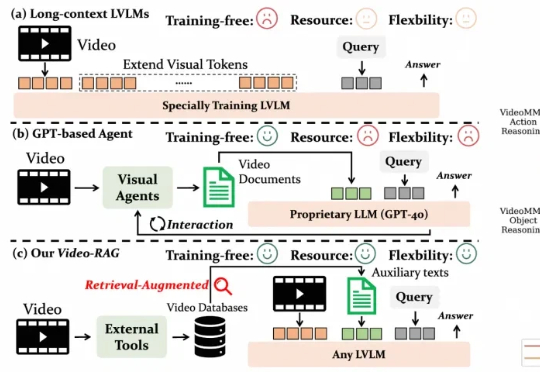
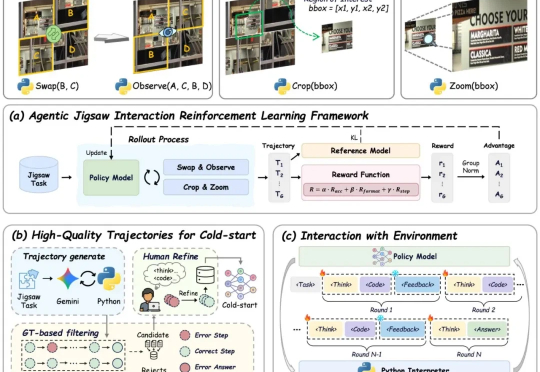
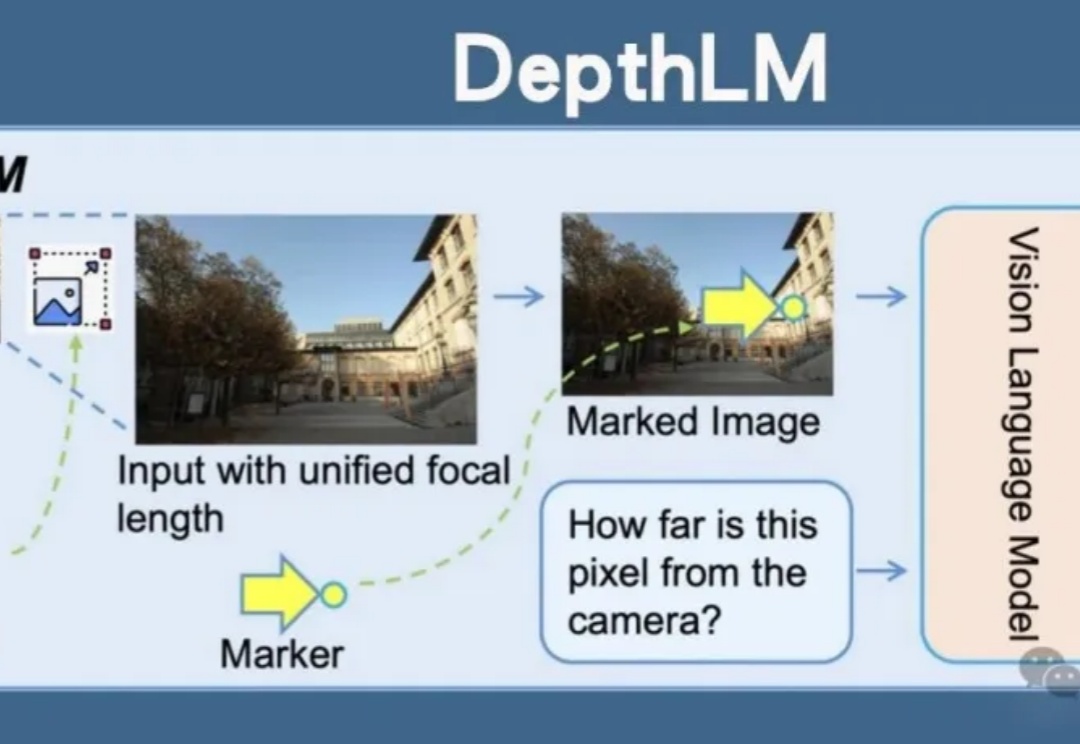
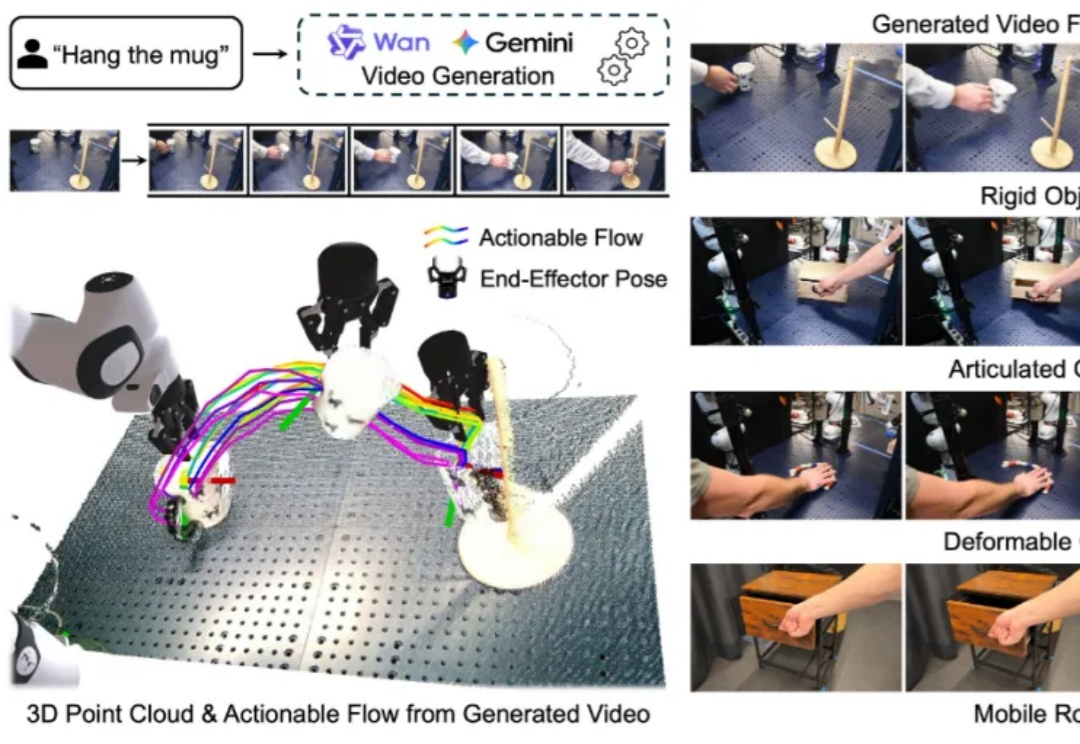
让VLM学会「心中有世界」:VAGEN用多轮RL把视觉智能变成「世界模型」推理机器
让VLM学会「心中有世界」:VAGEN用多轮RL把视觉智能变成「世界模型」推理机器当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。
来自主题: AI技术研报
8285 点击 2025-10-28 09:26