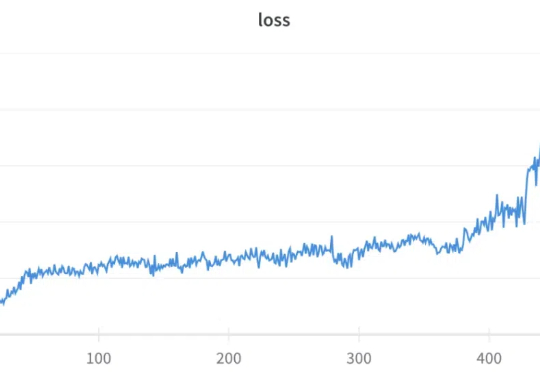
3月1日,潞晨科技官微发布了两则消息。先是宣布:“尊敬的用户,潞晨云将在一周后停止提供DeepSeek API服务,请尽快用完您的余额。如果没用完,我们全额退款。”后又发布消息:“感谢网友的热心提醒,Colossal-AI此前发布对DeepSeek-R1(671B)模型的LoRA微调,在参数加载过程中因参数名称不匹配的Bug导致Loss异常,已在GitHub线上修复。”

DeepSeek公开推理系统架构,成本利润率可达545%!明天还有更大惊喜吗?

DeepSeek和xAI相继用R1和Grok-3证明:预训练Scaling Law不是OpenAI的护城河。将来95%的算力将用在推理,而不是现在的训练和推理各50%。OpenAI前途不明,生死难料!

DeepSeek开源AI引爆全民应用潮!飞书多维表格成为最佳入门级方案,如今亚朵星球、茶百道等纷纷接入,让团队如虎添翼显著提升效率。

随着 AI 能力的提升,一个常见的话题便是基准不够用了——一个新出现的基准用不了多久时间就会饱和,比如 Replit CEO Amjad Masad 就预计 2023 年 10 月提出的编程基准 SWE-bench 将在 2027 年饱和。

DeepSeek开源周的最后一天,迎来的是支撑其V3/R1模型全生命周期数据访问需求的核心基础设施 — Fire-Flyer File System(3FS) 和构建于其上的Smallpond数据处理框架。

DeepSeek开源周,今日正式收官!内容依旧惊喜且重磅,直接公开了V3和R1训练推理过程中用到的文件系统。Fire-Flyer文件系统(简称3FS,第三个F代表File),一种利用现代SSD和RDMA网络的全部带宽的并行文件系统;

最近,英伟达开源了首个在Blackwell架构上优化的DeepSeek-R1,实现了推理速度提升25倍,和每token成本降低20倍的惊人成果。同时,DeepSeek连续开源多个英伟达GPU优化项目,共同探索模型性能极限。